聚合
在领域驱动设计中,把一组相互关联的对象视为一个整体单元来操作,而这个单元就叫聚合(aggregate)。
- 通过原子操作(atomic operation)新聚合的值(含一致性管理)。
- 以聚合为单位与数据存储通信
- 在集群中操作数据库时,用聚合为单位来复制和分片
- 由于程序员经常通过聚合结构来操作数据,故而采用聚合也能让其工作更为轻松
- 面向聚合操作数据时所用的单元,其结构比元组集合复杂得多
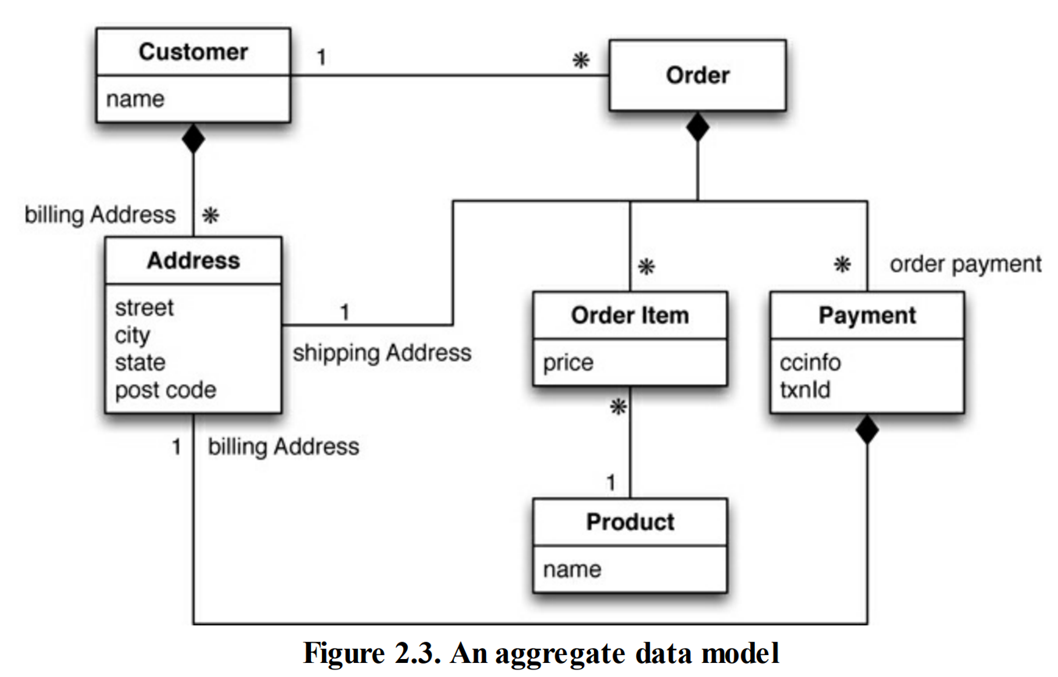

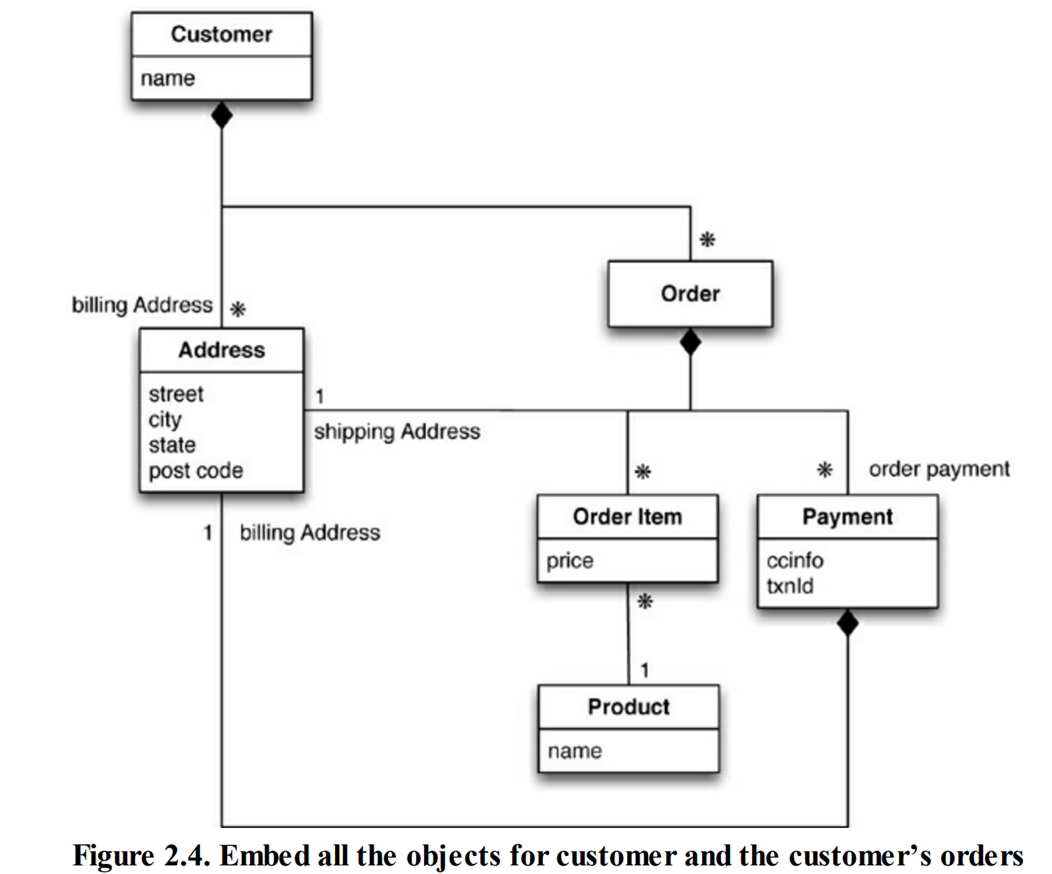
我们也可以将产品名称直接写入订单项,因为我们希望在数据交互时尽量减少所需访问的聚合个数。

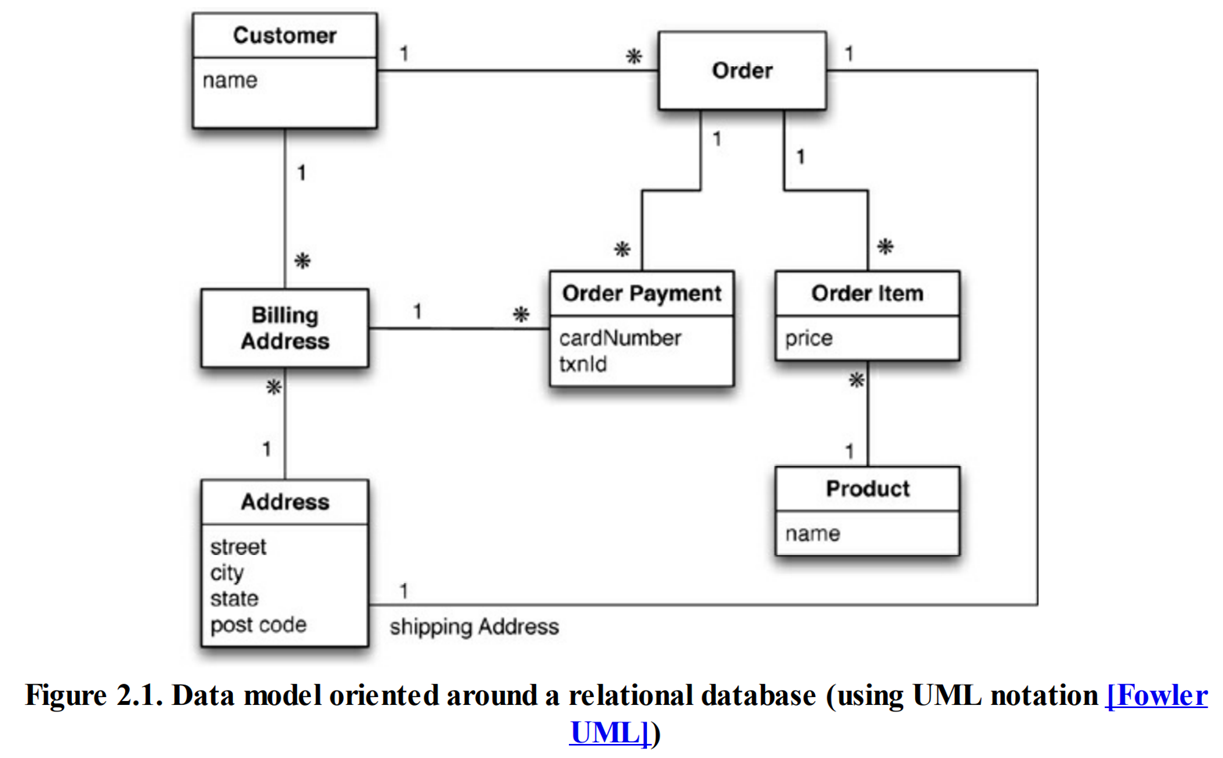
关系型数据库的数据模型中,没有聚合这一概念,因此我们称之为聚合无知(aggregate- ignorant)。图数据库"也是聚合无知的。
聚合反应数据操作的边界,很难在共享数据的多个场景中正确划分,对某些数据交互有用的聚合结构,可能会阻碍另一些数据交互。
选择面向聚合模型的决定性因素,就在于它非常适合在集群上运行。
键值数据模型与文档数据模型
键值数据库的聚合不透明,只包含一些没有太多意义的大块信息。
- 聚合中可以存储任意数据。数据库可能会限制聚合的总大小,但除此之外,其他方面都很随意
- 在键值数据库中,要访问聚合内容,只能通过键来查找
文档数据库中,可以看到其结构。
- 限制其中存放的内容,它定义了其允许的结构与数据类型
- 能够更加灵活地访问数据。通过用聚合中的字段查询,可以只获取一部分聚合,而不用获取全部内容
- 可以按照聚合内容创建索引
列族存储
大部分数据库都以行为单元存储数据。然而,有些情况下写入操作执行得很少,但是经常需要一次读取若干行中的很多列。此时,列存储数据库将所有行的某一组列作为基本数据存储单元。


