关系型数据库的价值
阻抗失谐
基于关系代数(relational algebra),关系模型把数据组织成关系(relation)和元组(tuple)。元组是由键值对(name-value pair)构成的集合,而关系则是元组的集合。
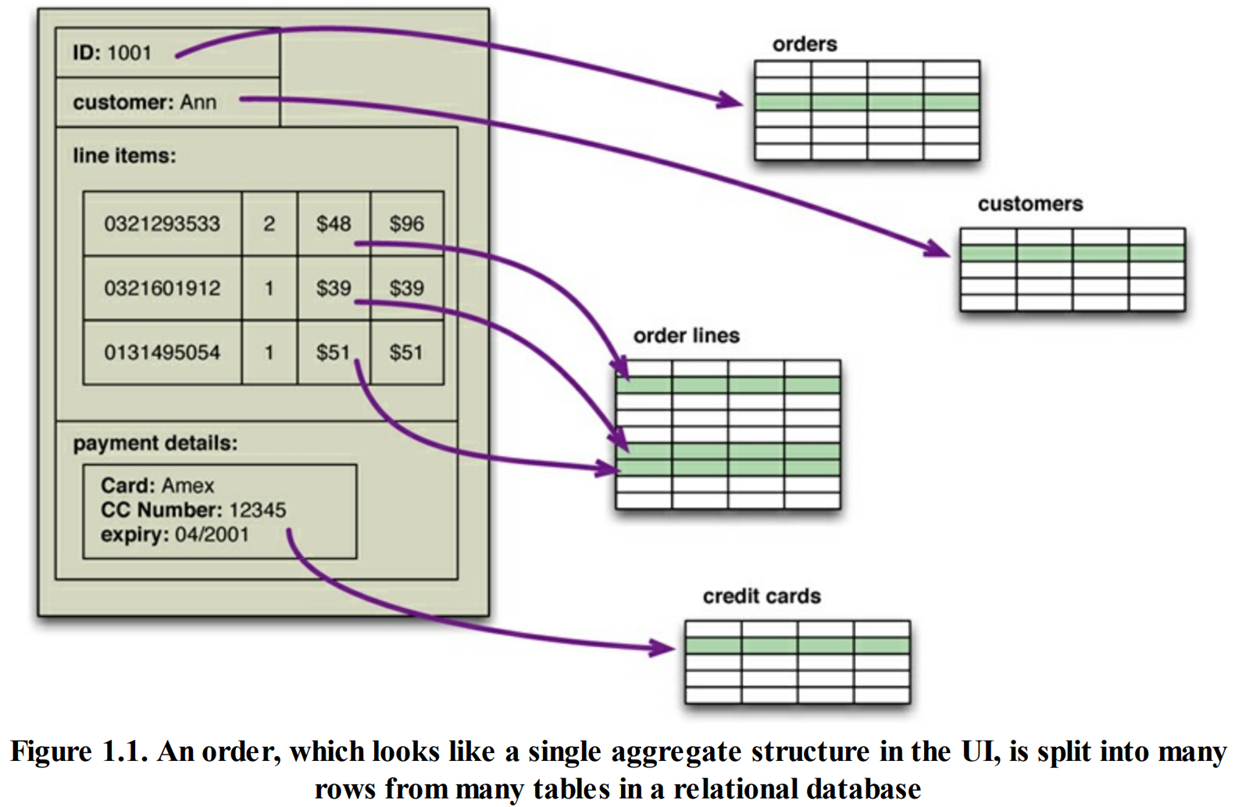
SQL 操作所使用及返回的数据都是关系元组不能包含嵌套记录(nested record)或列表(list)等任何结构。而内存中的数据结构则无此限制,它可以使用的数据组织形式比关系更丰富。
关系模型和内存中的数据结构之间存在差异。这种现象通常称为阻抗失谐。
如果在内存中使用了较为丰富的数据结构,那么要把它保存到磁盘之前,必须先将其转换成关系形式。于是就发生了阻抗失谐:需要在两种不同的表示形式之间转译。
解决方法:
- 面向对象数据库
- 对象-关系映射框架(object-relational mapping framework)
新的问题:
- 查询性能问题
- 集成问题
应用程序数据库与集成数据库
集成数据库
SQL 充当了应用程序之间的一种集成机制。数据库在这种情况下成了集成数据库(integration database)。
- 通常由不同团队所开发的多个应用程序,将其数据存储在一个公用的数据库中。
- 所有应用程序都在操作内容一致的持久数据,提高了数据通信的效率
- 为了能将很多应用程序集成起来,数据库的结构比单个应用程序所要用到的结构复杂得多
- 如果某个应用程序想要修改存储的数据,那么它就得和所有使用此数据库的其他应用程序相调。
- 各种应用程序的结构和性能要求不尽相同,数据库通常不能任由应用程序更新其数据。为了保持数据库的完整性,我们需要将这一责任交由数据库自身负责。
应用程序数据库
将数据库视为应用程序数据库(application database),其内容只能由一个应用程序的代码库直接访问。由于只有开发应用程序的团队才需要知道其结构,模式的维护与更新就更容易了。由于应用程序开发团队同时管理数据库和应用程序代码,因此可以把维护数据库完整性的工作放在应用程序代码中。
在使用应用程序数据库后,由于内部数据库与外部通信服务之间已经解耦,所以外界并不关心数据如何存储,这样就可以选用非关系型数据库了。关系型数据库的许多特性,诸如安全性等,可以交给使用该数据库的外围应用程序(enclosing application)来做。
蜂拥而来的集群
纵向扩展(scale up):功能强大的计算机、更多的处理器、磁盘存储空间和内存。但成本高、扩展尺度有限。
横向扩展(scale out):采用由多个小型计算机组成的集群。集群中的小型机使用性价比较高的硬件,降低扩展所需的成本。
关系型数据库并不是设计给集群用的。
NoSQL 登场
NoSQL 没有规范的定义,一般解释为开源分布式的非关系型数据库。
各种 NoSQL 数据库的共同特性是:
- 不使用关系模型
- 在集群中运行良好
- 关系型数据库使用 ACID 事务来保持整个数据库的一致性,而这种方式本身与集群环境相冲突
- NoSQL 数据库为处理并发及分布问题提供了众多选项
- 开源
- 适用于 21 世纪的互联网公司
- 无模式
- 不用事先修改结构定义,即可自由添加字段
- 这在处理不规则数据和自定义字段时非常有用

