摘要
商业数据库支持不同的隔离级别,以允许程序员在一致性和性能提升之间做出权衡。隔离级别在当前的 ANSI 标准中定义,但定义含糊不清,而为纠正该问题而提出的修订定义过于受限,因为它们仅允许悲观(锁定)实现。本文介绍了 ANSI 级别的新规范。我们的规范是可移植的;它们不仅适用于锁定实现,还适用于乐观和多版本并发控制方案。此外,与早期的定义不同,我们的新规范在所有级别上以正确且灵活的方式处理谓词。
Introduction
本文给出了 ANSI-SQL 隔离级别的新、精确定义 [6]。与以前的提案 [13、6、8] 不同,新定义既正确(它们排除了所有不良历史记录),又独立于实现。我们的规范允许使用各种并发控制技术,包括锁定、乐观技术 [20、2、5] 和多版本机制 [9、24]。因此,它们符合 ANSI-SQL 的目标,可以用作隔离标准。
隔离级别的概念最初是在 [13] 中以一致性程度的名称引入的。这项工作的目标是通过牺牲完全隔离的保证来为工作负载提供更好的并发性。[13] 中的工作和 [11] 建议的一些改进为 ANSI/ISO SQL-92 隔离级别定义 [6] 奠定了基础,其目标是制定一个独立于实现的标准。然而,后续论文 [8] 表明 [6] 中提供的定义含糊不清。该论文提出了避免歧义问题的不同定义,但如 [8] 所述,这些定义只是“锁定的伪装版本”,因此不允许乐观和多版本机制。因此,这些定义未能满足 ANSI-SQL 关于实现独立性的目标。
因此,我们有一个问题:该标准旨在独立于实现,但缺乏满足此目标的精确定义。实现独立性很重要,因为它为实现者提供了灵活性,从而可以提高性能。在某些环境中,乐观机制可以胜过锁定,例如大规模、广域分布式系统 [2, 15];乐观机制是移动环境的首选方案;Gemstone [22] 和 Oracle [24] 分别使用多版本乐观实现提供可序列化性和快照隔离。ANSI 标准不希望排除这些实现。例如,Gemstone 提供可序列化性,即使它不符合 [8] 中给出的基于锁定的规则。
本文提出了新的独立于实现的规范,以纠正现有定义中的问题。我们的定义涵盖了日常使用的较弱的隔离级别:大多数数据库供应商和数据库程序员利用低于可序列化级别的级别来实现更好的性能;事实上,READ COMMITTED 是某些数据库产品的默认设置,如果需要高性能,数据库供应商建议使用此级别而不是可序列化级别。我们的定义还使数据库供应商能够使用各种并发控制机制(包括锁定、乐观和多版本机制)开发不同级别的创新实现。此外,我们的规范在所有隔离级别上都能正确处理基于谓词的操作。
因此,本文做出了以下贡献:
- 它以独立于实现的方式指定了现有的 ANSI 隔离级别。这些定义是正确的(它们排除了所有不良历史记录)。它们对于可序列化也是完整的(它们允许所有良好历史记录);特别是,它们提供了冲突可序列化性 [9]。很难证明较低隔离级别的完整性,但我们可以轻松证明我们的定义比 [8] 中给出的定义更宽松。
- 我们的规范还以灵活的方式正确处理谓词;早期的定义要么基于锁,要么不完整 [8]。
我们的方法还可用于定义其他级别,包括商业级别(如游标稳定性 [11]、Oracle 的快照隔离和读取一致性 [24])以及新级别;例如,我们开发了一个名为 PL-2+ 的附加隔离级别,这是保证一致性读取和事务因果一致性的最弱级别。详细信息可在 [1] 中找到。
我们的定义是结合了对事务历史和图形的约束而给出的;我们规定了每个隔离级别的序列化图形中不同类型的循环。我们的图形类似于以前用于指定可序列化性 [9, 19, 14]、基于语义的正确性标准 [4] 和定义扩展事务模型 [10] 的图形。我们的方法是第一个将这些技术应用于定义 ANSI 和商业隔离级别的方法。我们的规范不同于 [9] 中提出的多版本理论,因为该理论仅描述了可序列化的条件,而我们为多版本系统指定了所有 ANSI/SQL-92 和其他商业隔离级别。此外,与我们的规范不同,它们的定义不考虑谓词。我们的工作也与 [8] 中提出的定义有很大不同,因为我们的规范处理多版本系统、乐观系统,并且在所有隔离级别以正确和灵活的方式处理谓词。
过去曾有人提出基于语义和扩展事务模型的宽松正确性条件 [10, 4, 17, 7]。相比之下,我们的工作重点是指定大量应用程序程序员正在使用的现有 ANSI 和商业隔离级别。
本文的其余部分组织如下。第 2 节更详细地讨论了以前的工作。第 3 节表明当前的定义不足并激发了我们开展工作的需要。第 4 节描述了我们的数据库模型。第 5 节提供了我们对现有 ANSI 隔离级别的定义。我们将在第 6 节中讨论我们已经完成的工作。
Previous work
隔离级别 [13] 的原始提案引入了四个一致性级别,即 0、1、2 和 3,其中 3 级与可序列化性相同。但是,该论文关注的是锁定方案,因此定义并非独立于实现。
但是,这项工作以及 Date [11] 提供的级别的细化构成了 ANSI/ISO SQL-92 隔离级别定义 [6] 的基础。ANSI 标准以实现独立性为目标,并且这些定义应该比早期的定义更少限制。所采取的方法是禁止某些类型的不良行为,称为现象;更严格的一致性级别不允许更多现象,而可序列化性不允许任何现象。隔离级别被命名为 READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE;其中一些级别旨在与 [13] 的级别相对应。
[8] 中的研究分析了 ANSI-SQL 标准,并展示了其隔离级别定义中的几个问题:一些现象含糊不清,而其他现象则完全缺失。然后它提供了新的定义。与 ANSI-SQL 标准一样,各种隔离级别都是通过禁止各种现象来定义的。[8] 提出的现象是:
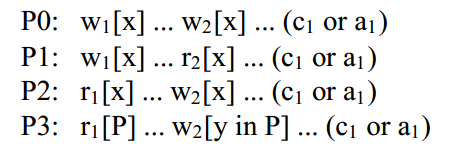
限制 P0(ANSI-SQL 定义中缺少该功能)要求如果未提交的事务 T1 已经修改了 x,则事务 T2 不能写入对象 x。这只是一个伪装的锁定定义,要求 T1 和 T2 获取长期写锁。(长期锁会一直持有,直到获取它们的事务提交;短期锁会在事务完成触发锁定尝试的读取或写入后立即释放。)类似地,限制 P1 要求 T1 获取长期写锁,T2 获取(至少)短期读锁,而限制 P2 则要求使用长期读写锁。
现象 P3 处理基于谓词的查询。限制 P3 要求事务 T2 不能通过插入、更新或删除一行来修改谓词 P,以至于对行的修改会更改未提交的事务 T1 基于谓词 P 执行的查询的结果;为了避免这种情况,T1 在谓词 P 上获取了一个长幻像读锁 [14]。
因此,这些定义仅允许在使用长/短读/写项/谓词锁的系统中发生的历史记录。由于锁定通过防止某些情况(例如,两个并发事务都修改同一个对象)来序列化事务,因此我们将这种方法称为预防性方法。

图 1 总结了 [8] 中定义的隔离级别,并将它们与基于锁的实现联系起来。因此,READ UNCOMMITTED 级别禁止 P0;READ COMMITTED 禁止 P0 和 P1;REPEATABLE READ 级别禁止 P0 - P2;SERIALIZABLE 禁止 P0 - P3。
Restrictiveness of preventative approach
我们现在展示预防方法是如何过于限制性的,因为它排除了乐观和多版本实现。正如所提到的,这种方法不允许在锁定方案中不会出现的所有历史记录,并防止冲突操作同时执行。
文献[8]的作者希望确保多对象约束(例如,约束条件如 \(x + y = 10\))不会被请求串行化隔离级别的事务观察到违反。他们展示了像 \(H_1\) 和 \(H_2\) 这样的历史记录被ANSI标准的一种解释(在串行化隔离级别)允许,尽管它们是非串行化的:
\[ H_1: r_1(x, 5) w_1(x, 1) r_2(x, 1) r_2(y, 5) c_2 r_1(y, 5) w_1(y, 9) c_1\\ H_2: r_2(x, 5) r_1(x, 5) w_1(x, 1) r_1(y, 5) w_1(y, 9) c_1 r_2(y, 9) c_2 \]
在这两种情况下,\(T_2\) 观察到了一个不一致的状态(它观察到不变量 \(x + y = 10\) 被违反)。这些历史记录不被预防方法允许;\(H_1\) 被 \(P_1\) 排除,\(H_2\) 被 \(P_2\) 排除。
乐观和多版本机制[2, 5, 9, 20, 22] 提供的串行化同样不允许非串行化的历史记录,如 \(H_1\) 和 \(H_2\)。然而,它们允许许多被 \(P_0\)、\(P_1\)、\(P_2\) 和 \(P_3\) 禁止的合法历史记录。因此,预防方法排除了这样的实现。此外,它排除了在实际实现中确实发生的历史记录。
现象 \(P_0\) 可能在乐观实现中发生,因为可以有许多未提交的事务同时修改本地副本的同一对象;如有必要,其中一些事务将被迫中止,以便提供串行化。因此,禁止 \(P_0\) 可能会排除乐观实现。
条件 \(P_1\) 排除了事务从未提交事务读取更新的情况。这种读取被许多乐观方案禁止,但在移动环境中可能是可取的,因为在客户端断开连接的情况下提交可能需要很长时间[12, 16];此外,在高流量热点[23]中,从未提交事务读取可能是可取的。例如,在历史记录 \(H_1\) 中,如果 \(T_2\) 读取了 \(T_1\) 对 \(x\) 和 \(y\) 的值,它可以按 \(T_1\) 之后的顺序进行串行化:
\[ H_{1'}: r_1(x, 5) w_1(x, 1) r_1(y, 5) w_1(y, 9) r_2(x, 1) r_2(y, 9) c_1 c_2 \] 上述历史记录可以在移动系统中发生,但 \(P_1\) 排除了这种情况。在这样的系统中,提交可以假设在客户端机器上“暂时”发生[12, 16];后续事务可能会观察到这些暂时事务的修改。当客户端重新连接到服务器时,其工作将被检查以确定一致性是否被违反,相关事务将被中止。当然,如果允许脏读,可能会发生级联中止,例如:
在历史记录 \(H_{10}\) 中,如果 \(T_1\) 中止,\(T_2\) 必须中止;这个问题可以通过使用补偿动作[18, 26, 19]来缓解。
禁止现象 \(P_2\) 排除了对已被未提交事务读取的对象的修改(\(P_3\) 排除了类似情况下的谓词)。在乐观实现中,未提交事务可能同时读取/写入同一对象。如果事务按正确的顺序提交,允许现象 \(P_2\) 是没有问题的。例如,在给定的历史记录 \(H_2\) 中,如果 \(T_2\) 读取了 \(x\) 和 \(y\) 的旧值,事务可以按 \(T_2; T_1\) 的顺序串行化:
$ H_{20}: r_2(x, 5) r_1(x, 5) w_1(x, 1) r_1(y, 5) r_2(y, 5) w_1(y, 9) c_2 c_1 $
实际上,预防方法的问题在于它将现象表达为单对象历史记录。然而,感兴趣的属性通常是多对象约束。为了避免此类约束的问题,现象需要对个别对象施加比必要更多的限制。我们的方法通过直接捕获多个对象的约束来避免这一困难。此外,预防方法的定义不适用于多版本系统,因为它们是用对象而不是版本来描述的。另一方面,我们的规范处理多版本和单版本历史记录。
文献[8]的方法仅允许提供运行事务和已提交事务相同保证的方案(基于锁的实现确实具有这一特性)。
Database model and transaction histories
现在我们来描述一下我们的数据库模型、事务历史和序列化图。我们使用了与 [9] 中介绍的类似的多版本模型。然而,与 [9] 不同的是,我们的模型还包含谓词。此外,我们允许在非锁定系统中可能出现的谓词行为。
Database model
数据库由可由事务读取或写入的对象组成;在关系数据库系统中,每一行或每组都是一个对象。每个事务读取和写入对象并指示这些操作发生的总顺序。
一个对象有一个或多个版本。但是,事务仅在对象方面与数据库交互;系统将对象的每个操作映射到该对象的特定版本。事务可以读取已提交、未提交甚至中止的事务创建的版本;某些隔离级别施加的约束将阻止某些类型的读取,例如,读取由中止的事务创建的版本。
当事务写入对象 x 时,它会创建 x 的新版本。事务 Ti 可以多次修改一个对象;它对对象 x 的第一次修改用 xi:1 表示,第二次修改用 xi:2 表示,依此类推。版本 xi 表示 Ti 在提交或中止之前对 x 执行的最终修改。事务的最后一个操作(提交或中止)指示其执行是否成功;每个事务最多有一个提交或中止操作。
已提交状态反映了已提交事务的修改。当事务 Ti 提交时,Ti 创建的每个版本 xi 都成为已提交状态的一部分,我们称 Ti 安装 xi ;系统确定 xi 相对于其他已提交版本的 x 的顺序。如果 Ti 中止,xi 不会成为已提交状态的一部分。
从概念上讲,初始已提交状态是运行特殊初始化事务 Tinit 的结果。事务 Tinit 创建数据库中将存在的所有对象;此时,每个对象 x 都有一个初始版本 xinit,称为未生成版本。当应用程序事务创建对象 x(例如,通过在关系中插入元组)时,我们将其建模为创建 x 的可见版本。因此,加载数据库的事务会创建插入对象的初始可见版本。当事务 Ti 删除对象 x(例如,通过从某个关系中删除元组)时,我们将其建模为创建特殊的死版本,即,在这种情况下,xi 是死版本。因此,对象版本可以分为三种类型 - 未出生、可见和死亡;这些版本之间的顺序关系将在第 4.2 节中讨论。
如果对象 x 从已提交的数据库状态中删除并稍后插入,我们将 x 的两个化身视为不同的对象。当事务 Ti 执行插入操作时,系统会选择一个以前从未被选择插入的唯一对象 x,并且如果提交,Ti 会创建 x 的可见版本。
我们假设对象版本永远存在于已提交状态以简化插入和删除的处理,即我们仅将插入/删除视为写入(更新)操作。实现只需要维护对象的可见版本,单版本实现一次只能维护一个可见版本。此外,实际系统中的应用程序事务仅访问可见版本。
New generalized isolation specifications
现在,我们介绍现有 ANSI 隔离级别的规范。我们通过研究原始定义 [13] 的动机和 [8] 中的现象所解决的问题来制定条件。这使我们能够开发独立于实现的规范,这些规范抓住了 ANSI 定义的本质,即我们不允许不良情况,同时允许各种实现允许的历史记录。
与以前的方法一样,我们将根据每个级别必须避免的现象来定义每个隔离级别。我们的现象以“G”为前缀,表示它们足够通用,可以允许锁定和乐观实现;这些现象被命名为 G0、G1 等(类似于 [6] 中的 P0、P1 等)。我们将新级别称为 PL 级别(其中 PL 代表“可移植级别”),以避免与 [8, 13] 中给出的隔离度混淆。
Isolation level PL-1
禁止现象 P0 可确保在 T1 仍未提交时,T1 执行的写入不会被 T2 覆盖(即,禁止脏写)。这种禁止似乎是可取的,原因似乎有两个:
- 它简化了从中止中恢复的过程。如果没有这个禁令,允许就地写入的系统就无法使用简单的撤消日志方法恢复中止事务的预状态。例如,假设 T1 更新 x(即 w1(x1)),T2 覆盖 x,然后 T1 中止。系统不得将 x 恢复到 T1 的预状态。但是,如果 T2 稍后中止,则必须将 x 恢复到 T1 的预状态,而不是 x1。
- 它仅根据事务的写入对事务进行序列化。例如,如果 T2 更新对象 x 并且 T1 覆盖 x,则不应有另一个对象 y 发生相反的情况,即 T2 的所有写入必须排在 T1 的所有写入之前或之后。
第一个原因似乎与所有系统无关。相反,它基于恢复的特定实现,并且其他实现也是可能的。例如,Thor 系统 [21] 为未提交的事务 Ti 维护对象的临时版本,并在 Ti 中止时丢弃这些版本。
基于写入序列化事务是一种有用的属性,因为它可以确保冲突事务的更新不会交错。现象 G0 捕获了此属性,我们将 PL-1 定义为不允许 G0 的级别:
Isolation level PL-2
Conclusions
Acknowledgements
我们要感谢 Chandra Boyapati、Miguel Castro、Andrew Myers 和编程方法小组的其他成员的评论。我们感谢 Dimitris Liarokapis 和 Elizabeth O’Neil 仔细阅读本文并帮助我们改进规范。我们还要感谢 Phil Bernstein、Jim Gray 和 David Lomet 的有益评论。

