摘要
本文梳理了数据库事务的发展史。在 SQL 标准规定的 SER、RR、RC 和 RU 之外,重点介绍了 SI 隔离级别。本文还介绍了提高事务隔离级别的几种方式,并展望了未来可能出现的高效 SER 的实现方式。本文是 数据库事务发展史+SSI 隔离级别原理 课程笔记。
1992 年:ANSI SQL92 事务隔离级别
| Isolation Level | Dirty Read | Fuzzy Read | Phantom |
|---|---|---|---|
| Read Uncommitted | 允许 | 允许 | 允许 |
| Read Comitted | 不允许 | 允许 | 允许 |
| Repeatable Read | 不允许 | 不允许 | 允许 |
| Serializable | 不允许 | 不允许 | 不允许 |
Dirty Read、Fuzzy Read 和 Phantom 分别表示脏读、不可重复读、幻读三种异象(phenomenon)。
最经典的表格,但几乎所有的教材(包括南大软院采用的教材)都止步于此。
但其实 SQL92 的隔离级别存在许多问题:
- 只涉及单版本,没有考虑 MVCC;
- 对异象的自然语言表述存在歧义。
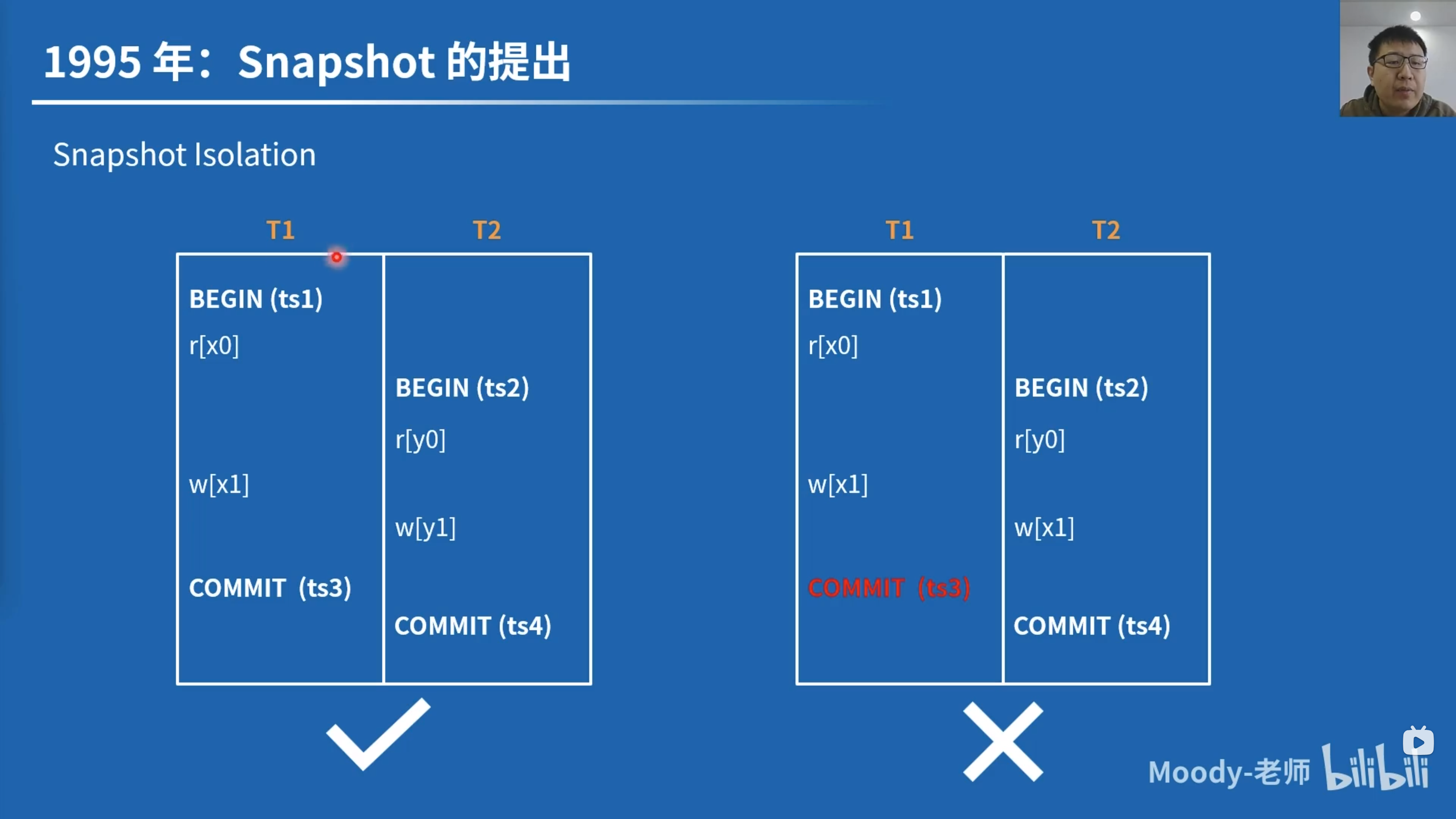
1995 年:Snapshot 的提出
1995 年,微软 Hal Berenson 等人发表文章《A Critique of ANSI SQL Isolation Levels》1。
隔离级别定义
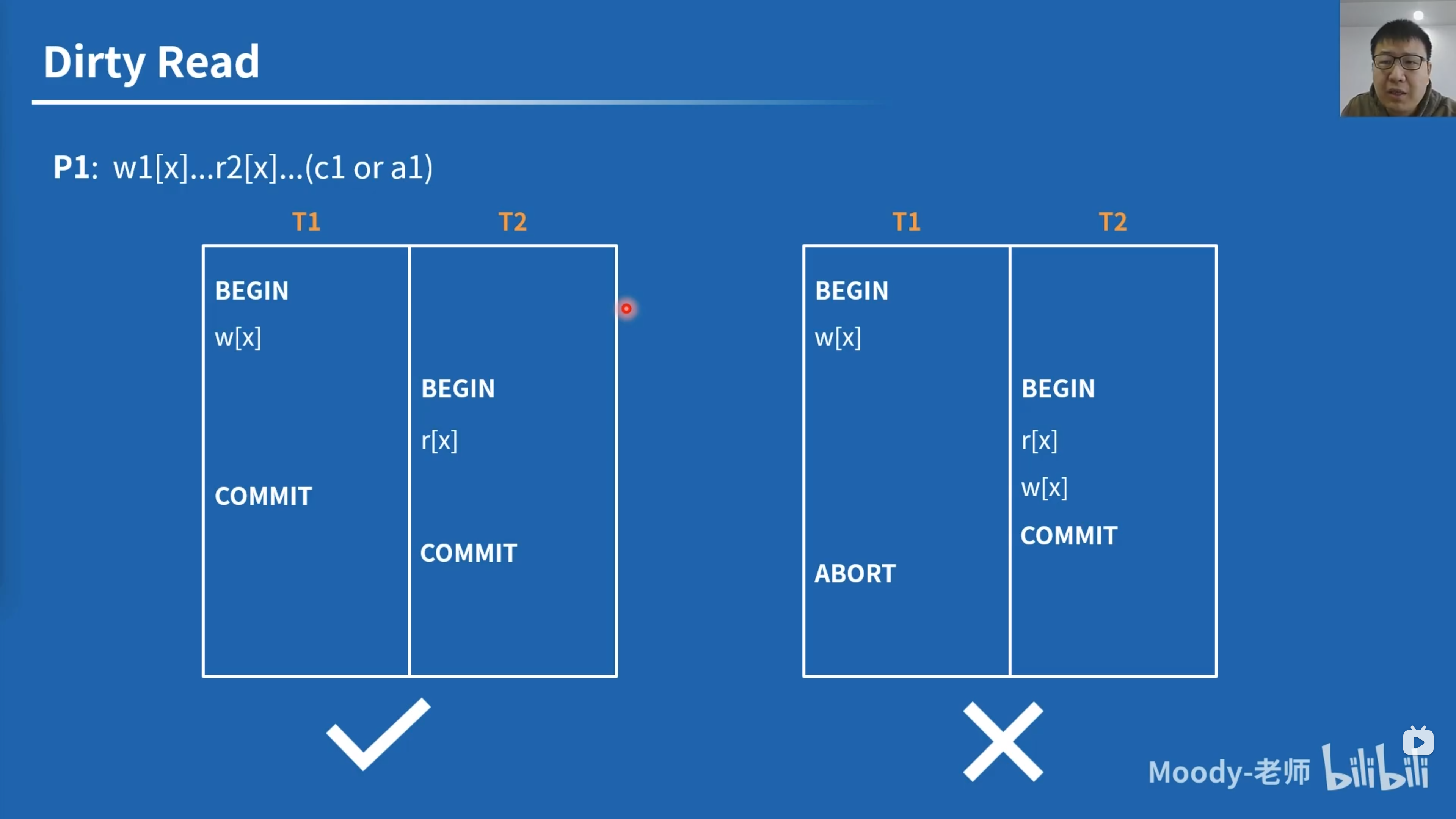
文章首先对 SQL92 中的三种异象进行了精准定义,并新增了 P0 异象。以下定义中的 P 是 phenomenon,A 是 anomaly,中括号中的 P 是查询谓词。以下的 \(w1[x]\) 表示 \(T_1\) 写记录 \(x\),\(rc\) 则表示 read cursor,\(a1, c2\) 表示 \(T_1\) Abort,\(T_2\) Commit。
\[ \text{Dirty Write } P0: w1[x] \dots w2[x] \dots (c1 \text{ or } a1) \\ \text{Dirty Read } P1: w1[x] \dots r2[x] \dots (c1 \text{ or } a1) \\ \text{Non-Repeatable Read } P2: r1[x] \dots w2[x] \dots (c1 \text{ or } a1) \\ \text{Phantom } P3: r1[P] \dots w2[y \in P] \dots (c1 \text{ or } a1) \\ \]
使用 P0-P3 描述 SQL92 提出的四种隔离级别:
| Isolation Level | P0 Dirty Write | P1 Dirty Read | P2 Fuzzy Read | P3 Phantom |
|---|---|---|---|---|
| Read Uncommitted | 不允许 | 允许 | 允许 | 允许 |
| Read Comitted | 不允许 | 不允许 | 允许 | 允许 |
| Repeatable Read | 不允许 | 不允许 | 不允许 | 允许 |
| Serializable | 不允许 | 不允许 | 不允许 | 不允许 |
文章还描述了 P1-P3 的严格版本:
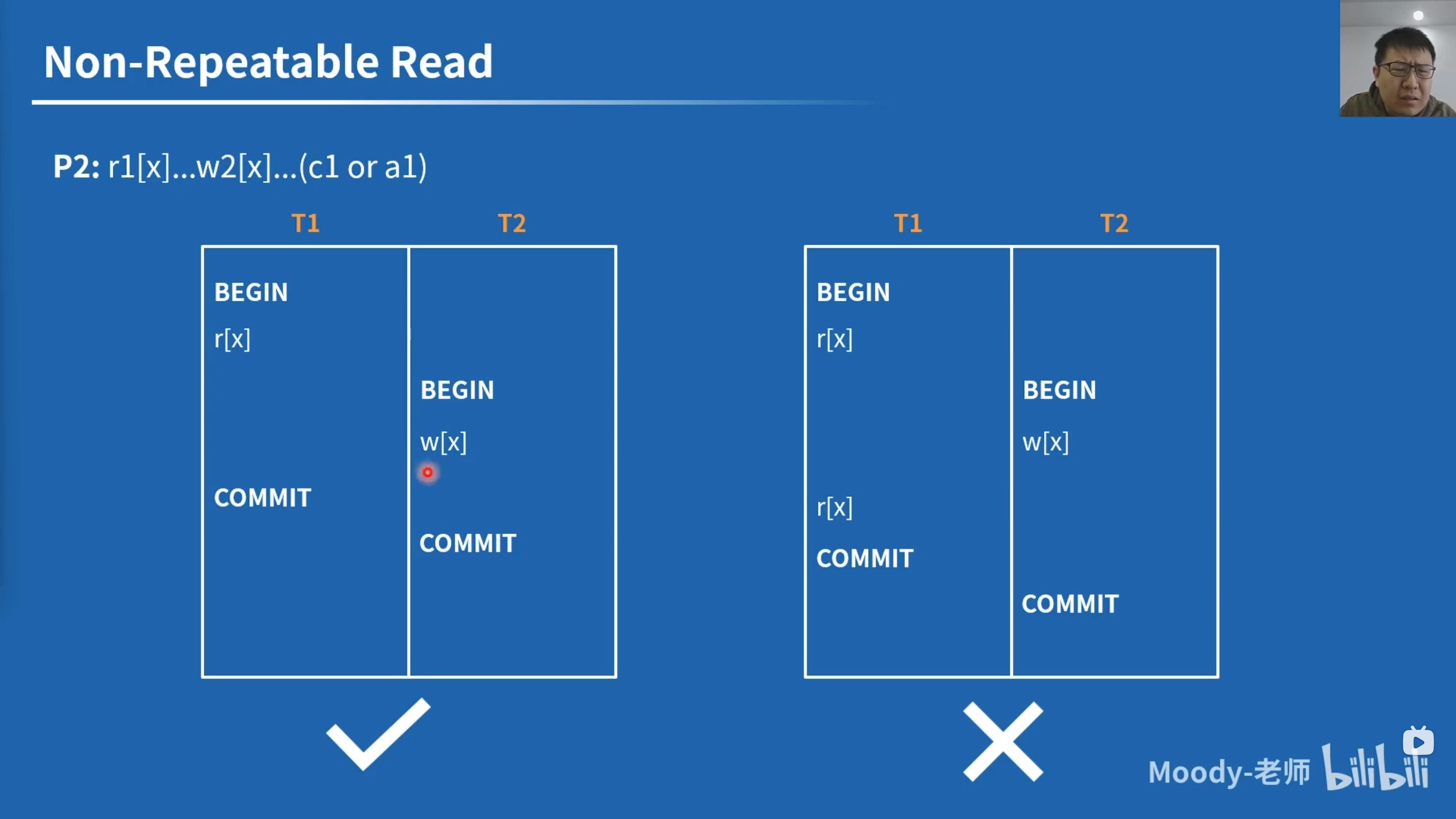
\[ \text{Dirty Read } A1: w1[x] \dots r2[x] \dots (a1 \text{ and } c2 \text{ in either order}) \\ \text{Non-Repeatable Read } A2: r1[x] \dots w2[x] \dots c2 \dots r1[x] \dots c1 \\ \text{Phantom } A3: r1[P] \dots w2[y \in P] \dots c2 \dots r1[P] \dots c1 \]
文章还描述了其他几种异象:
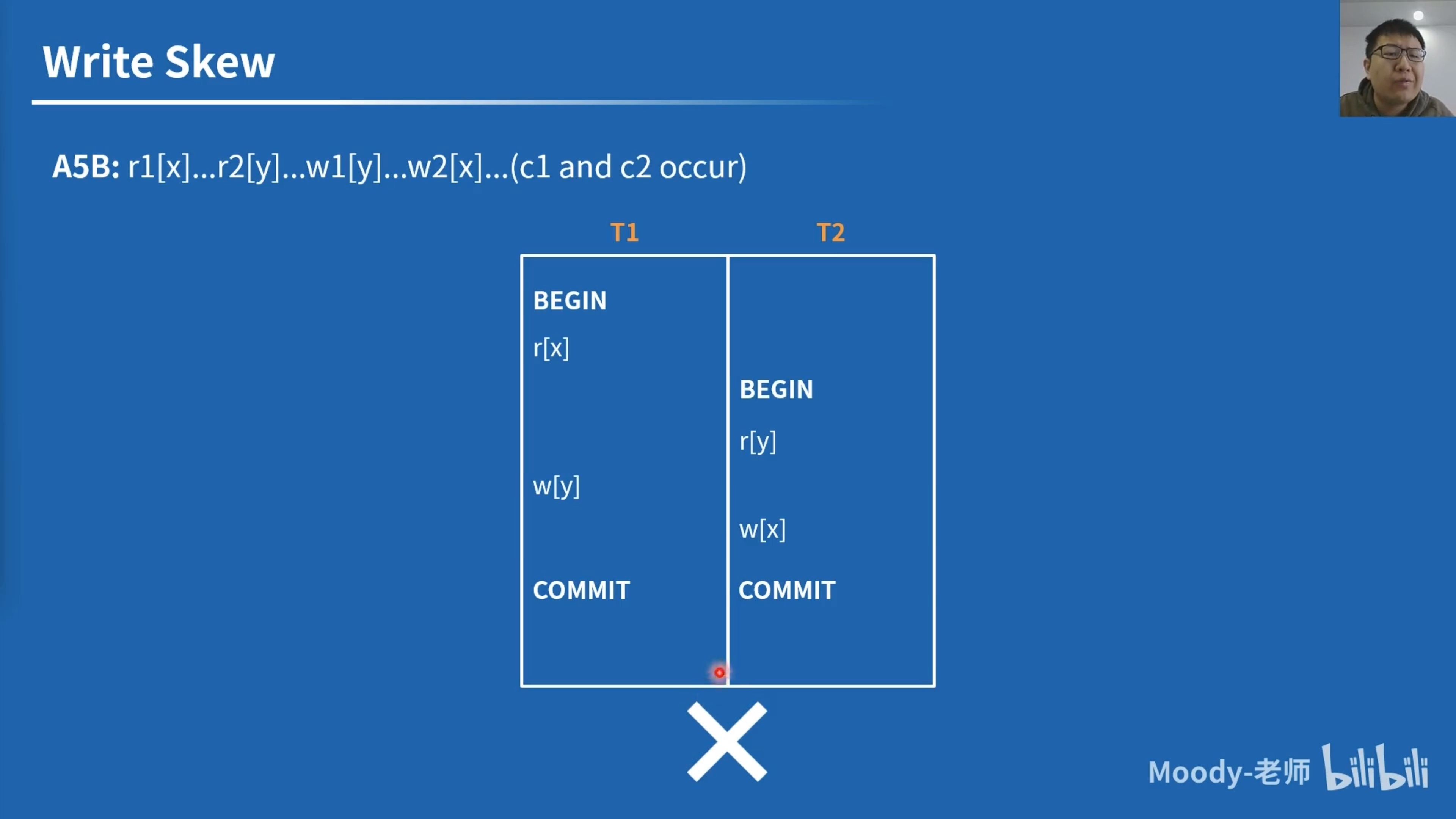
\[ \text{Lost Update } P4: r1[x] \dots w2[x] \dots w1[x] \dots c1\\ \text{Cursor Lost Update } P4C: rc1[x] \dots w2[x] \dots w1[x] \dots c1\\ \text{Read Skew } A5A: r1[x] \dots w2[x] \dots w2[y] \dots c2 \dots r1[y] \dots (c1 \text{ or } a1)\\ \text{Write Skew } A5B: r1[x] \dots r2[y] \dots w1[y] \dots w2[x] \dots (c1 \text{ and } a1 \text{ occur})\\ \]
| Isolation Level | P0 Dirty Write | P1 Dirty Read | P4C Cursor Lost Update | P4 Lost Update | P2 Fuzzy Read | P3 Phantom | A5A Read Skew | A5B Write Skew |
|---|---|---|---|---|---|---|---|---|
| Read Uncommitted | 不允许 | 允许 | 允许 | 允许 | 允许 | 允许 | 允许 | 允许 |
| Read Comitted | 不允许 | 不允许 | 允许 | 允许 | 允许 | 允许 | 允许 | 允许 |
| Cursor Stability | 不允许 | 不允许 | 不允许 | 有时允许 | 有时允许 | 允许 | 允许 | 有时允许 |
| Repeatable Read (Read Atomic) | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 | 允许 | 不允许 | 允许 |
| Snapshot Isolation | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 | 有时允许 | 不允许 | 允许 |
| Serializable | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 |
从上表可以看出,在某一隔离级别中,P4 丢失更新和 P2 不可重复读总是同时被允许或被禁止。
另外,上表只考虑到两个事务的异象,未考虑到多个事务的异象。例如 SI 可能在三个两两不冲突的事务中出现不一致的现象,此时三个事务的优先图出现环。
上表中出现“有时允许”的原因可能是相应异象的定义并不统一。例如 SQL 标准中的术语幻象问题指非可重复谓词读(在这种情况下 SI 解决了幻象问题);但在另一些领域(如《数据库系统概念(第 6 版)》中译版第 390 页脚注也提到了这一问题,该书中 P369 对幻象问题的定义是“查询结果会因另一并发事务是先于还是后于执行的查询而有所不同”,因此该书不认为 SI 解决了幻象问题。
笔者在 MySQL 可重复读如何“避免”幻读? | EagleBear2002 的博客 这篇文章中深入讨论了幻读问题及其“解决”方案。
根据上表,绘制隔离级别关系图。

SI 的实现
RC、RU 和 RR 一般用二阶段锁来实现。问题:小规模问题上会造成锁浪费。
SI 需要实现 MVCC。
Snapshot Isolation 的实现:
- 事务开始时,获取一个时间戳 StartTimestamp
- 读数据时,读 StartTimestamp 时刻的快照
- 写数据时,追加数据的新版本
- 事务准备提交时,获取一个 CommitTimestamp,它需要比现存的 StartTimestamp 和 CommitTimestamp 都大
- 事务提交时进行冲突检查,如果没有其他事务在 [StartTS, CommitTS] 区间内提交了与自己的 WriteSet 有交集的数据,则本事务可以提交
左边用例通过了 SI,但无法防止 Write Skew。
- Snapshot Isolation 无法防止 Write Skew
- Write Skew 在很多工程实践中是可接受的,所以 SI 隔离级别比较常见。电商公司一般使用 RC 或 RR 上。Oracle 默认 SI。
- SI 隔离级别使用乐观的时间戳方法,在性能和隔离性上取得了较好的平衡。推测:SI+A5B 的性能可能优于 RR+P3
- 需求:如何在 SI 级别的基础上,消灭 Write Skew,达成 SERIALIZABLE?
1999 年:基于图的事务依赖分析
等效分析:交换不冲突的操作
左右两边形式上都没有避免 Dirty Read,但从执行结果上看,左边用例是满足 SER 的,右边不满足。
两个用例都没有避免不可重复读,但左边用例从执行结果上满足 SER,右边不满足。
写偏序不符合 SER。
作者提出了导致事务之间异常的三种冲突:
- 读写冲突:Read-write conflicts(泛化 P2)
- 写读冲突: Write-read conflicts (泛化 P1)
- 写写冲突: Write-write conflicts (泛化 P0)
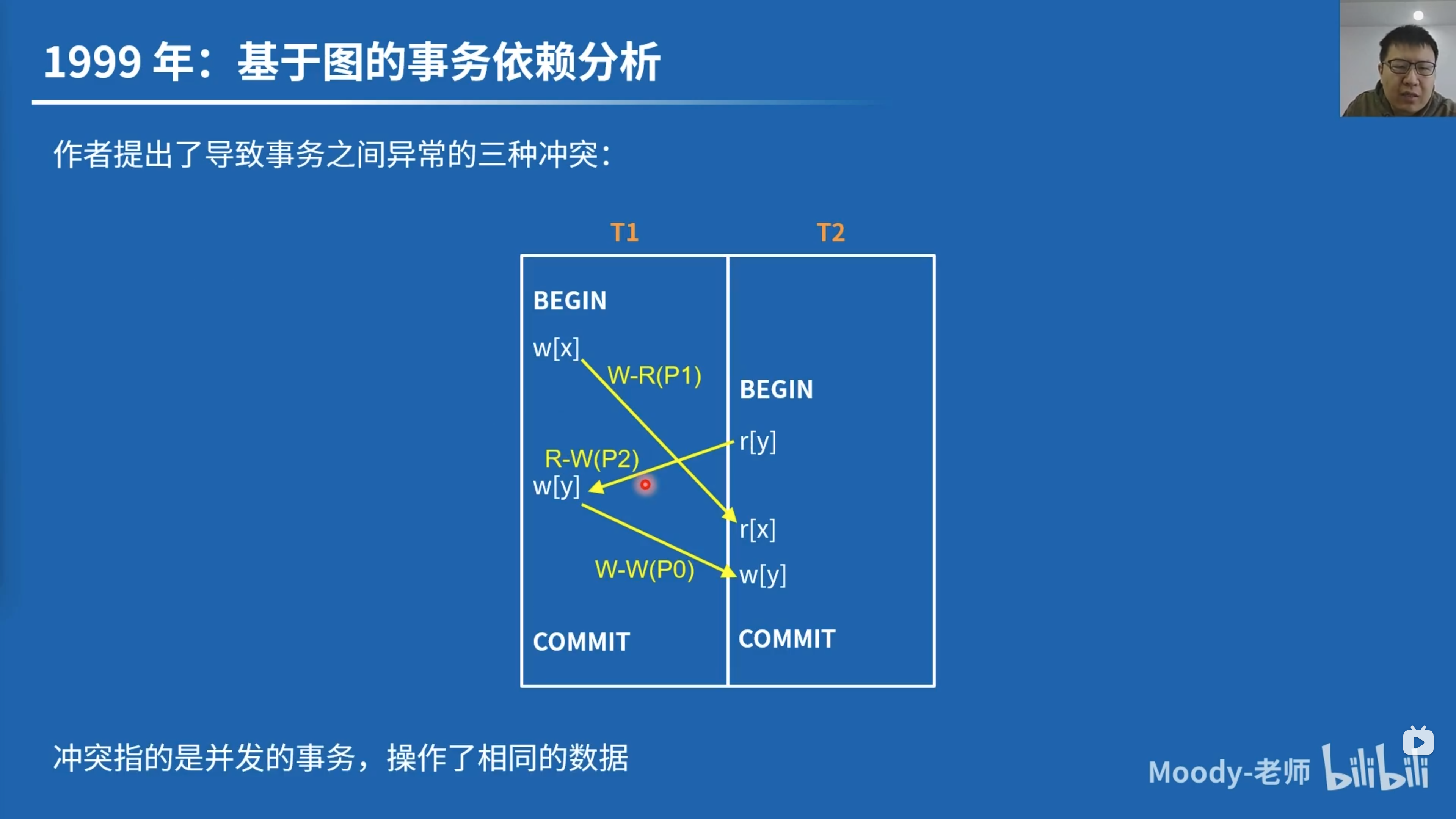
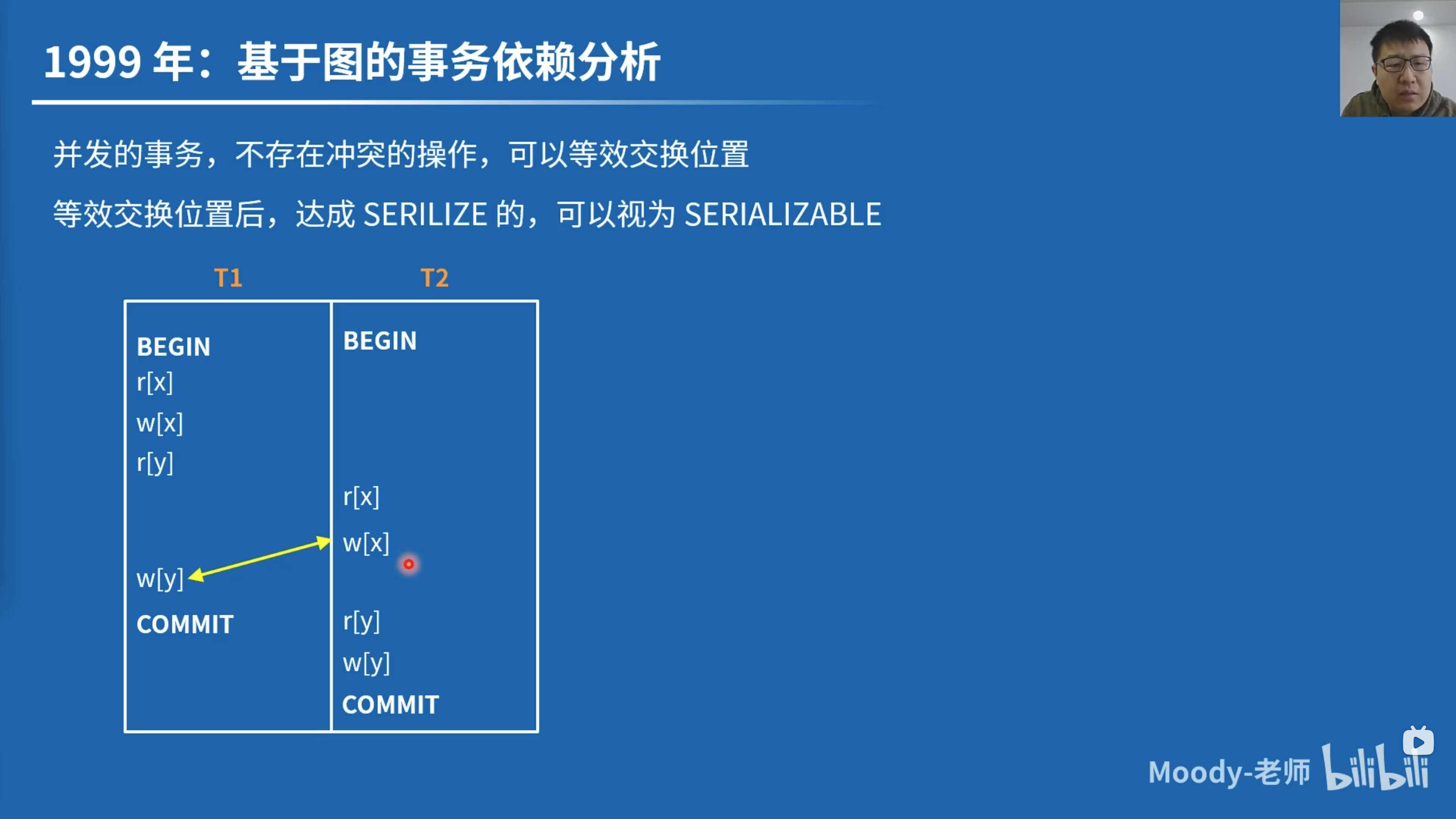
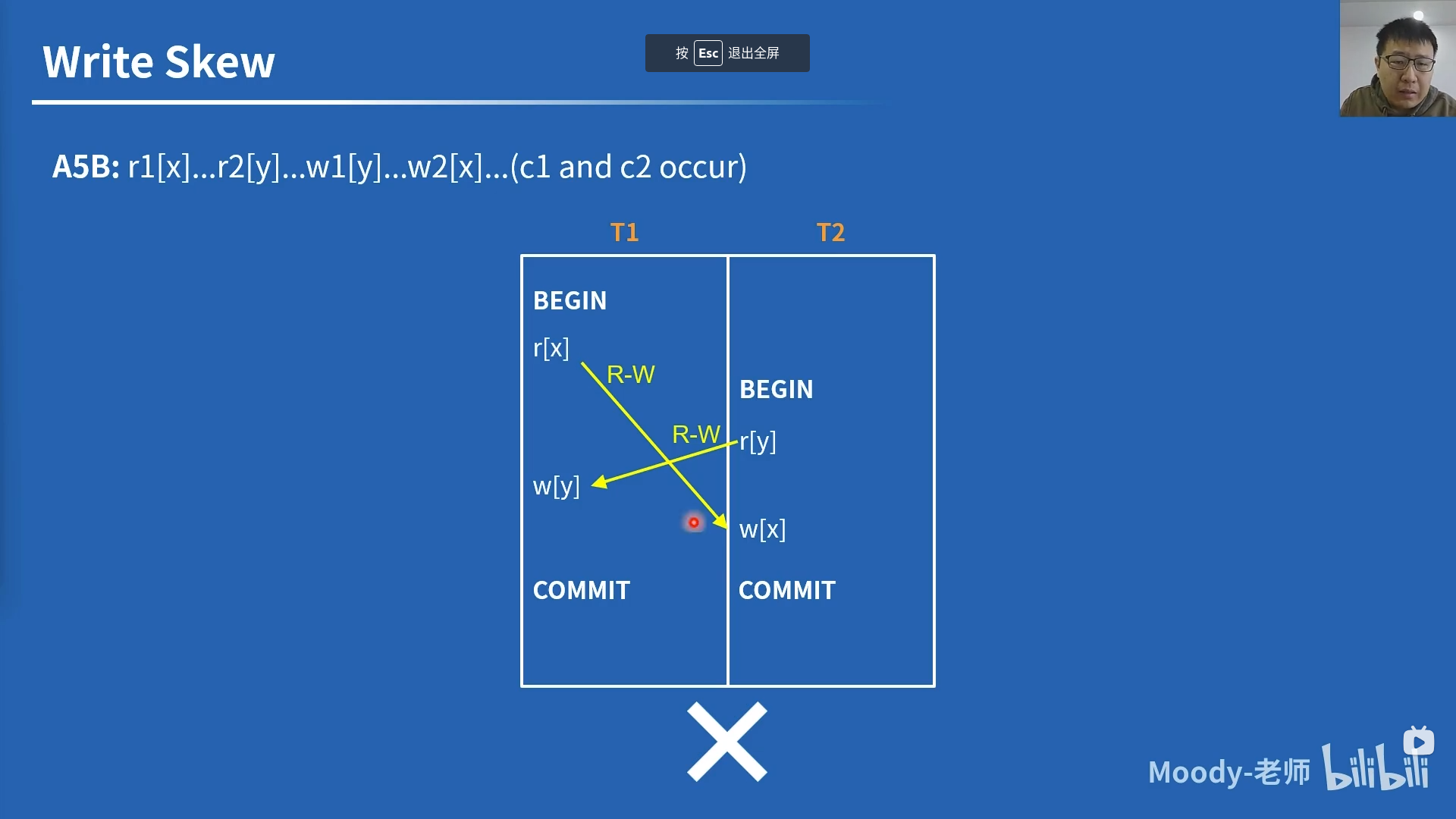
在图上的分析:可在计算机上高效实现
等效分析(交换等效操作)很难在计算机上高效实现。作者提出了基于图的事务依赖分析。
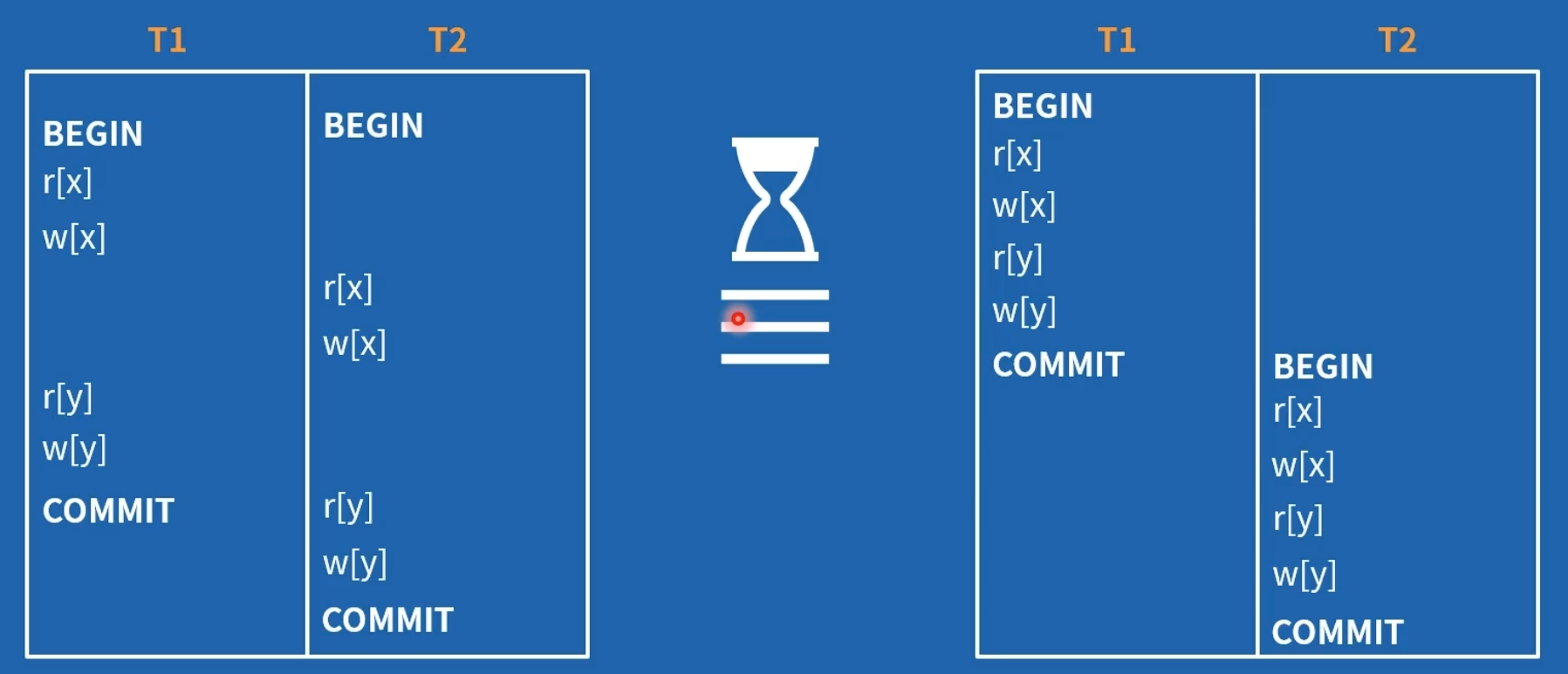
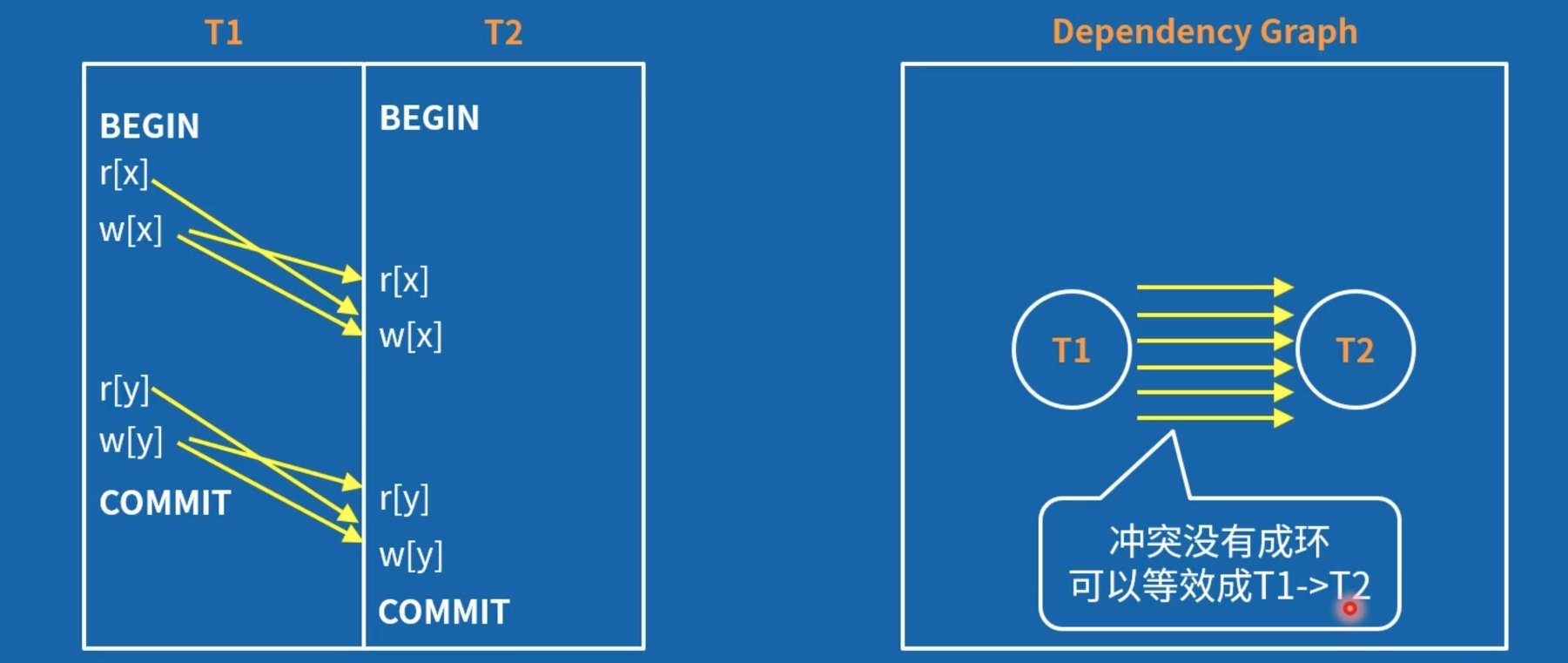
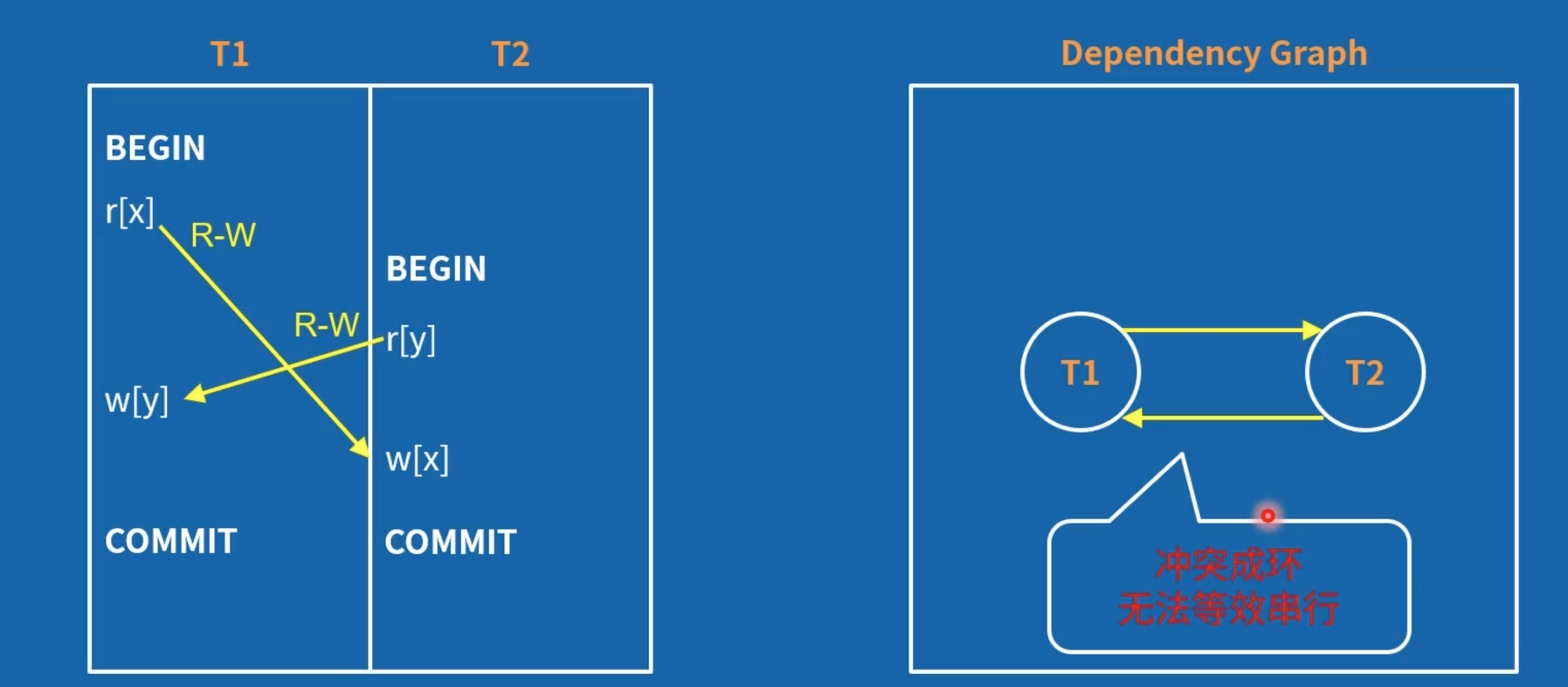
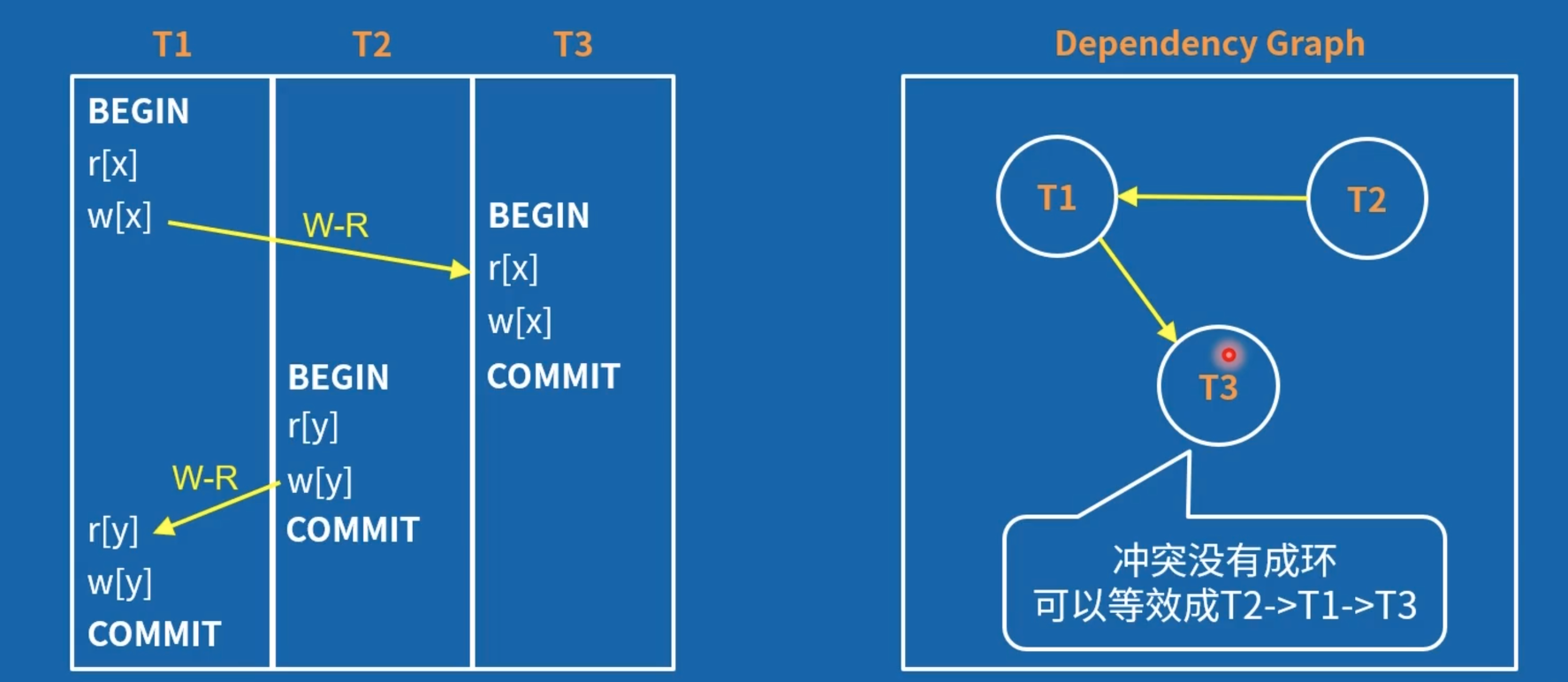
需要注意的是,基于冲突或基于图的依赖分析,会有错杀的情况,并不是完美的。即,有些本来符合隔离级别要求的事务会被回滚。
但错杀只影响效率,不影响数据库的正确。
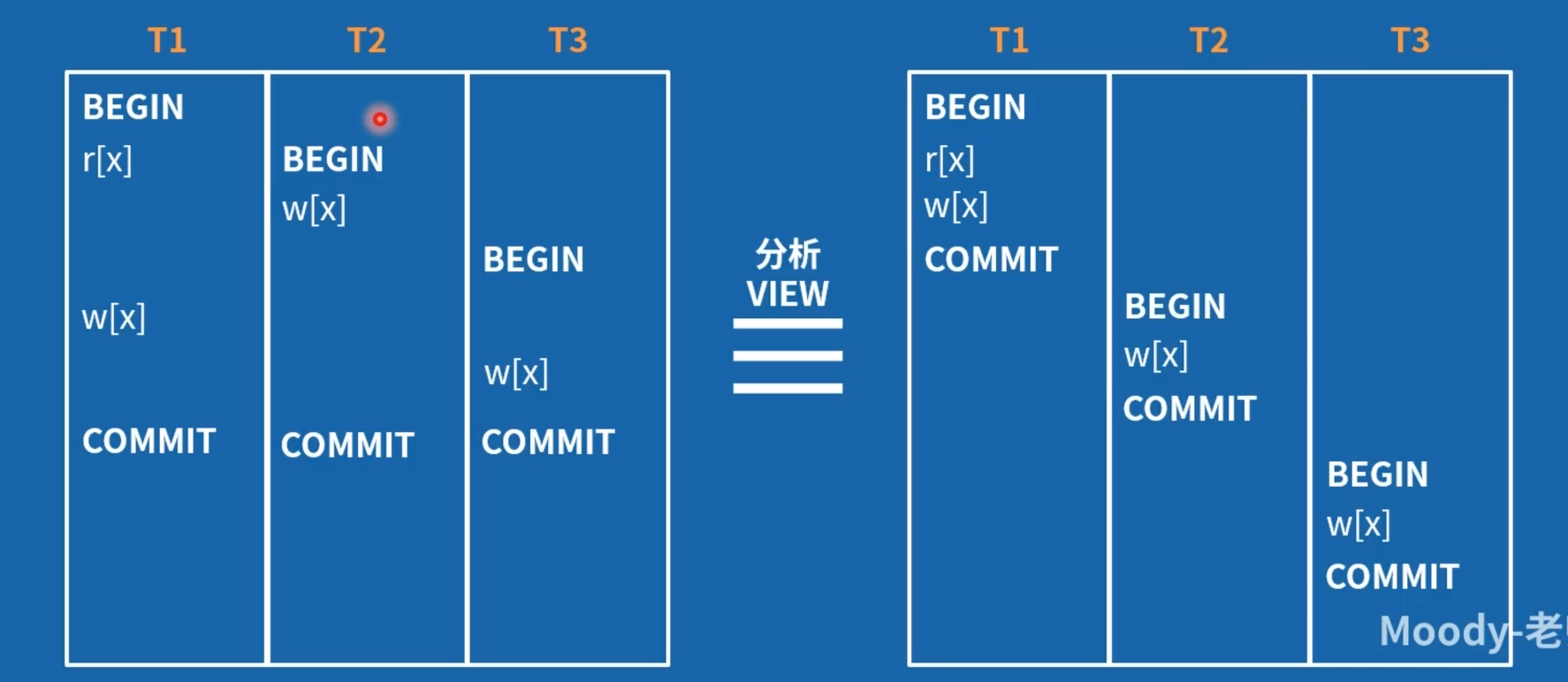
Adya 的论文给 SI 隔离级别实现 SER 提供了理论基础。
2008 年:SSI 横空出世
悉尼大学的 Cahill 等人发表文章《Serializable Isolation for Snapshot Databases》
痛点:基于依赖图的分析,实现起来依然复杂,且占用较多资源。如下图这样复杂的图终于有许多边,搜索成本高。
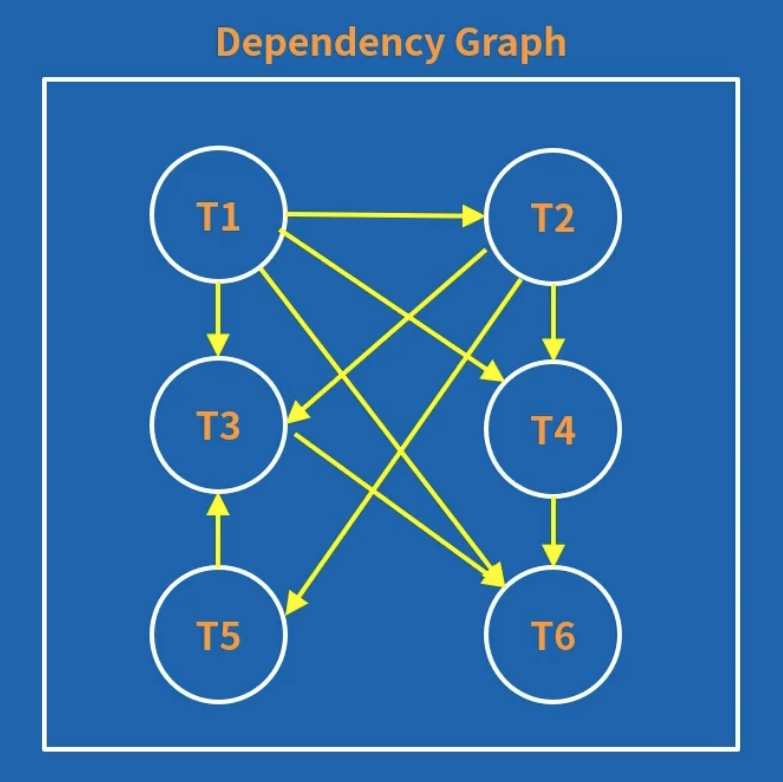
分析发现,所有成环的事务依赖中,
所以在 SI 下,可以不分析成环的问题,只判断有没有两个 R-W 边组成的断点(Pivot),选择一个事务回滚。
但是这种方法会造成更严重的错杀(False-positive)
但是错杀只会影响效率,并不影响数据库的正确,跟收益相比,还是可以接受的。
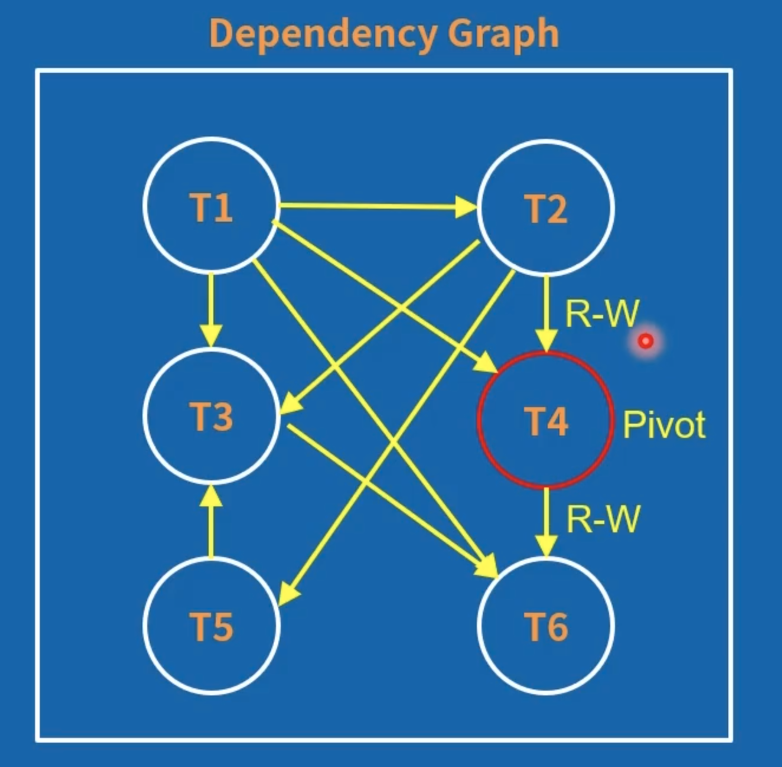
如果能实现上述想法,SI 隔离级别就解决了 A5B 问题,也就是所谓的“写偏序问题”
这样 SI 隔离级别就能升级为 Serializable 隔离级别。这种做法,被叫做 SSI 隔离级别:Serializable Snapshot Isolation
2012 年:终于落地
2012 年,业界知名的 PostgreSQL 数据库率先将 SSI 隔离级别商用。
PostgreSQL 开发了一个专门的 SSI Lock Manager,用来监控 RW 边的产生。
这套理论与实现比较适合单点式数据库,因为单点式数据库可以集中管理事务依赖信息。
对原生分布式数据库来说,由于没有事务的集中管理机制,无法完全按照 SSI 理论实现
2012 年:WSI 另辟蹊径
同年,雅虎的 Yabandeh 等人发表文章《A Critique of Snapshot Isolation》
首先给 SI 隔离级别起了个别名:Read Snapshot Isolation(RSI),也就是“读快照”
Yabandeh 认为,SI 可以叫做“读快照”:
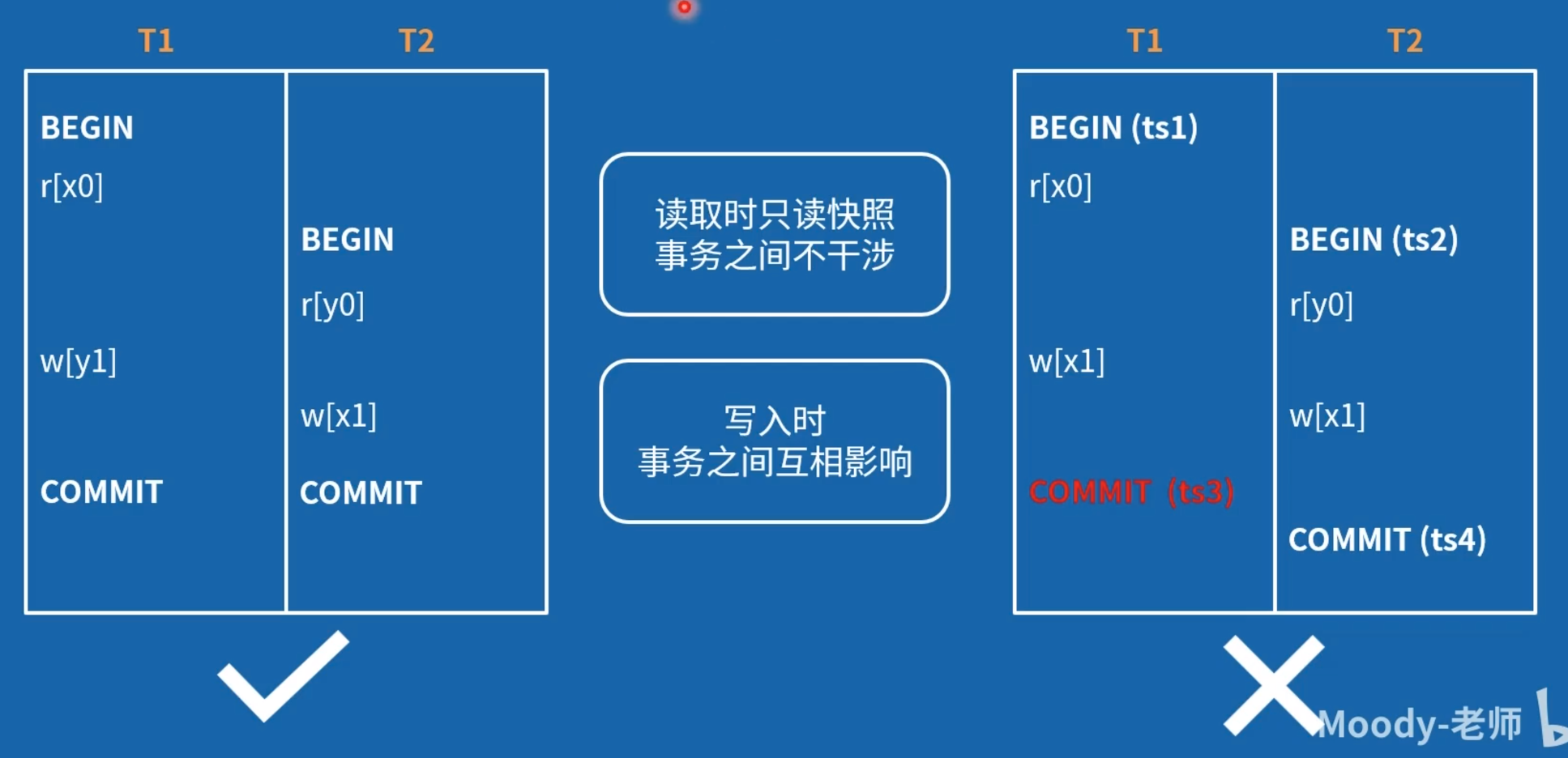
基于读快照,提出了写快照隔离级别(Write Snapshot Isolation, WSI) :
- 事务在修改数据时,直接基于事务启动时的数据库快照修改。
- 事务读取数据时,要维护读取的数据集,也就是记录自己读取过哪些数据。
- 事务提交时,要校验自己的读取数据集有没有被其他事务修改,如果有的话,则会造成 RW 依赖问题,进而有造成写偏序问题的风险,只要发现有 RW 依赖,事务立即 abort。
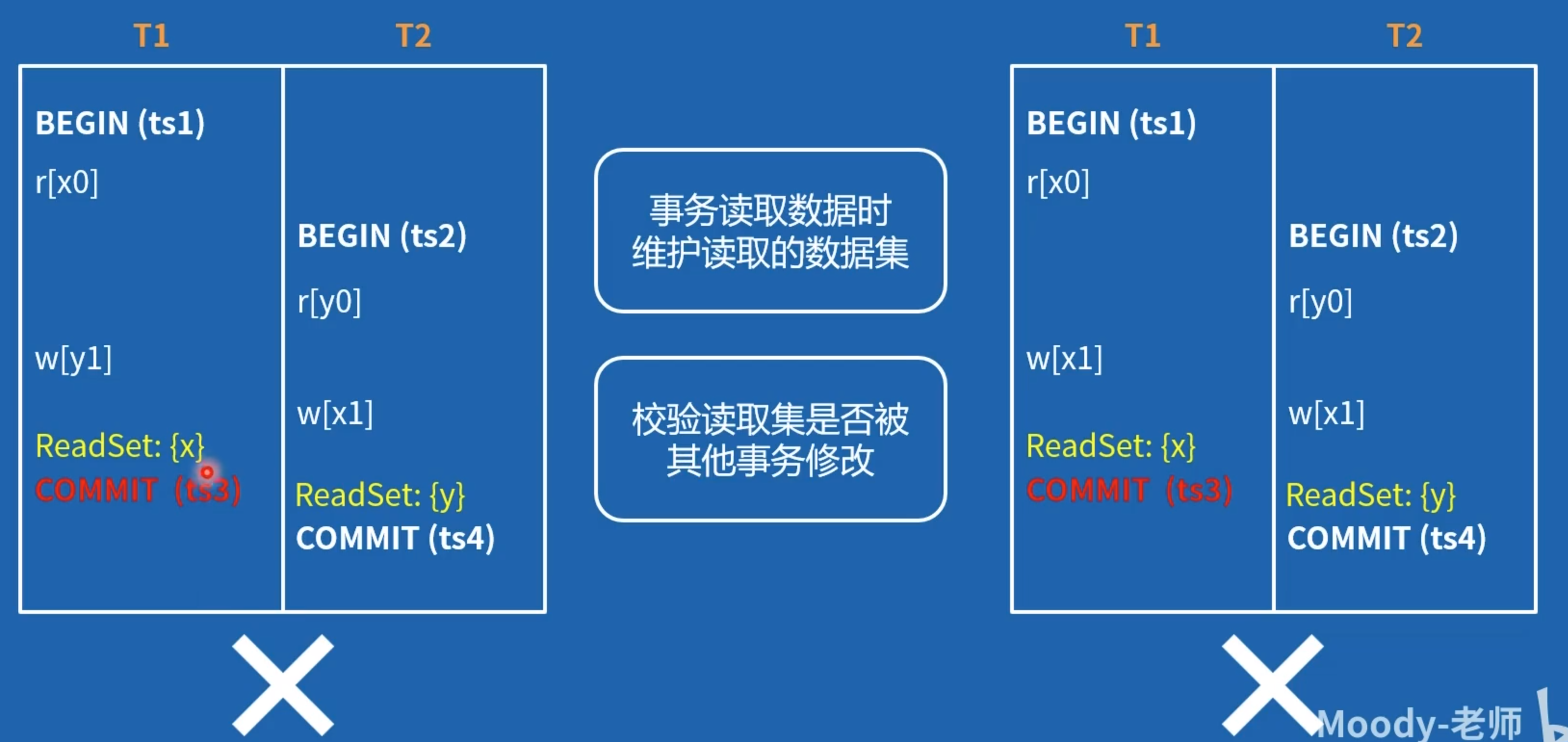
基于以上原理,可得 WSI 杜绝一切 RW 依赖 就不会有两条 RW 边相邻,更没有依赖成环问题了所以 WSI 也解决了 A5B 问题,可以认为实现了 SSI
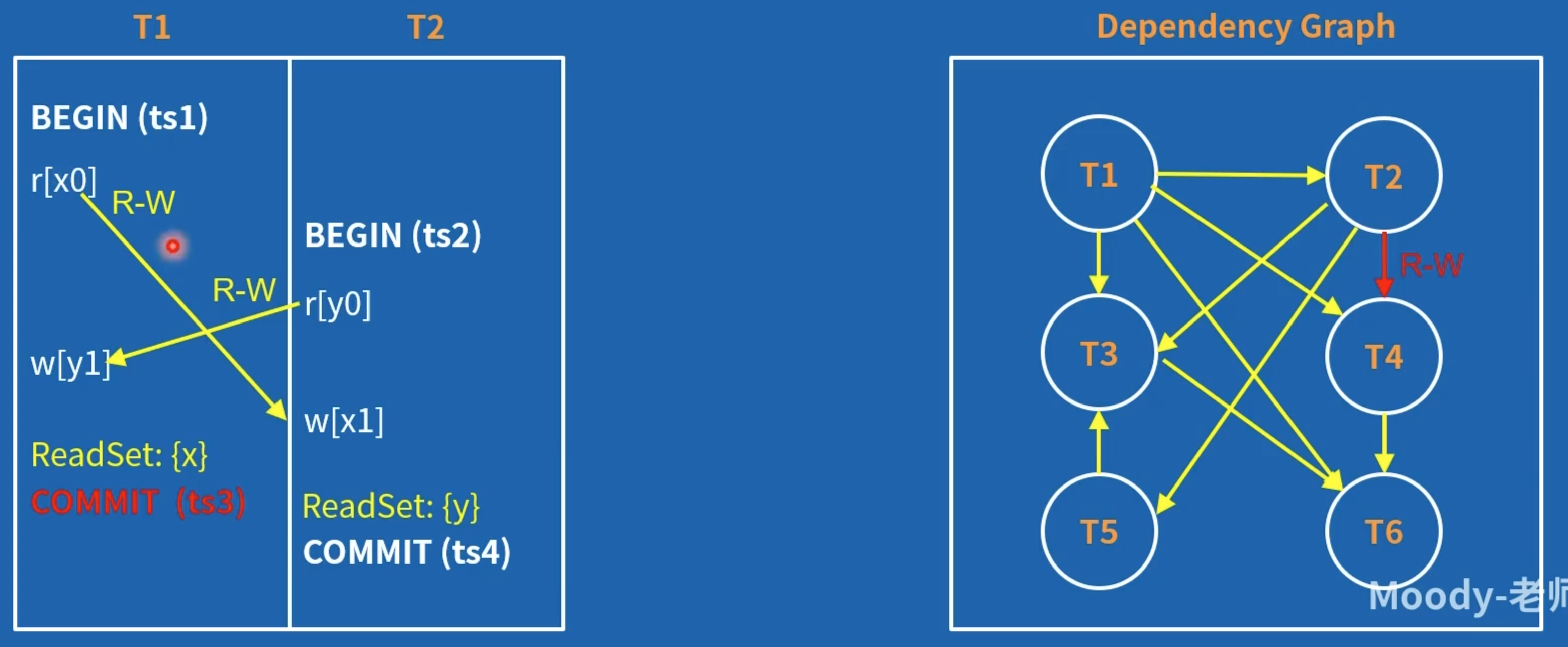
WSI 会造成更多的假阳性,造成更多本来可以并发的事务回滚
但是 WSI 的思想非常利于分布式事务的工程实现,并且不影响数据库的正确性
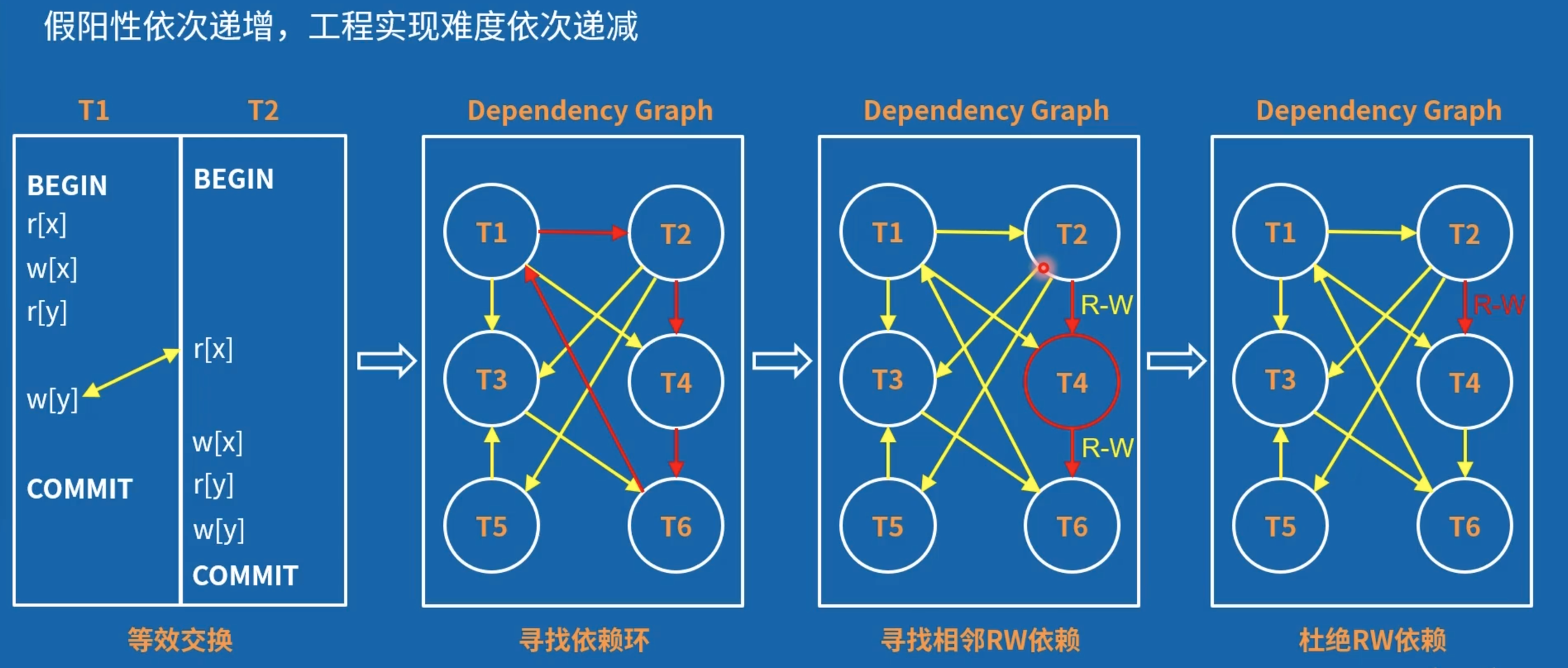
以下四种解决方案中,假阳性依次递增,工程实现难度依次递减。单点数据库一般用第三种,分布式数据库一般用第四种。
2014 年:CockroachDB 实现 WSI
WSI 理论给了 CockroachDB 很大的启发。
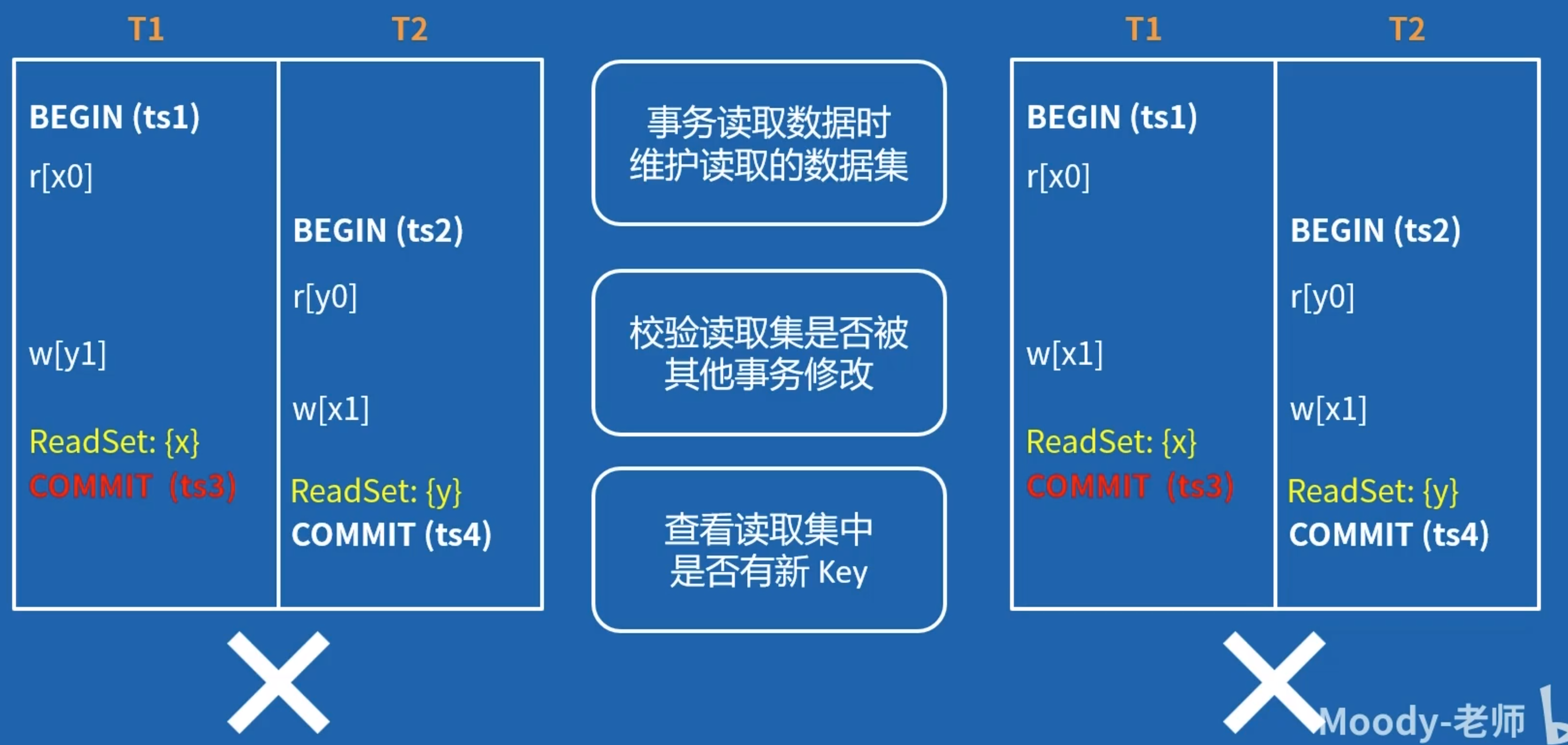
2014 年,CockroachDB 基于自己的 SI 隔离级别,完成了 SSI 隔离级别的实现 CockroachDB 在内存中维护了事务的读取 span 集,在提交时,会做以下工作:
- 查看自己读取的 span 中是否有其他事务的 intent,如果有的话,说明产生的 RW 依赖,本事务会 abort。(解决 A5B 写偏序问题)
- 查看自己读取的 span 中是否有比自己较新的 key,如果有的话,说明已经有时间戳较新的事务更新了自己的 span,且已经提交,本事务只能 abort 了。(解决 P3 幻读问题)
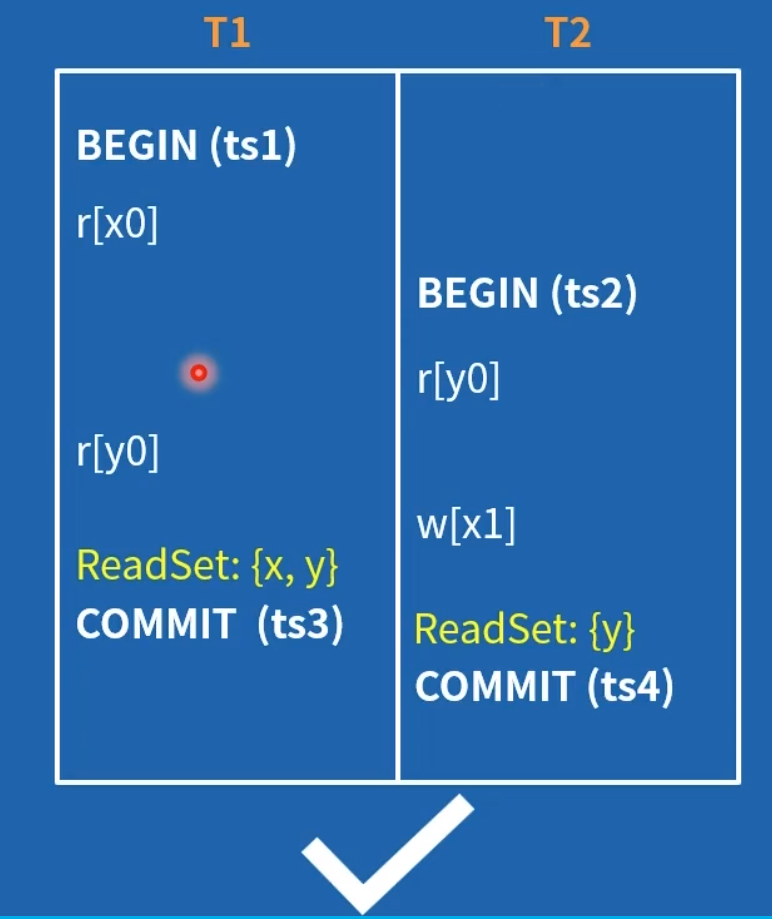
另外为了优化只读事务的性能,CockroachDB 对只读事务做了特殊处理:
如果一个事务只有读,没有任何写,就算产生 RW 依赖,不会导致 abort。
总结
- 数据库事务的发展史
- 事务问题的分析方法
- 单点式 SSI 隔离级别的理论与实现
- 分布式 SSI 隔离级别的理论与实现
Hal Berenson, Phil Bernstein, Jim Gray, Jim Melton, Elizabeth O'Neil, and Patrick O'Neil. 1995. A critique of ANSI SQL isolation levels. In Proceedings of the 1995 ACM SIGMOD international conference on Management of data (SIGMOD '95). Association for Computing Machinery, New York, NY, USA, 1–10. https://doi.org/10.1145/223784.223785↩︎

