摘要
Web 应用程序中的许多事务都是在应用程序代码中临时构建的。例如,开发人员可能会显式地使用锁定原语或验证程序来协调关键的代码片段。我们将应用程序代码协调的数据库操作称为临时事务。到目前为止,人们对它们知之甚少。本文介绍了对临时事务的第一个综合研究。通过研究 8 个流行的开源 Web 应用程序中的 91 个临时事务,我们发现(i)每个研究的应用程序都使用临时事务(每个应用程序最多 16 个),其中 71 个扮演关键角色;(ii)与数据库事务相比,临时事务的并发控制更具灵活性;(iii)临时事务容易出错——其中 53 个具有正确性问题,其中 33 个由开发人员控制;(iv)临时事务通过利用访问模式等应用程序语义来提高争议工作负载的性能的潜力。基于这些信息,我们讨论了临时事务对数据库研究界的影响。
INTRODUCTION
今天,web 应用程序通常使用数据库系统来持久化大量数据,因此需要协调并发数据库操作以正确性。一种常见的方法是使用数据库事务。Transactions 通过将并发数据库操作封装成单独的工作单元来隔离并发数据库操作。另一种广泛采用的方法是使用对象关系映射(ORM)框架提供的不变验证 API(例如,来自 Active Record [98] 的验证关键字)。使用这样的 API,开发人员在应用程序代码和 ORM 框架中明确指定不变量,例如列值的唯一性报告不变违规的错误。到目前为止,已经做了很多工作来研究和改进这两种方法[8,9,25,31,39,65,66,79,97,117,118,122]。
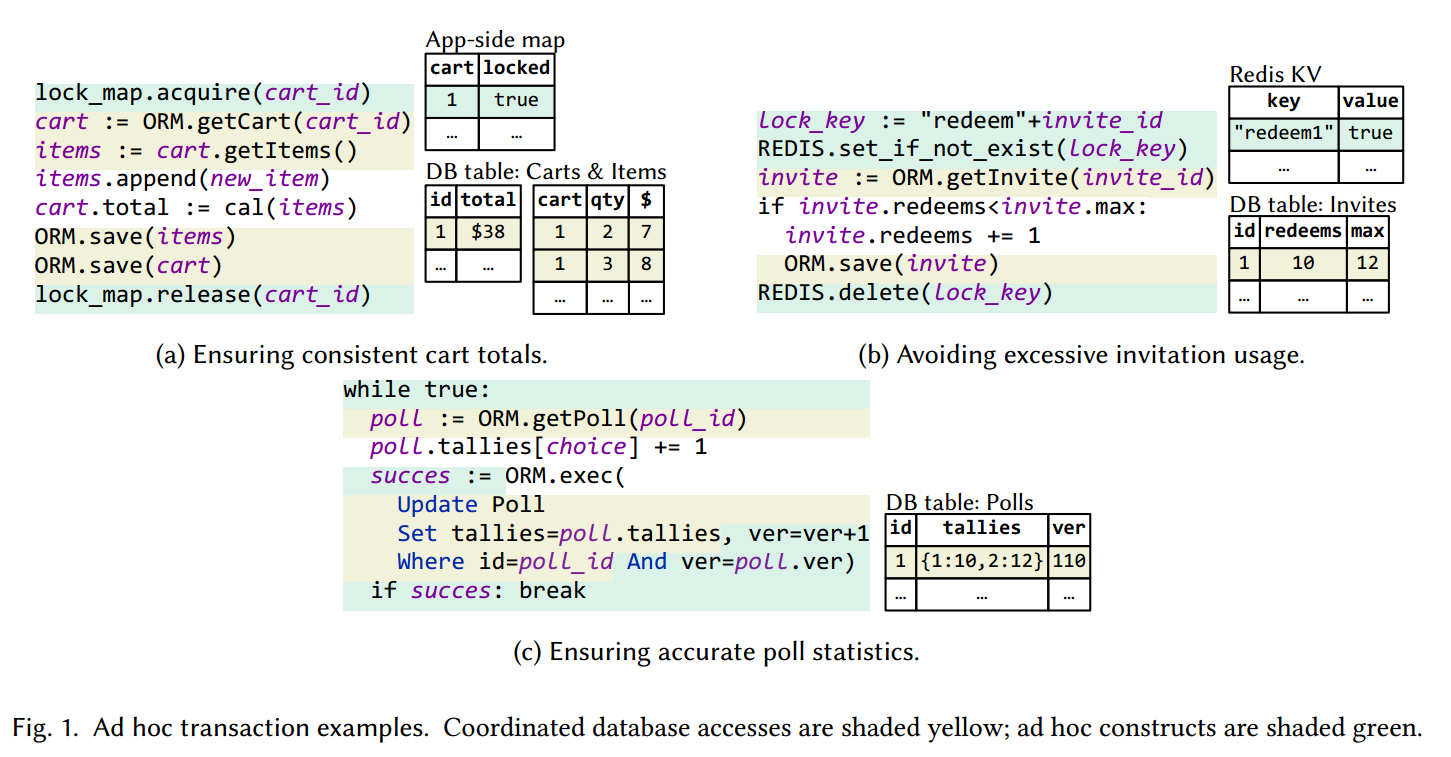
然而,除了这些方法之外,应用程序开发人员还习惯于特别协调关键的数据库操作。具体来说,开发人员可能会显式地使用锁定原语和验证程序来实现并发控制(CC),例如,在应用程序代码中乐观并发控制(OCC),以协调关键数据库操作。我们将数据库操作的这种特别协调称为临时事务。开发人员的评论表明,他们实现了可词汇化或效率的临时事务[24]。
图 1 显示了开源 Web 应用程序、Broadleaf [18]、Mastodon 106 和 Discourse [21] 的三个真实临时事务示例。在每个示例中,应用程序代码使用 ORM 框架来发出数据库操作,并使用 ad hoc 构造来协调它们。前两个直接使用锁进行协调,第三个实现类似于 OCC 的基于验证的协议。如示例所示,临时事务通常与业务逻辑相结合,从而为彻底的调查带来困难。因此,很少有关于临时事务的研究。它们在 Web 应用程序中的作用及其特征都没有明确理解。
我们在电子商务、社交网络、论坛、项目管理、访问控制和供应链管理等各种类别的 8 个 Web 应用程序中对 91 个临时事务进行了全面研究(表 2)。这些应用程序由 GitHub 星测量,GitHub 星是各自类别中最受欢迎的,并使用不同的 ORM 框架(Hiberate [100]、Active Record [98] 和 Django [30])以不同语言(Java、Ruby 或 Python)开发。我们的研究旨在了解现有 Web 应用程序中临时事务的特征及其含义。奇怪的是,我们揭示了以下有趣的、令人担忧的和感知的信息。
- 每个研究的应用程序都在关键 API 上使用临时事务。具体来说,71/91 个临时事务位于研究 Web 应用程序中的关键 API(表 3)。例如,在 3 个电子商务应用程序中有 37 个临时事务。31 个临时事务处于关键 api 中,如检查、支付和添加操作,以协调关键数据(如用户信用)。
- Ad hoc 事务的用法和实现比数据库事务更具灵活性。例如,它们可以执行仅与数据库事务具有挑战性的协调,如果不是不可能的话,例如部分协调(22 个案例)、跨请求协调(10 个案例)和异构后端的协调(8 个案例)。此外,开发人员可以利用领域知识进行优化,例如调整协调粒度以增加并行性(14 个案例)并减少所需的锁数量(58 个案例)。
- 临时事务很容易出错。临时事务的灵活性是有代价的——53 例临时事务存在并发错误,其中 28 例甚至导致了严重的现实后果,例如向客户收取过高费用。虽然考虑到临时事务实现的多样性,如此大的比例似乎并不令人惊讶,但我们的研究是第一个对这种现象进行详细分析的研究。例如,我们发现 11 个案例存在多个问题,需要独立修复。在所有问题中,不正确的原语实现(例如锁)是最常见的原因(47 例)。我们已向开发者社区提交了 20 份问题报告(涵盖 46 个案例);其中 7 起(涉及 33 起案件)已得到确认。
- 在高争用工作负载下,临时事务可以带来性能优势。使用访问模式等应用程序语义,可以以简单而精确的方式实现临时事务的 CC。因此,它们可以避免高争用工作负载下的错误冲突。例如,临时事务可以利用访问列的知识来使用列级锁进行协调,通过避免内容行上的错误冲突,与行级锁定相比,可以实现高达 1.3 倍的 API 性能改进。
临时事务的流行及其独特特征表明改进支持这些应用程序的现有数据库系统的潜力。最后,我们讨论了我们对未来数据库和存储系统研究的影响。
BACKGROUND AND MOTIVATION
Concurrency Control in Web Applications
今天,Web 应用程序通常使用独立的关系数据库管理系统(RDBMS)来管理和持久化数据,以便开发人员可以专注于编写业务逻辑。由于 Web 应用程序以面向对象的语言显着编写,因此大多数应用程序在 Hiberate 100 和 Active Record [9,8] 等 ORM 框架的帮助下操纵关系数据。这些框架可以透明地生成 SQL 语句,这些语句根据应用程序代码获取和持久数据。缺口关系数据表示为内存、应用程序运行时对象,我们将其称为 ORM 映射对象。此外,ORMs 还提供接口来帮助开发人员协调并发数据库访问:数据库事务 API 和不变验证 API。
ORM 框架通常允许开发人员显式地使用数据库事务,接口直接转换为事务启动、提交和中止语句。开发人员使用它们将多个数据库操作封装成工作单元,数据库系统负责协调。此外,ORM 框架还允许开发人员混淆特定事务的隔离级别。然而,大多数 Web 应用程序使用数据库系统的默认隔离级别 [119]。
除了数据库事务外,ORMs 还提供了内置的不变验证 api。例如,Active Record[98] 提供验证和关联关键字,例如 validate 和 distribute_to。开发人员使用它们在应用程序代码中使用它们显式指定不变量,例如列值的唯一性和相关行的存在。活动记录检查数据库写入上的不变量并报告违规错误。检查通常是通过检查从数据库系统中提取的待分散 ORM 映射对象和相关行来完成的。

不变量验证(Invariant Validation)与数据库事务(DB Transactions)不同。后者根据给定的隔离要求协调每个数据库操作;前者通过直接检查数据库状态来仅防止指定的无效结果来处理并发性。
CC 共有三种方法:不变量验证、数据库事务和临时事务。本文重点关注第三种。
Existing Studies on Concurrency Control in Web Applications
研究人员研究了数据库支持的 Web 应用程序如何处理并发性(表 1)。这些作品和我们的工作之间的主要区别在于正在研究的协调方法。Bailis 等人[9]研究了 feral CC-ORM 不变量验证 api,Warszawski 和 Bailis[119]研究了数据库事务,而这项工作针对的是第三种不那么模块化(less modular)的方法,即临时事务。因此,我们检查不同的方面并得出了新的有趣的信息。
具体来说,Bailis 等人。研究了 Rails [99] 应用程序如何采用不变验证 API 来处理并发性,并分析了这种方法的合理性。他们发现应用程序级别的不变验证比数据库事务更频繁地使用。此外,在不变一致性[8]理论下,他们发现大多数验证都是健全的,即即使在使用弱隔离级别(如 Read Committed)的并发执行下,它们也能保持不变量,而其余的则不是。同时,Warszawski 和 Bailis 专注于网络电子商务应用程序中数据库事务使用的正确性。他们分析了 SQL 日志以识别可能违反应用程序不变量的非串行 API 执行。通过手动检查潜在的违规行为,他们确定了由无效隔离级别和不正确的事务范围引起的 22 个错误。
相比之下,我们检查了临时事务的特征(第 3 节)、正确性(第 4 节)和性能(第 5 节)。我们相信我们的结果补充了 Bailis 等人在理解应用程序级 CC 方面的结果,并可能有利于 Warszawski 和 Bailis 的方法,因为临时事务由应用程序级构造组成,这些构造不能被 SQL 日志捕获,从而导致他们的方法的错误冲突[119,§3.2]。
Ad Hoc Transactions in the Wild
除了数据库事务和 ORM 提供的不变验证之外,我们还在 Web 应用程序中观察到了第三种 CC 方法——临时事务。如图 1 所示,与数据库事务一样,临时事务也为数据库操作提供隔离语义,例如可串行化。不同之处在于临时事务与应用程序代码协调操作——设计和实现 CC 的是应用程序开发人员,而不是数据库开发人员。更具体地说,临时事务是访问共享状态以执行业务逻辑的应用程序代码片段,同时还负责协调它们自己的执行。这种协调包括决定是否执行某些操作以及何时执行它们。例如,在图 1a 中,API 处理程序共享 lock_map 对象,用于确定何时执行将商品添加到用户购物车的数据库操作,而在图 1c 中,ver 字段确定是否可以执行轮询结果更新。ORM 的不变验证 API 和临时事务都在应用程序级别运行。然而,不同之处在于它们如何确保正确性。前者着眼于数据库状态是否违反不变性;后者直接隔离并发数据库操作。例如,图 1a 和 1b 使用锁来隔离冲突操作,例如同一购物车的并发读取和写入。同样,图 1c 使用版本检查来检测冲突的更改并确保读取、修改、写入 (read-modify-writes,RMW) 是原子的。相比之下,通过 ORM 的不变验证,这些冲突的访问可以自由地交错;仅当数据写回 RDBMS 时才会检查应用程序不变量,例如总域的非负性。

为了了解临时事务在 web 应用程序中的角色和关键性,我们研究了 6 个类别的 8 个代表性应用(表 2)。它们是每个类别 1 中最流行的 Web 应用程序,并在具有不同 ORM 框架的不同语言中开发。例如,Broadleaf [18] 是 GitHub 上排名最高的 Java 电子商务应用程序,Spree [113] 是 Ruby 中最流行的电子商务应用程序。我们通过首先包含我们已经基本理解的网络应用程序来构建应用程序语料库,其中包括 Broadleaf、Spree 和 SCM Suite。然后,我们使用上面提到的语言-ORM 组合扩展了 GitHub 上列出的顶级星化应用程序的语料库。在第二阶段,我们跳过了属于同一类别的应用程序(diaspora* [29])、当时没有积极维护的应用程序(Reinery CMS[104] 和 Huginn [57]),以及过于复杂的应用程序,无法完全理解(GitLab [41])。需要注意的是,这里没有涵盖的类别有更多 star 的应用(例如,博客)。尽管如此,我们相信我们的选择非常具有代表性,以产生合理的通用性。为了定位临时事务,我们首先在代码库、提交历史和问题跟踪器中搜索 lock、concurrency 和 consistency 等关键字。然后,我们手动识别隔离数据库操作的协调代码以及这些操作的目的。
Finding 1. Every studied application uses ad hoc transactions. Among the 91 ad hoc transactions in total, 71 cases are considered critical to the web applications.
发现 1. 每个研究的应用程序都使用临时事务。在总共 91 个临时事务中,有 71 个案例被认为对 Web 应用程序至关重要。

表 3 显示了关于临时事务的临界性的研究结果。对于电子商务应用程序,如果临时事务驻留在其核心 api(如结帐和添加购物车)中以确保安全购物,我们认为它是关键的。
例如,一个特别的事务可以协调读写优惠券数据,以避免过度使用优惠券。
在三种流行的电子商务应用程序 Broadleaf[18]、Spree[113]和 Saleor[108]中,总共有 37 个临时事务,其中 31 个是关键事务。具体来说,13 个案例确保只有在库存数量足够的情况下才接受订单,5 个案例避免了不一致的付款捕获。有趣的是,所有这些应用程序都有特别的事务,以确保足够的库存数量和优惠券有效性。表 3 列出了其他应用程序的核心 api。
考虑到它们在 web 应用程序中的重要性,我们进一步研究临时事务以回答以下问题。
- 如何在应用程序代码之间构建临时事务?(第 3 节)
- 临时事务是否总是正常工作?
- ad hoc 事务的性能如何,特别是与数据库事务相比(Section 5)?
CHARACTERISTICS OF AD HOC TRANSACTIONS
我们仔细研究了 91 个已确定的特别事务案例。一个有趣但并不令人惊讶的发现是,即使开发人员以各种方式实现临时事务,这些情况仍然可以分为悲观临时事务(65/91)和乐观临时事务(26/91)。在悲观的情况下,开发人员显式地使用锁来阻止临时事务中的冲突数据库操作。这种方法类似于现有数据库系统常用的两阶段锁定(2PL)及其变体[36,40,43,58,64,75,77,102]。
与数据库事务不同,悲观临时事务的锁原语通常由应用程序开发人员从头实现(例如,图 1a 和 1b)或由其他系统提供(参见 3.2 节)。
同时,乐观的临时事务积极地执行操作,并在将更新写回数据库系统之前验证执行结果(图 1c)。这种方法类似于现有数据库系统中使用的 OCC 及其变体[55,56,61,79,101,117]。
虽然临时事务可以直接分为悲观事务和乐观事务,但是它们在用法和实现方面有明显的不同。具体来说,
- 临时事务如何融入并协调业务逻辑?
- 他们的中心是如何设计和实施的?
- 它们的配合粒度是什么?
- 他们如何处理失败?

考虑到这些问题,我们将检查临时事务,并将其与数据库事务进行比较,以获得进一步的见解。为了进行比较,我们考虑了 MySQL 8.0.25 和 PostgreSQL 13.5 的数据库事务,这两个最流行的开源 RDBMS[26]与应用程序兼容(表 2)。
What Do Ad Hoc Transactions Coordinate?
在编写临时事务时,开发人员明确地在业务逻辑中放置临时协调构造。这种方法使他们能够灵活地选择协调哪些操作以及如何协调操作,从而实现部分协调、跨 HTTP 请求协调以及与非数据库操作的协调。
Finding 2. Among the 91 ad hoc transactions studied, 22 only coordinate a portion of database operations in their scopes, and 10 coordinate operations across multiple requests. Besides, 8 cases coordinate database operations along with non-database operations.
发现 2. 在研究的 91 个临时事务中,22 个仅协调其范围内的部分数据库操作,10 个跨多个请求协调操作。此外,还有 8 个案例将数据库操作与非数据库操作协调起来。
All Database Operations vs. Specific Database Operations

由于特定事务的协调是由应用程序开发人员明确编写的,因此开发人员只能协调特定的数据库操作,而不能协调事务范围内的所有操作。考虑图 2 中所示的 Spree 电子商务应用程序[113]的示例。此事务处理客户订单。它首先从 SKU 表中获取库存单位(SKU)数据,检查并更新 SKU 的库存数量,然后通过调用 ORM.save() 方法将更改持久化到数据库系统。ORM.save() 自动启动一个数据库事务,在其中它发出三个更新和一个查询(第 8-13 行)。此事务在 RDBMS 的默认隔离级别(MySQL 默认为 RR,PostgreSQL 默认为 RC)中运行。第一次更新会更改 SKU 表中的数量,其他更新会刷新相应“产品”和“类别”行的 update_at 时间戳。类别行是通过查询 ProductCategories 表来识别的,该表对产品和类别(categories)之间的多对多关系进行编码临时事务实现。其他操作,如产品和类别更新(第 9 行和第 13 行),不需要协调,但仍在锁定范围内,因为应用程序级 ORM.save() 调用会自动生成它们。
在本例中,用显式的事务启动/提交替换 lock()/unlock() 原语可能会降低性能,因为所有更新都将在相同的隔离级别下执行。对于显式事务,ORM.save() 不会启动嵌套事务或创建保存点。相反,显式外部事务将执行其查询和更新操作。我们首先考虑 MySQL 的性能问题,它是 Spree 支持的 RDBMS 之一(表 2)。在这里必须使用可序列化隔离,因为所有 MySQL 的非序列化隔离级别都会由于 RMW 对 sku 的操作而导致更新丢失[73,§7.3.3.3]。不幸的是,当两个 Serializable 事务在第 10 行获得相同 Categories 行的读取器锁后,试图在第 13 行升级到写入器锁时,它们会死锁。然而,对于临时事务,只有关键的 sku 操作被序列化,并且类别访问在 MySQL 的默认隔离级别 Repeatable Read 中执行,这不会获得 reader 锁[83,§15.7.2.3]。
除了 MySQL,其他数据库系统也可能有类似的问题。考虑使用 PostgreSQL 来支持 Spree,在这个例子中,Repeatable Read 是最弱的可用隔离级别,可以避免 sku 上的更新丢失。PostgreSQL 实现了 Repeatable Read 作为快照隔离的别名。当并发事务更新不同的 sku 但相同的 Categories 行并导致 write-write 冲突时,PostgreSQL 将根据快照隔离的第一个提交者获胜属性终止事务[15]。相反,临时事务的 orm 生成的类别访问是在 PostgreSQL 的默认隔离级别 Repeatable Read 下执行的,在这种隔离级别下,写入冲突不会导致中断[49,§13.2.2]。
理想情况下,开发人员应该将这些时间戳更新排除在数据库事务的范围之外,或者使用数据库接口切换隔离级别[72]。但是,这两种方法都不能应用于上面的示例,因为 ORM 隐藏了此类数据库操作的生成。22 个临时事务只协调事务范围内的一部分数据库操作。其他操作不需要协调,但位于事务范围内,因为它们要么是由 ORM 自动生成的,要么是关键操作需要的。
然而,数据库事务很难提供这样的灵活性。
该例中,弱隔离级别会导致
sku更新丢失,因此只能使用 SER 隔离级别,但 SER 又容易导致死锁。因此临时事务可以灵活地只对关键的sku操作使用 SER。
Individual Requests vs. Multiple Requests

它是数据库事务跨越多个 HTTP 请求的性能反模式,引入了长期事务(LLT)。然而,10 个临时事务协调跨多个请求的数据库操作。图 3 显示了一个源自 Discourse 论坛应用程序 [21] 的示例,该应用程序编辑跨越两个用户请求的帖子。用户在第一个请求中获取帖子内容以进行本地编辑。然后,用户的编辑将应用到第二个请求中。此临时事务可确保其他并发编辑在编辑帖子时不会覆盖第一个请求读取的内容。具体来说,开发人员使用乐观的临时事务来确保帖子内容的一致性。他们将每个帖子与一个版本关联起来以跟踪更新。在更新帖子之前,临时事务通过验证版本来检查一致性(即不被覆盖)。此外,它需要使用锁来保证验证和提交的原子性。如果验证失败,当前请求处理程序将不会更新内容,从而避免覆盖其他人的更改。但是,上一个请求处理程序中的视图计数增量无法回滚。
通常,Web 应用程序会选择乐观协调而不是悲观协调来协调多个请求,以避免长时间阻塞。
跨请求的事务无法使用数据库事务处理,只能使用临时事务。
Database Operations vs. Non-Database Operations

临时事务的灵活性也体现在协调非数据库操作上。Web 应用程序可以使用多个存储系统来保存其数据。因此,需要保证不同系统之间的数据一致性。有 8 种临时事务协调数据库操作和非数据库操作的情况,例如对内存共享变量、本地文件系统和远程对象/键值(KV)存储的操作。考虑图 4 中所示的示例,该示例是根据 Mastodon 社交网络应用程序 [106] 的时间线功能进行简化的。它使用 Redis KV 存储和 RDBMS 作为后端存储。Redis 保存每个用户时间线上显示的帖子 ID,而具体帖子内容则驻留在 RDBMS 中。为了保证正确性,Mastodon 必须保证 RDBMS 中的帖子内容与 Redis 中的帖子 ID 的一致性。具体来说,Redis 中的帖子 ID 应始终引用 RDBMS 中的帖子内容,这不能仅通过数据库事务来实现。因此,开发人员实施临时事务来协调这些操作。请注意,本例中只有帖子被锁定,因为 Redis 时间线上的操作满足交换律(commute)。
一般来说,当业务逻辑需要来自多个存储系统(包括多个 RDBMS)的数据保持一致时,替代选择是使用分布式事务,例如 WS-Atomic Transaction [80, 81] 或 XA 事务 [124]。然而,存储系统很少支持这种分布式事务协议,这需要临时事务。Dey 等人 [27, 28] 设计了一种协议 Cherry Garcia,在应用程序级别提供多个 KV 存储上的 ACID 事务。除了 KV 接口之外,它对 KV 存储提出了进一步的要求,例如设置用户定义的元数据的能力。因此,Cherry Garcia 无法直接替代临时事务,因为其他访问的存储系统不一定满足这些要求。
临时事务可以协调数据库操作(SQL 语句)和非数据库操作(Redis KV 操作)。
How Is Their Coordination Implemented?
开发人员需要手动协调临时事务,包括锁定(对于悲观情况)和验证(对于乐观情况)。然而,锁定原语和验证过程通常具有不同的实现。
Finding 3. There are 7 diferent lock implementations and 2 validation implementations among the 8 applications we studied. Except for Broadleaf, developers consistently use the same lock/validation implementation in individual applications.
发现 3. 我们研究的 8 个应用程序中有 7 种不同的锁实现和 2 种验证实现。除了 Broadleaf 之外,开发人员在各个应用程序中始终使用相同的锁定/验证实现。
Existing Systems' Locks vs. Hand-Crafted Locks

所有 8 个研究的应用程序都具有基于锁的悲观临时事务。他们通常使用由现有系统或开发人员自己提供的单个锁定原语实现。
四个应用程序直接使用数据库系统或语言运行时提供的锁定原语。具体来说,Spree [113]、Saleor [108] 和 Redmine [62] 使用数据库 Select For Update 语句,而 SCM Suite [33] 基于 Java 同步关键字实现临时事务。大多数商业数据库接受 Select For Update 语句,该语句以原子方式获取目标行并获取相应的写入器锁。当当前活动的事务结束时,锁将被释放。图 5 中的示例是从 Saleor 电子商务应用程序 [108] 简化而来的,其中开发人员通过 Select For Update 获取库存和库存分配的数据库锁。检查股票的充足性并应用分配后,锁定将被释放。因此,临时事务必须将关键部分包含在数据库事务中才能使用数据库锁。但是,该数据库事务可以配置为弱隔离级别,例如“已提交读”。

其他三个应用程序,Discourse [21]、Mastodon [106] 和 JumpServer [37],都从头开始实现了锁。有趣的是,它们都在 Redis KV 存储中存储锁定信息,包括锁定密钥和状态(锁定/解锁)。然而,如图 6 所示,它们的实现细节是不同的。Mastodon 开发人员使用 Redis SETNX(SET if Not eXists 的缩写)命令为请求的锁插入一个条目(图 6a)。
与比较和交换(CAS)指令类似,仅当不存在具有相同键的条目或未过期时,此命令才会成功。由于锁条目是有过期时间的,一旦过期,其他线程可能会覆盖它。为了避免意外释放其他线程获取的锁,在解锁过程中,线程需要原子地检查当前锁条目是否已被覆盖,只有在保持不变的情况下才将其删除。 Mastodon 开发人员在锁定时生成随机令牌,以区分写入相同锁定条目密钥的线程。检查和删除的原子性是通过 Redis EVAL 命令实现的,该命令接受 Lua 脚本并在其他 Redis 活动暂停的情况下执行它。相比之下,Discourse 开发人员使用 WATCH、MULTI 和 EXEC 命令的组合来乐观地确保检查现有锁和设置新锁的原子性(图 6b)。 MULTI 命令指示 Redis 开始对后续命令进行排队,而不是立即执行它们,而 EXEC 命令以原子方式有条件地执行排队的命令。 Discourse 开发人员使用这些命令来编写新的锁条目及其过期时间原子(过期时间可以作为额外参数与第一个排队的 SET 命令一起设置。目前尚不清楚为什么 Discourse 开发人员选择发出两个命令。尽管如此,仍然需要使用 MULTI 和 EXEC 来处理并发锁定)。仅当先前 WATCH 命令标记的键保持不变时,EXEC 命令才会成功。由于首先使用 GET 命令监视并读取锁定密钥,所以当 EXEC 运行时将检测到对锁定条目的任何并发更改,并且不会在冲突时执行任何排队命令。与 Mastodon 的锁实现类似单对象 CAS 指令不同,Discourse 的机制更像是 OCC 协议。因此,Discourse 的 Redis 锁需要额外 6 次往返,而 Mastodon 只需要一次 [91]。 JumpServer 像 Mastodon 一样使用 SETNX 实现锁;它还添加了可重入功能,允许同一线程多次获取锁。

Broadleaf [18] 是唯一同时使用本地锁实现和现有系统原语(Java 同步关键字)的应用程序。更有趣的是,它有三个本地实现。第一个使用专用数据库表将锁条目存储为单独的行,类似于前面提到的基于 Redis 的锁(参见图 7a)。它通过使用数据库事务来确保检查锁状态和更新锁条目之间的原子性。此外,由于数据库系统不会默默地过期(即删除)一行,因此解锁过程是一个简单的 Update 语句,用于释放相应的锁条目。其他两种实现使用内存映射来获取锁定信息,并且所使用的特定映射有所不同。一种直接使用标准库中的并发映射 ConcurrentHashMap,另一种使用自定义的 ConcurrentHashMap,其中开发人员添加了最近最少使用(LRU)驱逐策略以删除过多的锁条目。图 7b 显示了用于内存会话锁的过程,该过程构建在支持 LRU 的并发映射上。有趣的是,虽然 SESSION_LOCKS 是一个并发数据结构,但开发人员仍然必须使用 synchronized 关键字来防止线程覆盖彼此的锁条目,因为无论锁键是否存在,put 方法总是成功。我们没有发现明确的证据表明这些不同的实现有不同的目的。然而,我们确实发现不同的开发人员已经引入了这些实现。
ORM-Assisted Validation vs. Hand-Crated Validation
所研究的 8 个应用程序中有 6 个具有基于验证的乐观临时事务。它们的验证过程要么由 ORM 框架提供,要么由开发人员自己提供。

有 4 个应用程序通过特定于框架的接口使用 ORM 提供的验证过程。例如,Active Record 可识别名为 lock_version 的列,并使用它们来存储各个行的版本。每次更新时,如图 1c 所示,Active Record 会自动向 Where 子句添加版本检查,并随着用户启动的更新而增加版本,从而确保验证和提交的原子性。当使用手工验证过程时,开发人员必须确保验证和提交的原子性(个人感觉应该是隔离性,笔者注)。如第 3.1.2 节的清单所示,为此目的使用了额外的锁。 Discourse 和 SCM Suite 的乐观临时事务中的所有验证程序都是手动实现的。 Broadleaf 使用这两种实现,由不同的开发人员引入。
Remarks
不同应用程序甚至同一应用程序的原始实现也有所不同。
然而,我们没有发现任何明显的原因让开发人员更喜欢一种特定的实现而不是其他实现。我们在第 4 节中将不同的实现与不同的正确性问题联系起来,并在第 5 节中比较了它们的性能。
What Are Their Coordination Granularities?
开发人员通常对应用程序有深入的了解,因此能够定制协调粒度。直观地说,人们可能会想到比数据库事务更细粒度的协调。例如,临时事务可以在列级进行协调,只关注对特定列的访问,因为开发人员可以精确了解业务逻辑需要哪些列。这可以减少基于行的协调造成的错误冲突[38]。不过,临时事务也采用比数据库事务更粗粒度的协调。具体来说,临时事务通常会将多个访问组合在一起,用一个锁来协调它们。这可以在很大程度上降低临时事务的 CC 复杂性,避免死锁。
Finding 4. Among the 91 studied ad hoc transactions, 14 cases perform fine-grained coordination such as column-based coordination, while 58 cases perform coarsegrained operations, i.e., using a single lock to coordinate multiple operations. 9 cases implement both types of coordination for different accesses.
发现 4. 在所研究的 91 个临时事务中,有 14 个执行细粒度协调,如基于列的协调,而有 58 个执行粗粒度操作,即使用单个锁协调多个操作。有 9 个案例针对不同的访问同时执行两种类型的协调。
Single Access vs. Multiple Accesses
临时事务中的锁可以协调任意的数据库访问。根据我们的研究,有 58 个临时事务使用一个锁来协调多个数据库访问。这是因为开发人员通常可以识别以下两种访问模式。

图 1a 中的购物车程序是典型的关联访问,应用端只需要一个购物车锁就可以代替原先的多个锁。
Associated Accesses 相关访问。给定两个数据库行 r1 和 r2,如果对 r2 的访问始终发生在也访问 r1 的事务中,则我们说 r2 与 r1 关联访问,并将此访问模式称为关联访问模式。对于一对多关系(例如 is-part-of 关系)关联的行的访问通常遵循此模式。考虑 Broadleaf [14] 中的示例,如图 1a 所示。购物车由一个购物车行和多个项目行表示。当用户修改购物车时,事务将关联访问这些行。关联的访问模式提供了用协调这些访问的一个锁来替换多个锁(例如,行锁)的机会。在上面的示例中,开发人员使用单个购物车锁来协调对表、购物车和项目的访问。此锁显式地预先序列化冲突事务,从而避免使用数据库事务时潜在的中止。在 PostgreSQL 中,一个事务中的 Carts 更新会中止更新之前由于写入冲突而发生的所有冲突事务。在 MySQL 中,购物车更新和项目插入都可能形成死锁,因为这两个表可能被其他事务锁定在共享模式下。
大约有 37 个利用关联访问模式的临时事务。对于我们研究的所有案例,关联行通过一对多或一对一关系连接。我们发现这些一对多关系源于反映业务语义的特定于应用程序的数据建模,例如上面示例中的购物车和商品之间的关系。同时,这些一对一的关系来自于继承。例如,Broadleaf 使用 Bundled_Items 表来存储代表销售捆绑的商品的数据。
查询一个捆绑包项目时,会向 Items 和 Bundled_Items 表发出两个数据库操作。应该注意的是,继承可以以不同的方式实现,并且不一定引入关联的访问,例如,通过将 Items 和 Bundled_Items 表合并到一个整体表中 [63,§2.11]。

Read-Modify-Writes(RMWs)。RMW 是指事务首先从数据库系统中查询数据,然后进行相应的修改,最后将修改持久化回数据库系统。在没有足够的死锁预防机制的 2PL 系统中,例如 MySQL,如果两个并发事务在同一行上执行 RMW,则可能会出现死锁。假设两个事务都使用可序列化隔离,如果它们都成功获取了读取器锁,那么它们的更新会互相阻塞,从而导致死锁。请注意,MySQL 的非可序列化隔离级别不能防止丢失更新 [62,第 7.3.3.3 节],这需要使用可序列化。考虑图 1b 所示的示例,在论坛应用程序 Discourse [17] 中,通过邀请创建新帐户时会发出 RMW 操作。首先从数据库系统中读取邀请。检查其有效性后,它会被更新并写回数据库系统。如果两个用户同时使用同一个邀请加入论坛,很容易出现死锁,导致两个用户都无法成功。
为了缓解这种情况,开发人员设计临时事务以在第一次读取之前获取排它锁,从而避免可能的死锁。91 个案例中有 56 个利用 RMW 访问模式。其中,35 个案例也利用了相关的访问模式。
讨论。减少锁的数量可以简化实现并避免潜在的死锁。然而,此类优化很少可以在数据库系统中使用,因为它们高度依赖于应用程序语义。人们可能会考虑使用静态分析来识别这些特殊模式。但这并不是微不足道的,特别是对于检测相关的访问模式而言。这是因为需要分析每一行代码以确保这些访问始终在一起,而 Web 应用程序通常拥有庞大的代码库。例如,我们研究的应用程序平均有 160.4 k 行代码。此外,大多数应用程序使用 ORM 来隐藏数据库访问细节,使分析更具挑战性。
Fine-Grained vs. Coarse-Grained

与现有数据库系统相比,以更细的粒度进行协调的一个明显优势是避免错误冲突。我们发现临时事务的细粒度协调要么基于列,要么基于谓词。
Column-Based vs. Row-Based 基于列与基于行。 ORM 映射对象的字段对应于数据库列。如果开发人员知道使用了哪些字段,则可以按列粒度协调数据库访问。例如,在论坛应用程序 Discourse [17] 中,两个事务(创建帖子和切换答案)将发出以下访问主题表的数据库操作(图 8)。第 6 行增加 max_post 字段;第 12 行设置答案字段。尽管这些操作没有列级冲突,但如果它们访问同一行,则使用行锁的数据库系统无法并行执行它们。因此,Discourse 开发人员没有使用数据库事务,而是为这两个事务实现了两个锁命名空间,以便协调第 6 行的锁不会干扰第 12 行的锁。请注意,RDBMS 仍然串行执行第 6 行和第 12 行,以避免数据损坏。

乐观的临时事务也可以从基于列的协调中受益——它们只需要验证特定列值是否已更新。图 9 显示了 Discourse [17] 中编辑后事务的更准确表示,我们之前在第 3.1.2 节中对此进行了讨论(但是,版本列仍然存在,可以在其他 API 中使用)。它对更新的内容列执行基于值的验证以检测并发更改。对其他列的任何并发更新(包括 view_cnt 增量)都不会干扰内容更新。总的来说,有 5 个临时事务,开发人员使用列级协调来释放潜在的并行性。

Gap vs. Predicate 间隙与谓词。知道了搜索条件,开发人员可以使用精确的谓词进行协调。这可以避免主要 RDBMS [57,64,66](包括 MySQL 和 PostgreSQL)中使用的间隙锁引起的错误冲突。如图 10 所示,在 Spree [99] 电子商务应用程序中,数据库系统可能会同时执行以下代码,order_id 为 10 和 11,分别对应于事务 Txn 1 和 Txn 2 创建的两个订单。在 Txn 1 中,第 3 行检查 order_id=10 标识的订单是否存在任何付款行。由于一个订单可以有多次付款(以允许混合付款方式),因此 Payments 表的 order_id 索引不是唯一的。假设当前索引值为 9 和 12。执行 Txn 1 的第 3 行会导致数据库系统在索引区间 (9, 12) 上获取间隙锁,阻止对该范围的并发插入,以便重新执行第 3 行可以获得可重复的结果。同时,Txn 2 中的第 5 行为 order_id 等于 11 的另一个订单插入新的支付行。虽然此插入不会干扰 Txn 1 的第 3 行,但它仍然会被间隙锁阻止。更糟糕的是,这种情况在电子商务应用程序中很常见。结帐操作通常对新创建的订单执行,这些订单具有最大的 order_id。此类操作将满足一个公共间隔(从最新支付订单的 order_id 开始到无穷大的间隔),因此会相互阻塞。我们认为这些锁是谓词锁的变体[30, 49],因为它们使用访问的谓词信息(即 order_id 值)来实现精确的互斥,而不会出现错误冲突。在我们研究的 91 个案例中,有 10 个案例实现了谓词锁定以实现精确协调,全部基于相等谓词; 1 个案例同时实现了基于列的协调和基于谓词的协调。谓词锁定可以通过并发哈希表来实现,该哈希表跟踪简单相等谓词的锁定值。由于开发人员比数据库系统更了解 Web 应用程序的访问,因此他们导出定制的谓词锁定方案比数据库系统提供通用谓词锁定更实用。
Discussion 谓词锁定和列级锁定都会给数据库系统带来性能成本。对于复杂的谓词,由于决定谓词兼容性的成本,临时事务的性能优势可能会减弱。成本随着支持谓词的普遍性而增加,最终需要昂贵的可满足性模理论 (SMT) 求解器。例如,为了支持范围谓词,一种直观的方法是将所有活动范围存储在区间树中。在这种情况下,临时事务性能将取决于底层树结构的性能和可扩展性,要获得这些性能和可扩展性需要付出巨大的努力[58]。对于列级锁,主要成本是空间使用,因为每一列都需要一个锁。
How Are Failures Handled?
与数据库事务类似,临时事务应该处理运行时故障(例如死锁和验证失败)以及系统崩溃(例如数据库服务器崩溃和 Web 服务器崩溃)。
Finding 5. Ad hoc transactions typically do not have complex failure-handling logic, partly because there are fewer failure scenarios that need to be handled (e.g., the absence of deadlocks) and partly because developers seem to often assume failure-free executions.
发现 5:临时事务通常没有复杂的故障处理逻辑,部分原因是需要处理的故障场景较少(例如,不存在死锁),部分原因是开发人员似乎经常假设无故障执行。
Automated Rollback vs. Manual Rollback
我们首先考虑没有任何崩溃的故障。这些失败通常是由死锁或验证失败引起的,传统上由数据库回滚机制处理。
与提供通用的包罗万象的回滚机制的数据库系统不同,应用程序开发人员需要根据具体情况制定故障处理逻辑,就像他们如何为每个临时事务设计协调一样。
Deadlocks 死锁。对于死锁,我们没有看到任何死锁检测和处理逻辑。在悲观的临时事务中,我们发现要么使用单个锁(52/65 情况),要么以一致的顺序获取锁(13/65 情况)。因此,它们都不需要在运行时处理死锁。这同样适用于锁定乐观临时事务。另外,一些乐观的情况在验证和提交过程中不获取任何锁,这显然消除了死锁,但牺牲了正确性。我们在 4.1.2 节中讨论这些正确性问题。
TODO:这里是我们需要验证的地方。
Validation Failures 验证失败。同时,验证失败仅发生在乐观的临时事务中。我们发现有 19 个案例在验证失败时直接向最终用户返回错误,而没有保留任何更新。在其他情况下,非关键更新是在验证阶段之前发布的,这需要在验证失败时进行回滚。乐观的临时事务要么使用某些回滚方法来消除更新的影响,要么使用修复技术“前滚(roll forward)”并提交更改,如下所述。
临时事务中的回滚方法基于 (1) 数据库事务的原子性属性或 (2) 手工制作的回滚过程。有 1 例采用前一种方法。它使用具有读提交隔离的数据库事务来封装更新和验证语句。如果验证失败,将发出用户启动的中止来终止数据库事务并回滚更新。同时,有 2 个案例配备了手动编写的回滚程序。这些过程由验证失败触发,并将撤消持久更新。有趣的是,我们注意到应用程序回滚时可能并不总是撤消临时事务中所做的所有更改。例如,Broadleaf 采用临时事务来避免同一订单的并发处理,这几乎跨越了整个处理过程。如果 SKU 状态验证失败,虽然之前对付款和订单状态的更新将被撤消,但其他更改(例如对订单总价格的更新)将不会回滚。这是一个临时事务的示例,在故障处理方面具有宽松的语义,而不是像数据库事务那样具有严格的“全有或全无”原子性限制。

修复技术在 4 种情况下用于处理冲突,修复不一致的值而不是回滚整个事务。这个想法依赖于开发人员对程序依赖性的了解,并且类似于事务修复优化[21, 106]。考虑图 11 中所示的示例,该示例取自 Discourse [17] 论坛应用程序,这是一个定期后台任务,可缩小帖子中的大图像。由于多个帖子可以使用相同的图像,因此此事务可能与用户发起的帖子编辑冲突,后者仅修改单个帖子。在这种情况下,数据库系统可能会中止事务并回滚对其他未受影响的帖子所做的工作,并且应用程序必须再次执行收缩和内容替换。更好的解决方案是识别更改的帖子,仅重做内容替换,并提交图像缩小事务。
Crash Handling
我们主要关注两种类型的崩溃:(i)数据库服务器崩溃和(ii)应用程序服务器崩溃。我们排除客户端故障,例如强制关闭浏览器,因为它们对我们研究的临时事务没有影响。在我们检查的应用程序中,客户端不直接访问数据库。然而,我们注意到,随着渐进式 Web 应用程序(PWA)等技术和移动后端即服务(MBaaS)等业务模型的进步,未来的 Web 应用程序可能会将繁重的业务逻辑(部分)卸载到客户端,并启用客户端直接访问数据库系统和其他存储系统。在这种情况下,客户端故障将变得相关,并增加临时事务的设计和实现的复杂性。
Database Server Crashes 数据库服务器崩溃。当数据库服务器崩溃时,应用程序服务器端数据库驱动程序将检测连接丢失并抛出运行时异常,以通知应用程序在数据库系统恢复后执行故障处理。为了妥善处理此类故障,应用程序需要等到数据库连接重新建立,然后继续处理中断的业务逻辑或回滚,正如我们之前讨论的那样。然而,我们发现没有任何临时事务以这种方式执行错误处理;他们只是让异常传播到 Web 框架并最终向最终用户显示内部错误页面。由于未执行回滚,数据库可能会处于中间状态。我们发现,在某些情况下,临时事务可以通过预防措施容忍这种中间状态。例如,Broadleaf 中的结帐过程会为订单创建一条付款记录,而结帐期间的崩溃可能会导致该记录处于未确认状态。为了避免在用户尝试再次签出订单时创建重复的付款记录,Broadleaf 发出一条 Update 语句,将与订单关联的所有现有未确认付款记录设置为存档状态。这可确保进一步处理仅将一条付款记录视为活动状态,并且不会对该订单重复收取费用。请注意,此类预防措施的前提是开发人员必须预测并计划潜在的崩溃情况,这在实践中可能是一个困难且不完整的过程。
Application Server Crashes 应用程序服务器崩溃。但是,当应用程序服务器崩溃时,无法发出正在进行的临时事务的回滚语句。为了在应用程序重新启动后正确恢复服务,应用程序必须确保正确恢复对协调元数据和其余应用程序数据的更改。

恢复协调元数据相对容易。存储在单独的数据库列中并在乐观临时事务中使用的版本可以轻松处理。如果某个版本因未完成的临时事务而增加,则它可以简单地保留新的增加值。重新启动的应用程序服务器始终可以重新读取最新版本,并在检测到不匹配的版本时重新启动乐观临时事务。另一方面,锁可能很棘手。当应用程序服务器崩溃时,它们可能会保持锁定状态,而所有者线程会终止,这可能会导致稍后死锁。幸运的是,临时事务中使用的大多数锁元数据不会永远持续——它们要么随着崩溃而消失(内存锁),要么在给定时间段后过期(Redis 锁)。 Broadleaf [14] 中有一种例外情况,它使用持久保存在数据库表中的锁,如图 7a 所示。为了避免死锁,开发人员将每个锁与启动时生成的通用唯一标识符(UUID)相关联,该标识符显示为 run_id 变量,用于区分每次运行。因此,Broadleaf 可以通过检查保存的 UUID 在重新启动后忽略先前未释放的锁。
恢复其他应用程序数据可能具有挑战性,因为它需要在回滚或前向执行期间跟踪和保留 API 进度。然而,我们观察到没有应用程序做出了这样的努力,因此重新启动的应用程序很难确定更新在崩溃之前是否持续存在。这与第 3.4.1 节中讨论的验证失败回滚不同,其中开发人员决定回滚点。毫不奇怪,我们发现没有应用程序在崩溃并重新启动后回滚未完成的临时事务所做的更改,这证实了我们的观察。因此,为了处理中间状态,应用程序需要采取类似于处理数据库服务器崩溃的预防措施。
有趣的是,我们发现开发人员编写了数据库一致性检查器,类似于文件系统的 fsck,在应用程序在线时定期调用。例如,Discourse [17] 每十二小时检查并修复不一致的引用,例如缺少的头像、缩略图和主题。然而,这些检查是否足以确保(最终)恢复到一致的状态还存在疑问。结合许多情况跳过回滚的事实(第 3.4.1 节),可以表明某些应用程序被设计为在一定程度上容忍中间状态。我们在第 4 节中讨论中间状态引起的问题。
临时事务并没有完美地处理崩溃情况(容忍不一致状态、重启乐观事务、恢复协调元数据和应用程序数据),有些开发人员编写了数据库一致性检查器(类似
fsck)。TODO:想参考一下一致性检查器如何实现。
Comparison with Database Transactions
开发人员使用临时事务来实现与数据库事务相同的最终目标:面对并发和错误时正确执行应用程序逻辑[37]。此外,这两种方法都是通过协调包含多个数据操作的并发工作单元来实现这一点。为了更深入地了解这些方法之间的相似性和差异,我们在本节中进一步比较它们的概念细节(例如,定义事务范围的内容)及其语义细节(例如,保证什么)。表 5 给出了总结。
Concepts 概念。尽管没有像 SQL 这样明确的语言来描述临时事务,但是数据库事务中的许多概念在临时事务中找到了类比,如表 5 所示,它允许对临时事务进行详细剖析。数据库事务是一系列以一致方式转换数据库状态的数据库操作。它由事务开始、提交和中止语句以及其中包含的查询和数据修改语句定义。相反,临时事务是一段访问共享状态(包括但不限于数据库状态)的应用程序代码,以一致的方式执行业务逻辑。
为了执行数据库事务,数据库系统采用对应用程序透明的系统级并发控制和日志记录协议,以确保 ACID 属性。由于 ACID 执行,如果应用程序正确地将其业务逻辑构造成数据库事务,则可以轻松保证其正确性。然而,对于临时事务,应用程序开发人员需要在应用程序代码之间手动安装同步原语,而不(完全)诉诸数据库事务机制。如果没有系统级的协调机制,开发人员需要根据具体情况来设计和实现协调。因此,只有开发人员特别关注的操作才会得到协调。因此,临时事务允许更大的协调灵活性,但开发和维护的成本可能更高。
临时事务最显着的特点是开发者的意图在定义交易行为中所扮演的角色:在没有书面合同的情况下,我们作为外部观察者只能推测开发者希望临时事务是什么样的。例如,虽然事务范围的概念适用于临时事务,但它是由开发人员隐式定义的,我们只能根据应用程序源代码推断其范围:锁的关键部分和验证过程的跨度从相应的开始首先阅读。由于这些原语可能被错误地放置并导致错误,因此我们不能将它们视为临时事务范围的预言机。
许多临时事务没有明确的 assert 语句,因此很难判断开发者“希望临时事务的样子”。
此外,临时事务的结果要么成功,要么失败,这与数据库事务相同,但它们取决于开发人员如何解释临时事务的具体执行,因为不再有显式的 Commit/Abort 语句。当临时事务结束时,例如完成其最终的 unlock() 调用,外部观察者只能根据可见的效果来猜测开发人员是否会认为此执行成功。这种缺乏清晰度可能会增加开发和维护临时事务的开销,并导致微妙的错误,例如在临时协调中忽略关键操作(第 4 节)。
Semantics 语义。接下来我们通过 ACID 的视角比较两种方法之间的语义差异[43]。
最有趣的区别在于 ACID 的隔离。经典的隔离属性规定一个数据库事务的操作将与其他数据库事务隔离运行[30]。基于这个定义,我们已经看到的一个主要区别是,临时事务中只有部分操作会被协调,从而与其他临时事务隔离。另一个区别是,一个临时事务中的协调操作并不与所有其他临时事务隔离,而是与开发人员关心的临时事务的子集隔离。这些是开发人员手动安装同步原语来协调临时事务的自然结果。虽然这些差异可能会导致临时事务更容易出错,因为开发人员可以轻松省略执行冲突数据访问的 API(第 4.2 节),但他们还建议了优化数据库支持的应用程序的潜在研究方向。例如,人们可能会设计一种协调方案,为每个不相交的临时事务集生成独立的事务协调器,以避免潜在的热点。我们将在第 6 节中更详细地讨论未来研究的提示。
此外,我们发现开发人员使用临时事务来实现不同于所有四种标准化隔离级别的隔离。这是通过在乐观临时事务中使用基于值的验证来实现的。例如,在图 9 中,Discourse 论坛应用程序通过将帖子内容字段的当前值与从先前请求检索的值进行比较来验证更新是否可以应用于帖子(第 3.1.2 节)。此临时事务允许使用 [1] 的符号进行以下不可序列化历史记录。
\[ H : w_0 (x_0), c_0, r_1 (x_0), r_2 (x_0), r_2 (x_0),w_2 (x_2), c_2, r_3 (x_2), r_3 (x_2),w_3 (x_3), c_3, r_1 (x_3),w_1 (x_1), c_1. \]
| \(T_0\) | \(T_1\) | \(T_2\) | \(T_3\) |
|---|---|---|---|
| \(w_0(x_0)\) | |||
| \(c_0\) | |||
| \(r_1(x_0)\) | |||
| \(r_2(x_0)\) | |||
| \(r_2(x_0)\) | |||
| \(w_2(x_2)\) | |||
| \(c_2\) | |||
| \(r_3(x_2)\) | |||
| \(r_3(x_2)\) | |||
| \(w_3(x_3)\) | |||
| \(c_3\) | |||
| \(r_1(x_3)\) | |||
| \(w_1(x_1)\) | |||
| \(c_1\) |
在这段历史中,交易 T0 创建了帖子版本 x0(下标指的是写入版本的交易),交易 T1、T2 和 T3 是由个人用户发起的三个后期编辑过程,例如 u1、u2 和 u3。在相应的执行中,u1 首先开始帖子编辑,获取帖子版本 x0。然而,当 u0 在第一次请求后正在本地编辑时,r1(x0)、u2 和 u3 开始并按顺序提交编辑,将帖子保留在 x3 版本。虽然从执行的角度来看 x0 和 x3 是不同的版本,但在这段特定的历史中,它们的值是相同的。由于临时事务使用基于值的验证(图 9),u1 仍然可以成功提交他的编辑,将帖子保留在版本 x1。有趣的是,H 不是可序列化的,因为在给定四个发布版本的任意顺序的情况下,H 的序列化图中始终存在循环(具有反依赖性)。 这种临时事务的隔离性也与其他弱隔离级别(例如 Read Committed)不同,因为这些级别中允许的历史记录并不都是开发人员手动协调允许的。这种不可序列化的执行似乎不会妨碍应用程序的正确性:如果用户在编辑时不知道内容已更改然后重置,则不太可能导致问题。这种场景是通用 CC 需要防止的臭名昭著的 ABA 问题的一个例子。然而,由于开发人员具备特定于应用程序的领域知识,他们可以明确选择不处理此类良性 ABA 问题。
临时事务不使用四种标准化的隔离级别,由开发者控制临时事务间的隔离。但我们需要研究
接下来,我们讨论 ACID 的其他三个属性。我们从原子性开始,这意味着事务的影响要么完全发生,要么根本不发生,即使故障中断了其执行。如 3.4 节所示,我们研究的临时事务努力确保发生运行时故障时的原子性。然而,大多数都没有解决服务器崩溃或数据库系统崩溃的问题。因此,当发生此类故障时,临时事务的效果将处于中间状态,从而违反了原子性要求。正如第 4.3 节所示,不提供崩溃原子性会阻碍应用程序的正确性和用户体验。
Durability 持久性意味着事务的已提交效果肯定会保留。未能提供持久性与未能提供原子性类似,因为两者都会使应用程序处于中间状态。在临时事务中,持久性在很大程度上取决于应用程序与不同存储系统的交互方式。当仅将数据持久保存到数据库系统中时(通常将单个数据库操作作为单语句自动提交事务执行),临时事务的持久性得到了简单的保证:临时事务在其写入返回后提交,从而使其持久通过数据库系统。然而,当使用其他存储系统时,持久性可能会很棘手。例如,Redis 默认情况下仅定期将快照持久保存到磁盘,崩溃可能会导致最近几分钟所做的更改丢失。为了实现持久性,开发人员需要显式启用日志记录,但我们没有发现任何证据表明开发人员在研究的应用程序中这样做了。同样,使本地文件系统更新持久也可能很棘手。我们发现开发人员通常采用“安全重命名”模式:他们将文件内容附加到新文件并将其重命名为目标文件,而不是就地更新文件(这需要显式刷新以确保持久性),这在许多情况下(不幸的是,并非全部)文件系统会保留所有写入并确保重命名成功后的持久性[72]。因此,在处理本地文件系统时没有发现持久性问题。
最后,一致性对开发人员来说更多的是一种要求,而不是一种属性:事务应该没有逻辑错误,并正确地将应用程序状态从一种一致状态转换为另一种一致状态。尽管某些应用程序运行后台一致性检查器,在某些情况下可能会容忍临时事务的不正确状态转换,但我们仍然认为,无论开发人员选择哪种协调方法,一致性要求都是强加给他们的。
CORRECTNESS ISSUES
正如我们在第 3 节中讨论的各种实现可能性表明,构建正确的临时事务并非易事。本节检查临时事务的正确性问题并将其与设计特征联系起来。下面讨论的问题肯定是不完整的,我们已经手动验证所有问题都是可重现的并会导致用户明显的后果。
结果摘要。 53 个案例中发现 69 个正确性问题(表 6);有些案例存在多个问题。此外,有 28 起案件造成严重后果(表 7),例如向客户收取错误费用。大多数问题与原语的使用和实现 (49/69) 有关,而其他问题则发生在选择协调内容 (16/69) 和处理中止 (4/69) 中。我们已向开发者社区提交了 20 份问题报告(涵盖 46 个案例 7);其中 7 起(涉及 33 起案件)已得到确认。


Incorrect Locks and Validation Procedures
Finding 6. 36 out of 65 pessimistic ad hoc transactions incorrectly implement or use locking primitives; 11 out of 26 optimistic ad hoc transactions do not ensure the atomicity of validation and commit, causing correctness issues.
发现 6。 65 个悲观临时事务中有 36 个错误地实现或使用锁定原语; 26 个乐观临时事务中有 11 个不能确保验证和提交的原子性,从而导致正确性问题。
Locking Primitive Issues
有 7 种不同的锁实现(第 3.2.1 节),其中 5 种可能是不正确的。
锁使用不正确。当开发人员重用现有系统的锁定原语时,就会出现误用。有两个现有的锁定原语被重用,数据库系统的 Select For Update 语句和 Java 的同步关键字(第 3.2.1 节),并且两者都有相应的错误使用情况。 Spree [99] 是错误使用 Select For Update 语句的示例。由于 Select For Update 语句获取的锁会在当前事务提交时释放,因此开发人员需要确保关键操作在当前事务内执行。不幸的是,Spree 没有显式地将 Select For Update 包含在数据库事务中,这会导致数据库锁在语句返回后立即释放 [77]。同时,SCM Suite [27] 显示了一个与 synchronized 关键字相关的有趣问题。从数据库系统加载数据后,SCM Suite 使用此关键字来同步线程本地 ORM 映射对象。结果,冲突的线程获取不同的锁并且永远不会互相阻塞[112]。

当开发人员打算使用单个锁来协调 RMW 操作时,会发生另一种类型的误用:他们忽略了对第一个查询语句的协调。具体来说,虽然临时事务打算获取锁来协调所有 RMW 数据访问,但有时在获取数据后,锁密钥(例如 ID)是已知的。在这些情况下,开发者需要在获取锁后重新读取数据来协调整个 RMW。有两种情况是开发人员忘记重新读取,导致 RMW 中的初始读取不协调。如图 12 所示,Spree 中的临时事务使用锁来协调并发支付处理。然而,只有在支付处理过程中从数据库系统读取支付后,支付才会被锁定,因为只给出了订单 ID。尽管锁会序列化后续写入,但整个 RMW 过程不是原子的,如果发送重复的结帐请求,可能会导致支付处理两次并对用户收取过多费用 [80]。
不正确的锁实现。开发人员实现的锁定原语也可能存在正确性问题。具体来说,开发人员错误地使用 Redis 存储和内存锁表构建锁定原语(第 3.2.1 节)。对于基于 Redis 的锁,Mastodon [93] 给出了开发人员实现租约语义的示例。具体来说,它们为锁条目启用 Redis [82] 的自动过期功能。因此,当条目在协调的关键部分完成之前超时时,锁可能会提前释放。不幸的是,Mastodon 不会检查锁是否提前过期,并且会出现不一致的情况,例如关注者时间线中出现的已删除帖子 [19]。此外,Mastodon 中的所有临时事务都是基于这种不正确的锁实现。对于基于内存锁表的锁,Broadleaf [14] 的支持逐出的锁表还提供租约语义——当表大小达到给定限制时,调用 LRU 策略从表中逐出锁 [83]。因此,如果事务持有的锁被逐出,则两个冲突的事务(例如结账和添加购物车)可能会同时访问相同的数据(例如订单总额),从而导致用户不付款等不一致情况对于同时添加的项目。
Non-Atomic Validate-and-Commit

基于验证的乐观临时事务需要避免验证和提交之间的更新冲突。因此,他们需要保证验证-提交原子性。然而,当开发人员手动实现验证过程(16 例)时,就会发生原子性违规,而使用 ORM 生成的验证过程的临时事务可确保原子性(10 例)。图 13 显示了 Discourse [17] 中的一个此类示例。在此示例中,版本用于跟踪可审阅项目(例如,有争议的 topic)的更改并防止管理员操作发生冲突。开发人员显式地将验证(第 3-5 行)和后续更新(第 6 行)包含在 Active Record 事务块中,其中应在数据库事务中发出查询。然而,验证查询是使用 MiniSql [18] 提供的接口来表达的,MiniSql 是一个独立于 Active Record 的模块。因此,Active Record 无法作为数据库事务的一部分拦截和发出验证查询,从而无法提供验证-提交原子性 [78]。
Incorrect Coordination Scopes
不正确的协调范围是指开发人员在选择临时事务中协调的内容时所犯的错误。
Finding 7. 16 issues arise from incorrect coordination scope. Specifically, developers either omit some critical operations in existing ad hoc transactions (11/16) or forget to employ ad hoc transactions for certain business procedures altogether (5/16).
结论 7。 16 个问题是由于协调范围不正确而产生的。具体来说,开发人员要么忽略现有临时事务中的一些关键操作 (11/16),要么忘记在某些业务过程中完全使用临时事务 (5/16)。

Omitting Critical Operations 省略关键操作。尽管选择协调内容的灵活性是临时事务的一个优势(第 3.1.1 节),但它也增加了关键操作不协调的可能性。如图 14 所示,Broadleaf [14] 中协调结账流程的临时事务忽略了所有 SKU 相关操作的协调。因此,购买相同 SKU 的不同订单同时结账可能会导致 SKU 数量减少量与已售商品数量不一致 [84]。此外,这个错误并不像简化示例中描述的那样明显。订单 ID 的锁定是通过 Spring 请求过滤器实现的,该过滤器检查所有传入请求并在请求参数中存在 order_id 参数时获取订单锁。同时,SKU 修改被隐藏在特定的请求处理程序中。对于请求处理程序开发人员来说,理解其他应用程序级同步构造如何(或不可以)执行相关协调可能很困难。乐观的临时事务也会出现此类错误。例如,在 Spree [99] 中,减少 SKU 数量的事务(如第 3.1.1 节所示)还涉及设置订单状态列。然而,对订单状态的修改并不协调,导致重复减少并导致库存水平不一致[77]。
忘记临时事务。忘记协调某些业务逻辑与事务是临时事务和数据库事务的普遍问题。然而,临时事务的情况更为灾难性。没有安装适当的临时事务(例如,另一个请求处理程序)的冲突业务过程可以自由地与由临时事务协调的其他过程交错,读取和写入“协调”数据。例如,在 Spree [99] 中,所有临时事务都部署在以 HTML 格式返回响应的请求处理程序中。然而,存在另一组具有相同功能的不协调的处理程序,并生成 JSON 格式的响应。因此,JSON 处理程序与 HTML 处理程序的交错导致数据库系统状态不一致 [75]。为了检测此类问题,开发人员必须了解处理程序执行的并发线程如何相互冲突,并了解特定处理程序的所有冲突操作。
Incorrect Failure Handling
Finding 8. Ad hoc transactions might incorrectly handle failures, including both runtime failures and server crashes.
发现 8:即席事务可能会错误地处理故障,包括运行时故障和服务器崩溃。
Incomplete Repairs 修复不完整。当使用事务修复“前滚”受影响的事务时,开发人员可能会得到不完整的修复,从而导致并非所有受影响的操作都被重新执行。在 Discourse [17] 中,当更新帖子的图像引用时,开发人员使用版本来跟踪从查询中获取的帖子的各个状态(第 3.4.1 节中所示的伪代码)。尽管可以精确地检测和修复对特定帖子的并发修改,但符合查询条件的新添加的帖子将被忽略。因此,这些新帖子将不会被处理,它们的图像参考因此悬而未决,以断开的链接的形式呈现给最终用户[81]。这是唯一存在此问题的案例。
崩溃后意外的中间状态。如果应用程序的设计不能容忍中间数据库状态,并且回滚处理程序无法阻止它们,那么如果发生服务器或数据库崩溃,它可能无法提供正常服务。我们彻底调查了 Broadleaf 和 Spree 临时交易崩溃的影响。我们确定了 31 个独特的崩溃场景,其中崩溃会使写入部分执行,并发现其中 28 个崩溃会导致用户明显的后果。如果在不同代码位置注入的崩溃导致同一组部分执行的写入,我们认为这些崩溃场景是相同的。例如,在 Spree [99] 中,结帐期间服务器崩溃可能会使付款处于中间状态(即状态列等于“正在处理”)。由于此类支付状态值在重启后不会回滚,Spree 既不能因为未完成的支付操作而发起新的支付操作,也不能恢复崩溃之前发起的支付,因为它们被视为正在由活动线程“处理”。因此,用户永远无法完成结帐[76]。
由于这两个应用程序都不处理数据库断开异常,因此当在服务器崩溃导致错误的代码位置注入时,数据库崩溃也会导致相同的错误。然而,反之则不然:数据库崩溃可能会引入并非由服务器崩溃引起的其他错误。例如,当使用 Broadleaf 的数据库支持的顺序锁(图 7a)时,锁关键部分期间的数据库崩溃会使锁处于已获取状态。尽管 Broadleaf 使用启动时生成的 UUID 来区分以前运行中未释放的锁和当前获取的锁,但数据库崩溃不会触发当前 UUID 的重新生成。因此,在应用程序重新启动之前,Broadleaf 无法获取数据库系统在其关键部分崩溃的顺序。
我们发现崩溃是良性的,原因有两个。8 在 Broadleaf 的两个良性崩溃场景中,尽管应用程序状态不一致,但 Broadleaf 通过预防性措施处理这种不一致,将这些部分写入标记为“已存档”,如第 3.4 节所述。 2.这样重启后就可以继续正常服务了。在 Spree 中乐观临时事务的另一个良性崩溃场景中,崩溃之前的写入仅影响协调元数据,即版本计数器。因此,Spree 可以根据新版本重新执行临时交易来正常服务。
PERFORMANCE EVALUATION
Different Primitive Implementations
Different Coordination Granularities
Different Rollback Methods
DISCUSSION
到目前为止,我们已经证明临时事务容易出现错误,难以识别和理解。然而,它们仍然广泛用于 Web 应用程序,主要是在关键 API 中。此外,在其他大规模 Web 应用程序中观察到应用程序级协调 [9, 52, 53, 86]。例如,受我们的研究的启发,来自阿里巴巴的一个数据库工程师分享到,淘宝,中国最大的在线购物平台,进行了广泛的应用程序级并发处理和优化,导致他们的数据库系统只服务于大量但简单的工作负载[121]。我们认为使用临时事务有具体的动机,而不是将这种现象归因于开发人员忽略了数据库事务的能力。为了阐明这个主题,我们在本节中基于我们对临时事务和 Web 应用程序的经验和理解,我们采取了一个潜在的自以为是的观点。
在高层次上,我们认为当今 Web 应用程序的协调要求与当前的数据库系统之间存在差距。我们的研究表明,开发人员经常求助于临时事务来实现难以使用数据库事务获得的协调(第 3.1 节)。在某些情况下,可以使用数据库事务,但代价是开发增加或性能下降。例如,为了在长业务流程中实现对特定数据访问的部分协调(第 3.1.1 节),开发人员可能需要显式地建立多个数据库连接,并通过其中一个连接手动放置数据访问以在数据库事务中协调,同时将其余部分放置在其他连接中。此外,开发人员还需要制作单独的 SQL 语句,以避免 ORM 生成的 SQL 语句在数据库事务中错位。通过这样做,开发人员有效地丢弃了 Web 框架努力提供的开发辅助,例如自动事务管理 [114, §1],最后伴随着具有重复且容易出错的数据库事务管理代码杂乱的应用程序逻辑。在其他情况下,数据库事务是不明智的。例如,单独的数据库系统很难协调分布式事务,这在应用程序使用其他存储后端(如 KV 存储和 ile 系统)来管理数据时是必要的(第 3.1.3 节),当应用程序本身以分布式方式构建和部署时。尽管许多数据库系统支持 XA [67](尽管有时不正确 [50])等协议,但对其他存储系统的支持相当有限。因此,开发人员必须手动制作协调。
自然出现的下一个问题是:是什么导致了这一差距。我们相信答案在于 Web 应用程序的复杂性的快速增长,而来自数据库系统和其他方的事务支持并没有跟上步伐。随着互联网和移动计算的出现,Web 应用程序的功能已经从简单的信息演变而来,这些信息现在涵盖了我们日常生活的几乎所有方面,例如购物、社交、生产力和娱乐。因此,他们的业务逻辑复杂性也相应增加,如果它们由数据库事务协调,则会导致事务膨胀,这通常被认为对应用程序性能有害[70,96,103,105]。此外,纯粹的复杂性也迫使应用程序模块化和分发。许多应用程序功能已被模块化和外部服务,例如 Elasticsearch 搜索引擎 [34] 和 Stripe 支付服务[115]。此外,web 应用程序已经从独立的单片服务器发展到微服务和无服务器等分解架构。同时,数据库事务仍然相对稳定,它们的接口和语义在 90 年代成熟,仍然决定了应用程序如何今天对数据库事务进行编程。因此,数据库事务不足以协调 Web 应用程序中日益复杂的业务逻辑,从而导致我们今天面临的差距。尽管事务概念仍然是构建复杂可靠的应用程序的一个简单而有吸引力的工具,但仅来自数据库系统的事务支持远非科学,迫使开发人员编写自己的临时事务。
这些观察结果表明,我们应该采取更广泛的视角,并从全局的角度考虑事务支持,而不是仅在数据库系统中解决应用程序的问题。为此,我们确定了我们认为值得进一步调查的几个问题,并可能导致新的研究途径,如下所示。
事务如何影响复杂 Web 应用程序的性能。我们所见的事务的大多数论点是主观的,通常缺乏具体的数字和清晰的上下文。清楚地了解影响性能对于识别现实世界应用程序的正确解决方案至关重要是至关重要的。事务的性能问题通常归因于分布式事务中事务复杂度的增加和两阶段提交(2PC)成本。然而,尚未对这些因素的影响进行系统调查。目前尚不清楚它们是否总是引入性能损失、它们带来的退化程度以及导致成本的原因。这是由于资源锁定的时间延长或工作集增加。原因是否植根于框架实现的低效协调或确保 ACID 语义的固有协调。例如,如果问题通常是由并发控制协议引起的,这些协议在不幸的时间或粒度上做出次优锁定决策(第 5.2 节),则可能的解决方案是导出新的接口,以提供适当的锁定提示,同时保留 ACID 语义而不是开发新的事务语义。基于我们的经验,彻底评估和理解应用程序性能可能不是微不足道的。因此,系统理解将是未来研究的一个重要价值。
事务复杂性能否降低。如果 Web 应用程序的复杂性导致事务对于数据库系统无法处理过于复杂,那么下一个实际步骤是研究降低 Web 应用程序中事务复杂性的方法。如今,开发人员通常在应用程序代码中使用 ORM 对数据访问进行编程,以实现可移植性和发展敏捷性。他们还严重依赖库来动态组合事务,例如 Spring Framework [11]4 提供的 @Transactional 注释,这使得标记方法及其调用者的数据访问在事务中执行。然而,如果没有仔细的关注,这种库创建的事务可以很容易地通过意外诱导的数据访问(第 3.1.1 节)进行膨胀,如果应用程序已经发布到生产中,就很难重新工作。在我们的观察中,事务复杂性通常会意外增加。例如,添加 @Transactional 注释的开发人员可能不知道被调用者中做出的确切数据访问,这可能是由于个人开发人员不知道其他人开发的功能和模块的详细信息。因此,将事务与复杂应用程序结构解耦的解决方案可能很有吸引力,因为事务复杂性可以显式观察和管理。或者,阻止开发人员将所有数据访问包装到单个事务的新接口,同时仍然促进组合正确的应用程序逻辑也可能是有益的。在后一种情况下,对于新的接口,也应该考虑来自底层数据库系统的相应支持。
如何替代事务语义。除了降低事务复杂性外,er 的另一个机会的非 ACID 事务语义来解决性能问题。由于我们的研究和其他[52,53,86,121],现实应用中的许多事务已经偏离了经典的 ACID 语义。例如,许多临时事务具有惊人的崩溃原子性(第 3.5 节)。在 Web 应用程序中使用微服务、暂定/取消/并发(TCC)模式等分解架构,这是一种跨不同组件编写事务的有趣模式,已成为替代分布式 ACID 事务的常见做法[52, 53]。然而,实践的状态远非理想。临时事务大多是从头开始制作的,因此容易出错(第 4 节)。同时,虽然 TCC 模式有一些库支持 [6, 35],但开发人员仍然会带来负担,例如确保个人活动调用和补偿的赔率的责任 [109]。正如我们的研究表明,将协调转移到应用程序级别通常迫使开发人员处理仅与业务逻辑轻度相关的问题,并导致容易出错的应用程序。因此,迫切需要许多工作来形式化这些非 ACID 语义,评估它们的优点和陷阱,并开发缓解编程错误的支持接口和系统。此外,由于非 ACID 协调通常发生在应用程序级别,并且数据库系统没有观察到,因此从数据库系统到应用程序级别的整体优化研究也很有希望。

我们对未来研究的建议谨慎实用,遵循衡量然后构建的心态。然而,他们促使我们重新思考数据库系统为 Web 应用程序中的并发处理提供支持。除了标准的数据库事务之外,许多现有的特定于供应商的界面数据库系统,用于传递自定义 š 的提示。例如,PostgreSQL 提供了明确的用户锁,其中锁由用户指定的整数标识,并由活动会话或事务范围 [49, §13.3.5]。这些提示为检查数据库系统如何满足当今 Web 应用程序的协调需求提供了一个起点。
这些协调提示能否帮助开发人员实现协调目标(例如,协助编写临时事务甚至替换它们)。我们在排名前十的 RDBMS [26] 中编译了一个支持协调提示的摘要(表 9),发现它们可以部分防止错误,同时保留临时事务的好处(表 10)。例如,为了仅协调特定的数据库操作(第 3.1.1 节),我们可以使用 Read Commited database 事务中 SQL Server [71] 的 HOLDLOCK 显式锁定提示来增强它们。因此,应用程序只付出了确保特定操作一致性的性能成本,并且开发人员可能会因为涉及较少的临时结构而带来更少的精神负担。然而,并非所有临时事务都可以从这些协调提示中受益,例如 OCC 原语不存在。同时,数据库系统通常只支持列出的提示的一个子集,对于相同类型的提示,它们可能表现出不同的语义(表 9)。例如,在 MySQL 中,如果显式锁定任何表,则拒绝对非显式锁定表的访问[83,§13.6];其他数据库系统没有这个限制。此外,临时事务和商业逻辑的紧密耦合使得迁移变得非常重要。简而言之,现有的数据库系统提供了一些但不是所有必要的实用程序来解决临时事务中包含的应用程序需求。因此,我们认为需要新的抽象和工具。下面我们将讨论一些。
OCC 原语。现有的主要数据库系统的 CC 基于 2PL 或多版本并发控制(MVCC)[11,2,Part9]。因此,如果应用程序需要 OCC,例如,为了处理多请求交互(第 3.1.2 节),开发人员必须制作乐观的临时事务。因此,我们认为需要新的 OCC 原语,并且鉴于许多系统是闭源的,它们应该在 ORM 层提供。一种可能的格式是乐观事务声明 @OptimisticallyTransactional。ORM 不是完全将协调委托给数据库事务,而是负责内部跟踪每个声明乐观事务的读/写集,并原子验证和提交更改。另一个建议是乐观事务的延续:save(trans)→tid 和 restore(tid)→trans,这有助于处理多请求交互。拥有 ORM 的样板程序会降低应用程序的复杂性和错误的机会。同时,新界面捕获的语义为进一步优化提供了机会。
现有提示的代理模块。为了暴露现有数据库系统的高级功能,同时隐藏它们的差异,我们认为这是一个提供通用协调定制接口的应用程序级代理模块。该模块可以集成到 ORM 系统中或作为独立系统呈现。一般来说,当使用数据库系统不支持某些提示时,该模块应该提供回退。例如,该模块应该提供基于数据库表的锁实现作为显式用户锁的回退。
开发支持工具。为了帮助改进现有的、高度复杂的应用程序以及临时事务,我们相信必须设计新的开发支持工具来帮助开发人员定位临时事务,识别潜在的正确性和性能问题,并通过提供可靠的建议来修复它们。最终,这些工具应该将大多数临时事务转换为更模块化的形式,无论是数据库事务还是上面提到的新抽象。
RELATED WORK
了解实际应用中的同步。一些研究调查了应用程序如何使用手动协调方法来处理并发性。之前的一项研究[102](即 IPADS 在 SIGMOD'22 上的文章)已经识别了临时事务的现象,并研究了它们的特征、正确性和性能。这项工作对之前的研究进行了四倍的扩展。首先,我们通过与数据库事务的详细比较阐明了临时事务的概念,检查了概念细节和语义。其次,我们深入研究了临时事务的故障处理,包括开发人员如何(或未)处理各种类型的故障以及实际故障如何影响这些应用程序,这在之前的研究中只触及了表面。第三,我们仔细分析了临时事务背后的动机(之前这是一个悬而未决的问题),并讨论了其含义以及未来研究的潜在途径。最后,我们提供了有关如何构建临时事务、它们的错误如何显现以及它们如何在延迟和可扩展性方面执行的更多详细信息。
此外,Bailis 等人 [8] 研究了使用 ORM 不变验证 API 来确保应用程序完整性,而 Warszawski 和 Bailis [104] 则专注于通过 Web 应用程序使用数据库事务。我们在 2.2 节中深入讨论和比较了这些作品。 Cheng 等人 [16] 对现实世界的开源数据库支持的应用程序的并发相关问题进行了广泛的研究,重点关注根本原因、后果和补救措施。他们与我们产生共鸣的有趣发现之一是,开发人员经常采用临时解决方案(例如锁)来缓解此类错误,而不是升级到可序列化数据库事务,这主要是出于性能问题。与此同时,Xiong 等人[107]调查了另一种类型的手动协调——多线程程序中同步变量的临时循环。与(临时)事务不同,临时循环提供低级互斥来帮助程序安全地访问共享内存变量,而不是访问外部数据库的事务隔离。尽管与临时事务存在差异,Xiong 等人发现临时循环也可以有不同的实现,并且容易出现正确性问题。
确保数据库支持的应用程序的正确性。为了在底层数据存储不支持事务时构建应用程序,Dey 等人 [23, 24] 提出了一种应用程序级协议 Cherry Garcia,该协议通过异构 KV 存储(例如 Azure 存储和 Google Cloud)提供带有快照隔离的 ACID 事务贮存。其他人则关心直接在 KV 存储上运行的应用程序,尤其是那些弱复制的应用程序。 Balegas 等人 [9] 提出通过引入补偿更新来透明地纠正由弱一致性复制引起的不一致来保留应用程序不变性。 Balegas 等人[10]提出了显式一致性,它通过确保并发执行期间指定的应用程序不变量来增强最终一致性。他们静态分析应用程序逻辑以查找不安全操作,并使用保留[70,73,97]或无冲突复制数据类型(CRDT)[96]来纠正它们。 Bailis 等人 [7] 引入了不变合流(invariant confluence),该属性表明一组事务是否可以在不协调的情况下执行,同时保留给定的应用程序不变量,以及确定该属性的分析。 Alvaro 等人 [3] 提出了一种顺序不敏感的编程语言 Bloom,它鼓励消除并发事件的排序要求,以便在不协调的情况下尊重应用程序的一致性 [46]。
提高数据库支持的应用程序的性能。临时事务的定制协调所体现的想法可以在之前的研究工作中找到。我们在下面简要回顾一下它们。
先进的锁定方法有助于减少错误冲突。数据关联感知锁定方法[33, 52]已经被提出用于面向对象的数据库管理系统(OODBMS)[4,5,11],这与临时事务中的锁定方法类似(第 3.3.1 节)。在 OODBMS 中,对象自然是通过关联关系来访问的,从而使数据库能够本地提供这种优化。而在 Web 应用程序中,ORM 框架隐藏了这种访问模式,开发人员必须手动编写这种优化。为了减少间隙锁的错误冲突,Graefe [34]提出了一种将幽灵记录(即逻辑删除的记录)与分层锁定相结合的方法[38]。当索引间隔大于请求的键范围时,此方法会分割索引间隔,从而消除原始查询谓词仅包含相等或范围条件时的错误冲突,例如第 3.3.2 节中的第二个示例。
事务修复 [21, 106] 是一种使用重新执行来避免冲突时中止的技术。关键思想是提取提交事务中的依赖关系,以确定需要使用最新数据重新执行的最小操作集。因此,这些方法需要在执行之前分析以存储过程表示的事务逻辑。然而,Web 应用程序以交互方式提交事务而不是存储过程,从而将计算逻辑和依赖关系保留在数据库系统之外。
同时,针对数据库支持的应用程序衍生出许多分析方法来识别性能问题。为了避免 Web 应用程序中的死锁,Grechanik 等人 [39, 40] 提出了一种结合运行时监控和离线保持等待周期检测的方法。他们的方法需要了解应用程序的出站 SQL 语句,而在 Web 应用程序中,大多数 SQL 语句是在运行时生成的。研究人员还研究了 ORM 引起的性能问题 [109, 110],并提出了自动修复这些问题的工具 [15, 111]。
CONCLUSION
本文首次对现实世界的临时事务进行了全面的研究。我们检查了来自 8 个流行开源 Web 应用程序的 91 个案例,并确定了临时事务的普遍性和重要性。我们表明,临时事务比数据库事务灵活得多,这是一把双刃剑——它们可能具有性能优势,但容易出现正确性问题。
ACKNOWLEDGMENTS
我们感谢我们在该项目的各个阶段与周周、沈嘉焕和董志远进行的富有洞察力的讨论以及匿名审稿人的建设性反馈。该工作得到了国家自然科学基金项目(批准号:61925206、62132014、62172272)和上海市科委高技术支持计划(批准号:20ZR1428100)的资助。通讯作者为王兆国(zhaoguowang@sjtu.edu.cn)。

