关系型数据库试图通过强一致性来避免各种不一致的问题。NoSQL 领域则讨论 CAP 定理和最终一致性。
更新一致性
- 写冲突:当两个客户端试图同时修改一份数据时
- 读写冲突:当某客户端在另一个客户端执行写入操作的过程中读取数据时
解决方式:
- 悲观处理:使用写入锁避免冲突,大幅降低系统反应能力
- 乐观处理:在事后检测冲突并将其修复,条件更新(conditional update):任意客户在执行更新操作之前,都要先测试数据的当前值和其上一次读入的值是否相同
- 乐观处理:保存冲突数据 。用户自行合并(merge)或自动合并(面向特定领域),用于分布式版本控制系统
读取一致性
- 逻辑一致性:不同的数据项放在一起,含义符合逻辑(即在逻辑上是一个一致状态)
- 复制一致性:要求从不同副本中读取同一个数据项时,所得到的值相同。网络环境下该不一致窗口会延长
- 最终一致性:写入操作已经传播至所有节点
- 会话一致性:在用户会话内部保持照原样读出所写内容的一致性,即能立刻读到写入的内容
- 黏性会话:某会话绑定到某个节点,缺点是会降低负载均衡器( load balancer)效能
- 使用版本戳,确保同数据库的每次交互操作中,都包含会话所见的最新版本戳
使用黏性会话和主从复制来保证会话一致性时,由于读取与写入操作分别发生在不同节点,那么想保证这一点会比较困难。
- 将写入请求先发给从节点,由它负责将其转发至主节点,并同时保持客户端的会话一致性。
- 在执行写入操作时临时切换到主节点,并且在从节点尚未收到更新数据的这一段时间内,把读取操作都交由主节点来处理。
放宽一致性约束
隔离级别
使用事务达成强一致性,事务系统通常具有放松隔离级别(isolation level)的功能,以允许查询操作读取尚未提交的数据。
- 读未提交,一个事务可以读取另一个未提交事务的数据。存在脏读
- 读已提交,一个事务要等另一个事务提交后才能读取数据。存在不可重复读
- 可重复读,在开始读取数据(事务开启)时,不再允许修改操作。存在幻读
- 可串行化,事务串行化顺序执行。严格一致性,效率是一个问题
CAP 定理
CAP 定理:给定一致性(Consistency)、可用性(Availability)、分区耐受性(Partition tolerance) 这三个属性,我们只能同时满足其中两个属性。
- 可用性:如果客户可以同集群中的某个节点通信,那么该节点就必然能够处理读取及写入操作。
- 分区耐受性:如果发生通信故障,导致整个集群被分割成多个无法互相通信的分区时(这种情况也叫脑裂,split brain),集群仍然可用。
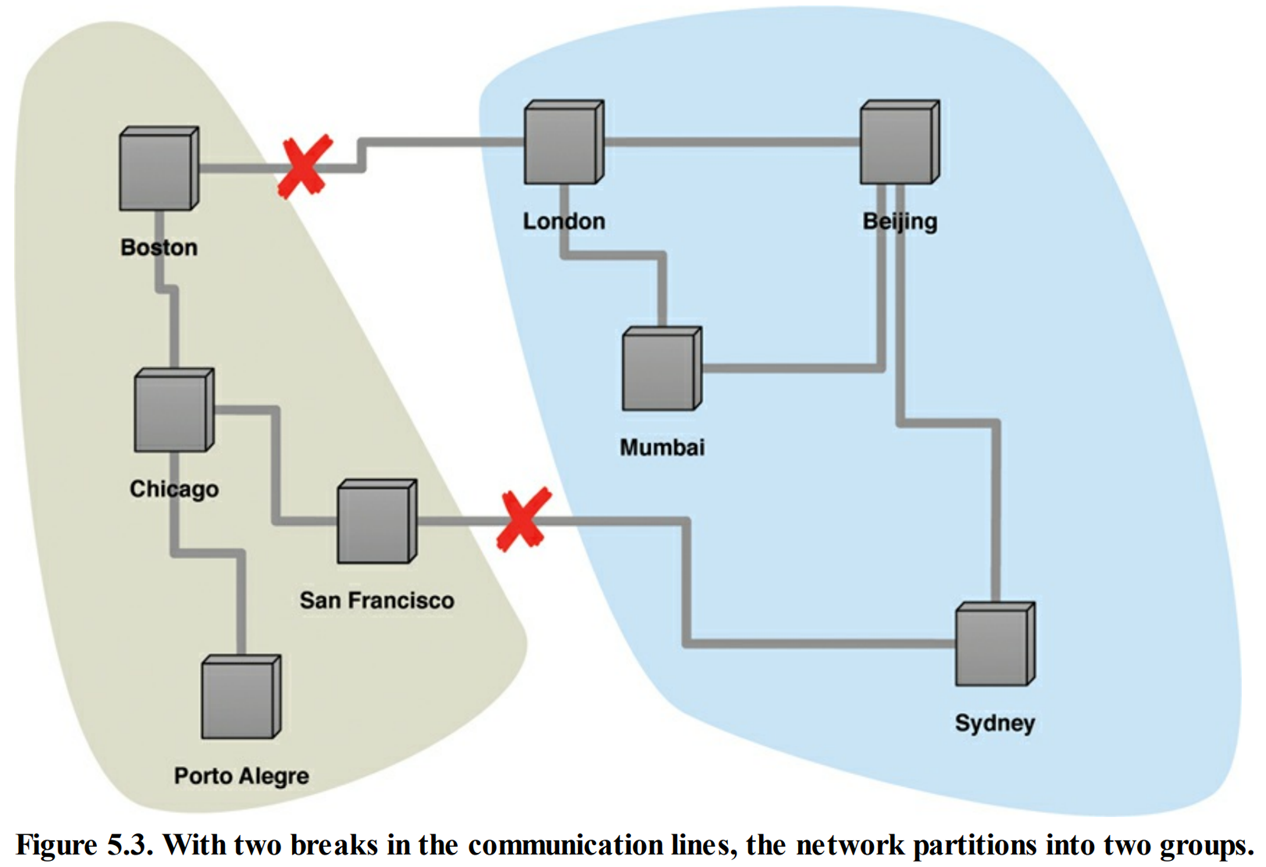
CA 系统,也就是具备一致性(Consistency)可用性(Availability), 但却不具备分区耐受性的系统。单服务器是 CA 系统。大多数关系型数据库属于此系统。
CA 集群无法保证分区耐受性,这使得一旦分区发生,所有节点必须停止运作。CAP 中的,可用性定义为系统中某个无故障节点所接收的每一条请求, 无论成功或失败,都必将得到响应。介于此时所有节点均为故障节点,不违反 CAP 中的可用性。
尽管 CAP 定理经常表述为三个属性中只能保有两个,实际上当系统可能会遭遇分区状况时(比如分布式系统),需要在一致性与可用性之间进行权衡。这并不是个二选一的决定,通常来说,我们都会略微舍弃一致性,以获取某种程度的可用性。这样的系统,既不具备完美的一致性,也不具备完美的可用性,但是能够满足需要
放宽持久性约束
与关系型数据库所支持的 ACID 事务不同,NoSQL 系统具备 BASE 属性:
- 基本可用,Basically Available
- 柔性状态,Soft state
- 最终一致性,Eventual consistency
ACID 与 BASE 不是非此即彼的关系,两者之间存在着多个逐渐过渡的权衡方案可选。
在权衡分布式数据库的一致性时,与其考虑如何权衡一致性与可用性,不如思考怎样在一致性与延迟(latency)之间取舍。
参与交互操作的节点越多,一致性就越好。然而,每新增一个节点,都会使交互操作的响应时间变长。可用性可以视为能够忍受的最大延迟时间,一旦延迟过高,我们就放弃操作,并认为数据不可用。这样一来,就和 CAP 定理对可用性所下的定义相当吻合了。
数据库大部分时间都在内存中运行,更新操作也直接写入内存,并且定期将数据变更写回磁盘:
- 可以大大提高响应请求的速度
- 代价在于,一旦服务器发生故障,任何尚未写回磁盘的更新数据都将丢失。
多用户的会话状态信息。
- 会话数据就算丢失,与应用系统效率相比,也不过是个小麻烦。这时可以考虑非持久性写入操作(nondurable write)。
- 可以在每次发出请求时,指定该请求所需的持久性。从而,把某些极为重要的更新操作立刻写回磁盘。
捕获物理设备的遥测数据(telemetric data)。就算最近的更新数据可能会因为服务器发生故障而丢失,也还是选择把快速捕获数据放在首位。
如一个节点处理完更新操作之后,在更新数据尚未复制到其他节点之前就出错了,那么则会发生复制持久性(replication durability) 故障。
假设有一个采用主从式分布模型的数据库,在其主节点出错时,它会自动指派一个从节点作为新的主节点。
- 若主节点发生故障,则所有还未复制到其他副本的写入操作就都将丢失。
- 一旦主节点从故障中恢复过来,那么,该节点上的更新数据就会和发生故障这段时间内新产生的那些更新数据相冲突
- 我们把这视为一个持久化问题,因为主节点既然已经接纳了这个更新操作,那么用户自然就会认为该操作已经顺利执行完,但实际上,这份更新数据却因为主节点出错而丢失了
解决方案:
- 不重新指派新的主节点,在主节点出错之后迅速将其恢复
- 确保主节点在收到某些副本对更新数据的确认之后,再告知用户它已接纳此更新,
- 从节点发生故障时,集群不可用
- 拖慢更新速度。
与处理持久性的基本手段类似,也可以针对单个请求来指定其所需的持久性。
仲裁
写入仲裁
处理请求所的节点越多,避免不一致问题的能力就越强,要想保强一致性(strong consistency), 需要使用多少个节点才行?
- 对等式分布模型:如果发生两个相互冲突的写入操作,那么只有其中一个操作能为超过半数的节点所认可,\(W > N / 2\) 。即,参与写入操作的节点数(W),必须超过副本节点数(N)的一半。副本个数又称为复制因子
- 主从式分布模型:只需要向主节点中写入数据
读取仲裁
想要保证能够读到最新数据,必须与多少个节点联系才行?
- 对等式分布模型:只有当 \(R+W>N\) 时,才能保证读取操作的强一致性。其中,执行读取操作时所需联系的节点数(R),确认写入操作时所需征询的节点数(W),以及复制因子(N)
- 主从式分布模型:只需从主节点中读取数据
复制因子
一个集群有 100 个节点,然而其复制因子可能仅仅是 3,因为大部分数据都分布在各个"分片之中。
将复制因子设为 3,就可以获得足够好的故障恢复能力了。
- 如果只有一个节点出错,那么仍然能够满足读取与写入所需的最小法定节点数。
- 若是有自动均衡(automatic rebalancing)机制,那么用不了多久,集群中就会建立起第三个副本,在替代副本建立好之前,再次发生副本故障的概率很小。
需要在一致性与可用性之间权衡,参与某个操作的节点数,可能会随着该操作的具体情况而改变。
- 在写入数据时,根据一致性与可用性这两个因素的重要程度,有一些更新操作可能需要获得足够的节点支持率才能执行,而另外一些则不需要。
- 与之相似,某些读取操作可能更看中执行速度,而可以容忍过时数据,此时,它就可以少联系几个节点。
通常需要协调考虑读、写两种情况:
- 假设需要快速且具备强一致性的读取操作,那么写入操作就要得到全部节点的确认才行,这样的话,只需联系一个节点,就能完成读取操作了(N=3,W=3,R=1)
- 但是,这个方案意味着,写入操作会比较慢,因为它们必须得到全部三个节点确认之后,才能执行,而且此时连一个节点都不能出错。

