Hadoop
Hadoop 是一个开发和运行大规模数据分析程序的软件平台,隶属 Apache 的一个开源软件框架,在大量普通服务器组成的集群中对海量数据进行分布式计算。
主要模块:
- Hadoop Common
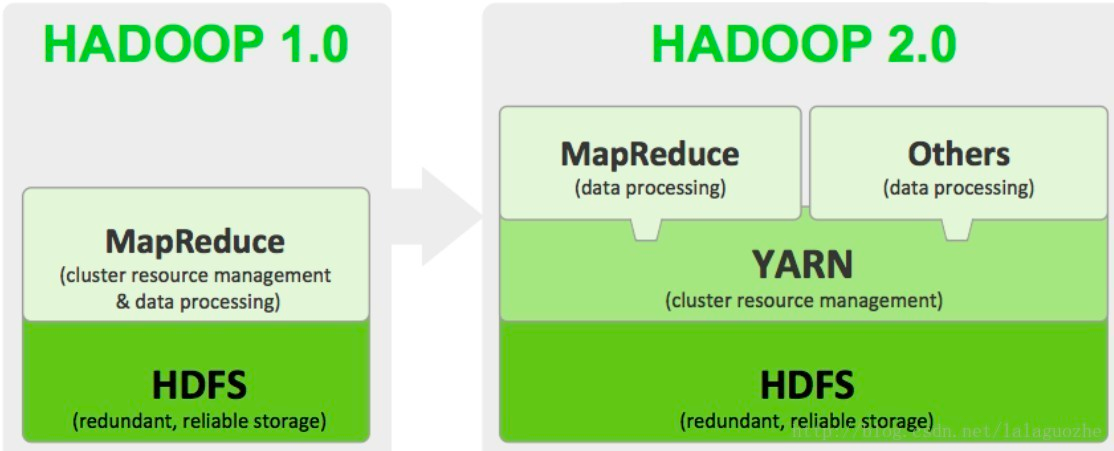
- Hadoop Distributed File System(HDFS)
- Hadoop YARN
- Hadoop MapReduce
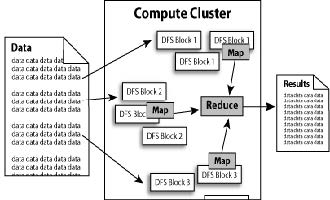
Hadoop 计算过程
Hadoop 发展简史
- Hadoop 起源于 Apache Nutch,后者是一个开源的网络搜索擎,本身也是由 Lucene 项目的一部分。
- Nutch 项目开始于 2002 年,一个可工作的抓取工具和搜索系统很快浮出水面。
- 2004 年,Google 发表了论文,向全世界介绍了 MapReduce。
- 2005 年初,Nutch 的开发者在 Nutch 上有了一个可工作的 MapReduce 应用,到当年年中,所有主要的 Nutch 算法被移植到使用 MapReduce 和 NDFS 来运行。Nutch 中的 NDFS 和 MapReduce 实现的应用远不只是搜索领域。
- 在 2006 年 2 月,他们从 Nutch 转移出来成为一个独立的 Lucene 子项目,成为 Hadoop。
- 在 2008 年 2 月,雅虎宣布其搜索引擎产品部署在一个拥有 1 万个内核的 Hadoop 集群上。
- 2008 年 4 月,Hadoop 打破世界纪录,成为最快排序 1TB 数据的系统。运行在一个 910 节点的群集,Hadoop 在 209 秒内排序了 1TB 的数据(还不到三分半钟),击败了前一年的 297 秒冠军。同年 11 月,谷歌在报告中生成,它的 MapReduce 实现执行 1TB 数据的排序只用了 68 秒。在 2009 年 5 月,有报道宣称 Yahoo 的团队使用 Hadoop 对 1TB 的数据进行排序只花了 62 秒时间。
Hadoop 的作用与功能
Hadoop 采用了分布式存储方式,提高了读写速度,并扩大了存储容量。采用 MapReduce 来整合分布式文件系统上的数据,可保证分析和处理数据的高效。与此同时,Hadoop 还采用存储冗余数据的方式保证了数据的安全性。
Hadoop 中 HDFS 的高容错特性,以及它是基于 Java 语言开发的,这使得 Hadoop 可以部署在低廉的计算机集群中,同时不限于某个操作系统。Hadoop 中 HDFS 的数据管理能力,MapReduce 处理任务时的高效率,以及它的开源特性,使其在同类的分布式系统中大放异彩,并在众多行业和科研领域中被广泛采用。
MapReduce 和传统关系型数据库的比较
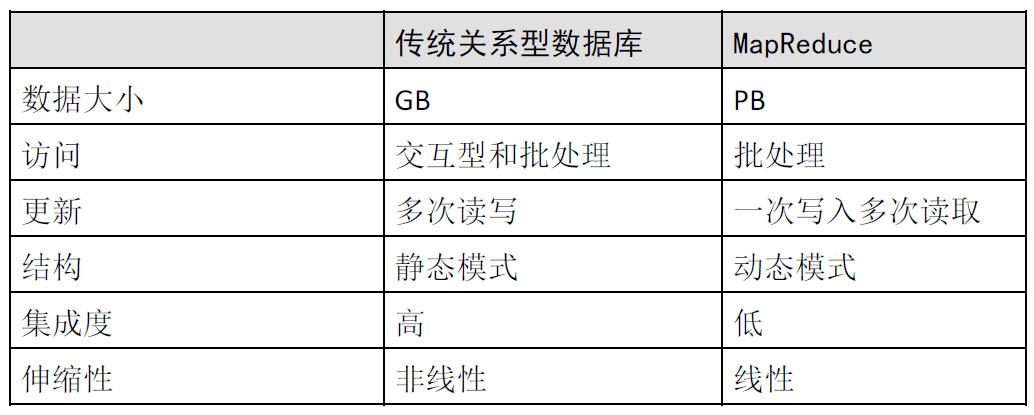
Hadoop 结论
二者互相融合是一种趋势
| 传统 RDBMS | MapReduce | |
|---|---|---|
| 效率 | 低(通过排序和合并来重建数据库) | 高(更新大部分数据库数据的效率高于 B 树的更新) |
| 数据集特点 | 持续更新 | 数据被一次写入,多次读取 |
| 数据格式 | 结构化数据 | 非结构化或半结构化数据(避免规范化带来的非本地读问题) |
| 应用领域 | 点查询、更新 | 批处理 |
Hadoop 的优点
Hadoop 是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,具有以下优点:
- Hadoop 是可靠的:因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
- Hadoop 是高效的:因为它以并行的方式工作,通过并行处理加快处理速度。
- Hadoop 是可伸缩的:能够处理 PB 级数据。
- Hadoop成本低:依赖于廉价服务器:因此它的成本比较低,任何人都可以使用。
- 运行在Linux 平台上:Hadoop 带有用 Java 语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。
- 支持多种编程语言:Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
Hadoop 的生态圈
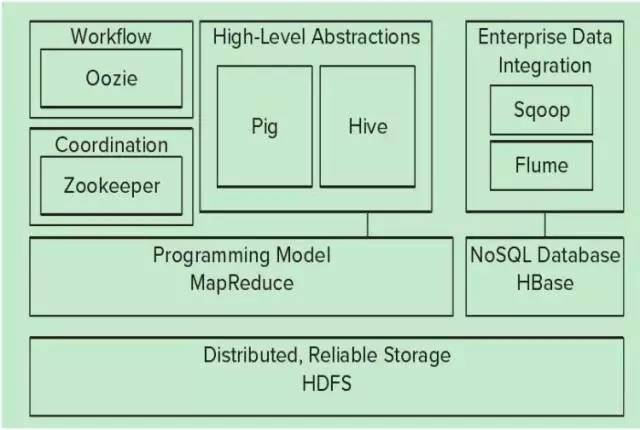
| 组件 | 描述 |
|---|---|
| ZooKeeper | 调度管理组件 |
| Oozie | 堆栈 |
| Pig | 对 MapReduce 进行抽象,可以理解为接口,被其他生态成员调用 |
| Hive | 类型于 SQL 的高级语言,直接在 Hadoop 上进行查询 |
| Sqoop | 迁移工具,主要进行迁移,数据集成 |
| Flume | Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。 |
| Mahout | 提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序 |
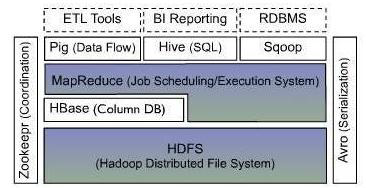
Hadoop 体系结构
HDFS 和 MapReduce 是 Hadoop 的两大核心。而整个 Hadoop 的体系结构主要是通过 HDFS 来实现对分布式存储的底层支持的,并且它会通过 MapReduce 来实现对分布式并行任务处理的程序支持。
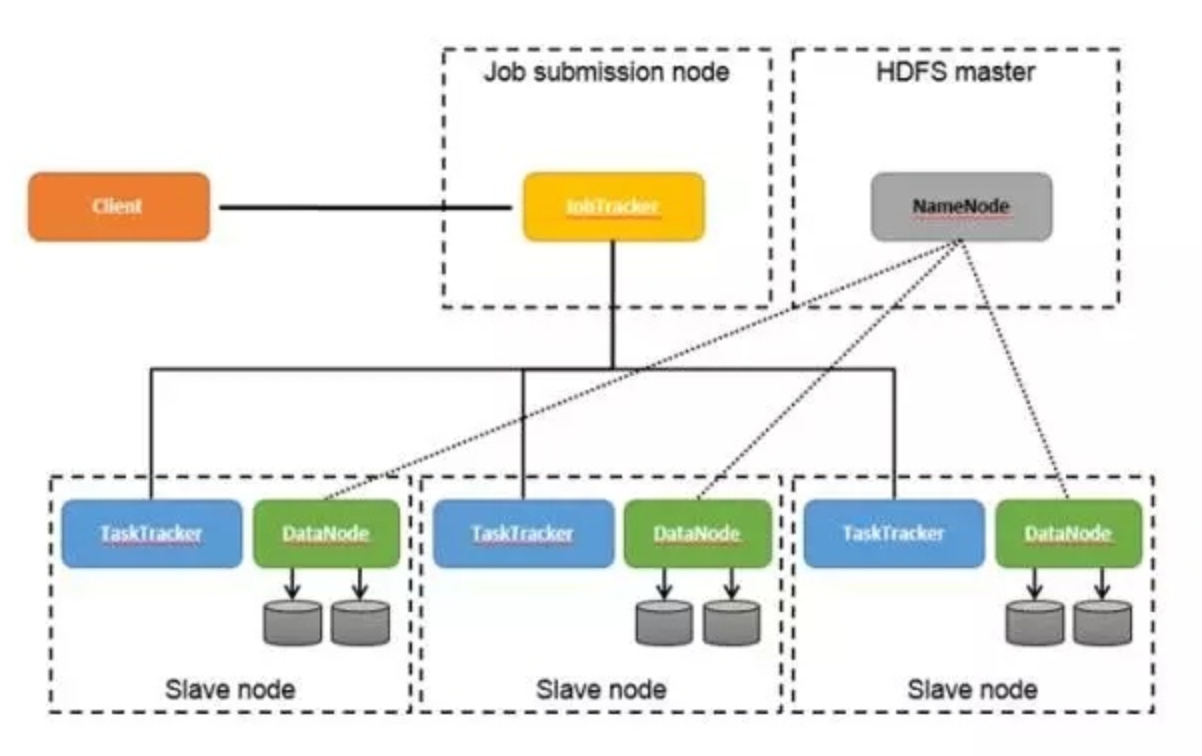 |
 |
|---|
Hadoop 开发流程
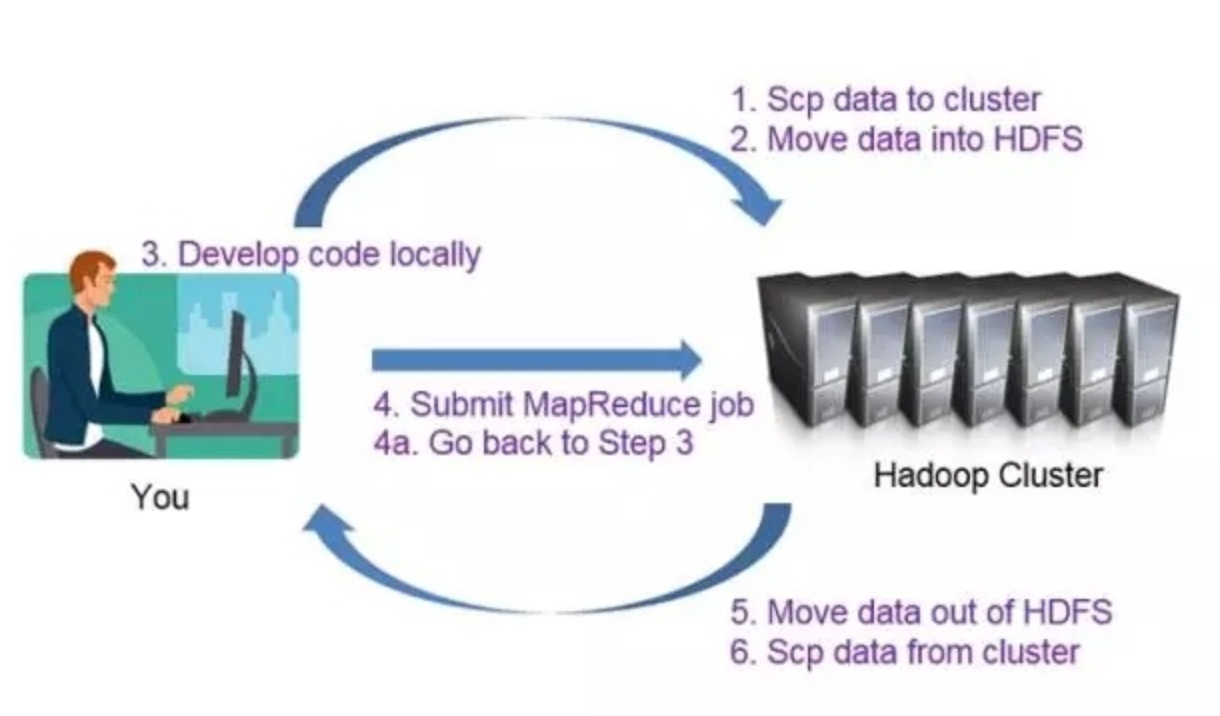
Hadoop 与分布式开发
MapReduce 计算模型非常适合在大量计算机组成的大规模集群上并行运行。每一个 map 任务和每一个 reduce 任务均可以同时运行于一个单独的计算节点上,可想而知,其运算效率是很高的。
并行计算过程:
- 数据分布存储
- 分布式并行计算
- 本地计算:是一种减少带宽消耗的方法
- 任务粒度:粒度下降,大的数据切分成小的数据,一个单位的数据尽量小于一个 Block 的大小,在一个节点上。
- 数据分割(Partition)
- 数据合并(Combine):可以理解成为是和 Reducer 一致的东西
- Reduce
- 任务管道
GFS 与 HDFS
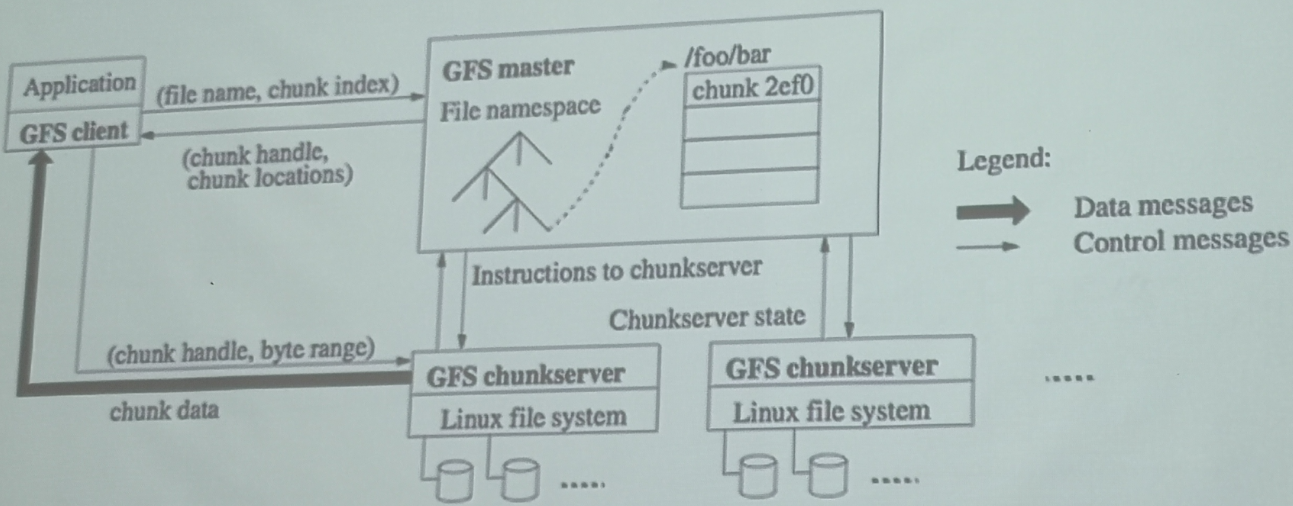 |
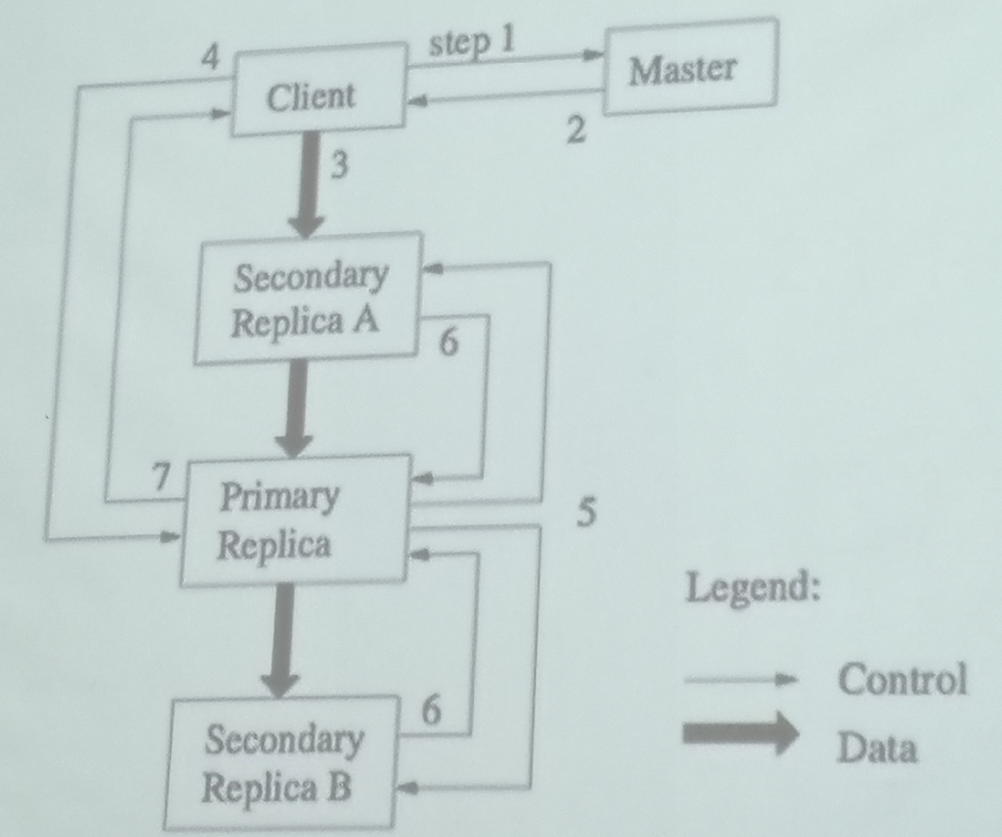 |
|---|
- GFS:谷歌第一架马车
- name node 在 Hadoop 1.0 中进程崩溃会导致系统整个崩溃
HDFS 上的数据存储操作
- 适合大量的大文件
- 平均单个文件超过 500M
- 一次写入,多次读出
- 单个文件的内容不能被修改,除非在文件
- 末尾添加新的数据
- 可以做什么?
- 创建新文件
- 向文件末尾增加内容
- 删除一个文件
- 修改文件名
- 修改文件属性(如:拥有者)
HDFS 架构
- 使用了主从数据库
- Client 是用户访问数据的接口
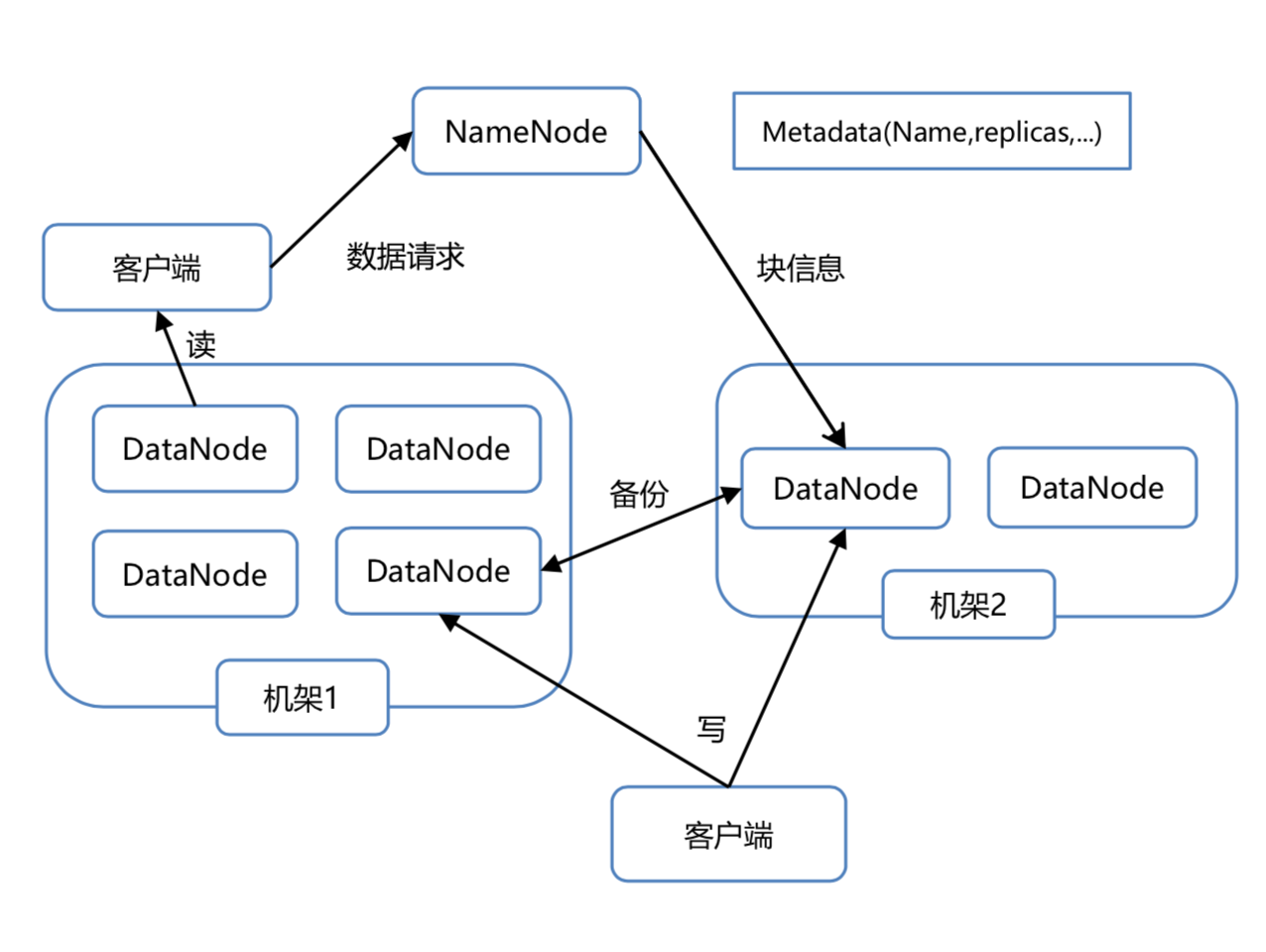
HDFS 的冗余存储
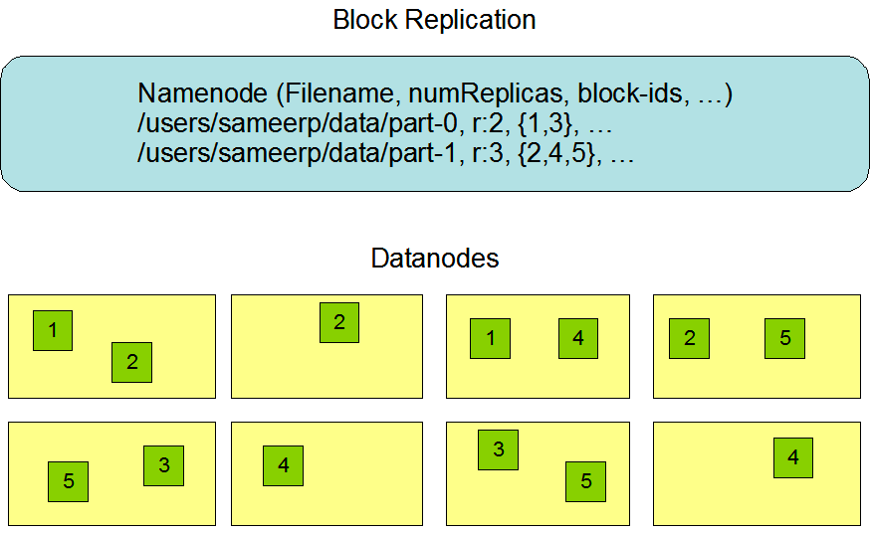
HDFS 基本操作
hadoop fs -ls /user/:显示 hdfs 指定路径下的文件和文件夹hadoop fs -putmy_file /data/:将本地文件上传到 hdfshadoop fs -get /tmp/data/my_file:将 hdfs_上的文件下载到本地hadoop fs -cat /tmp/data/my_file:查着 dfs 中的文本文件内容hadoop fs -text /tmp/data/my_sequence_file:查着 dfs 中的 sequence 文件内容hadoop fs -rm /tmp/data/my_file:将 hdfs,上的文件删除
MapReduce
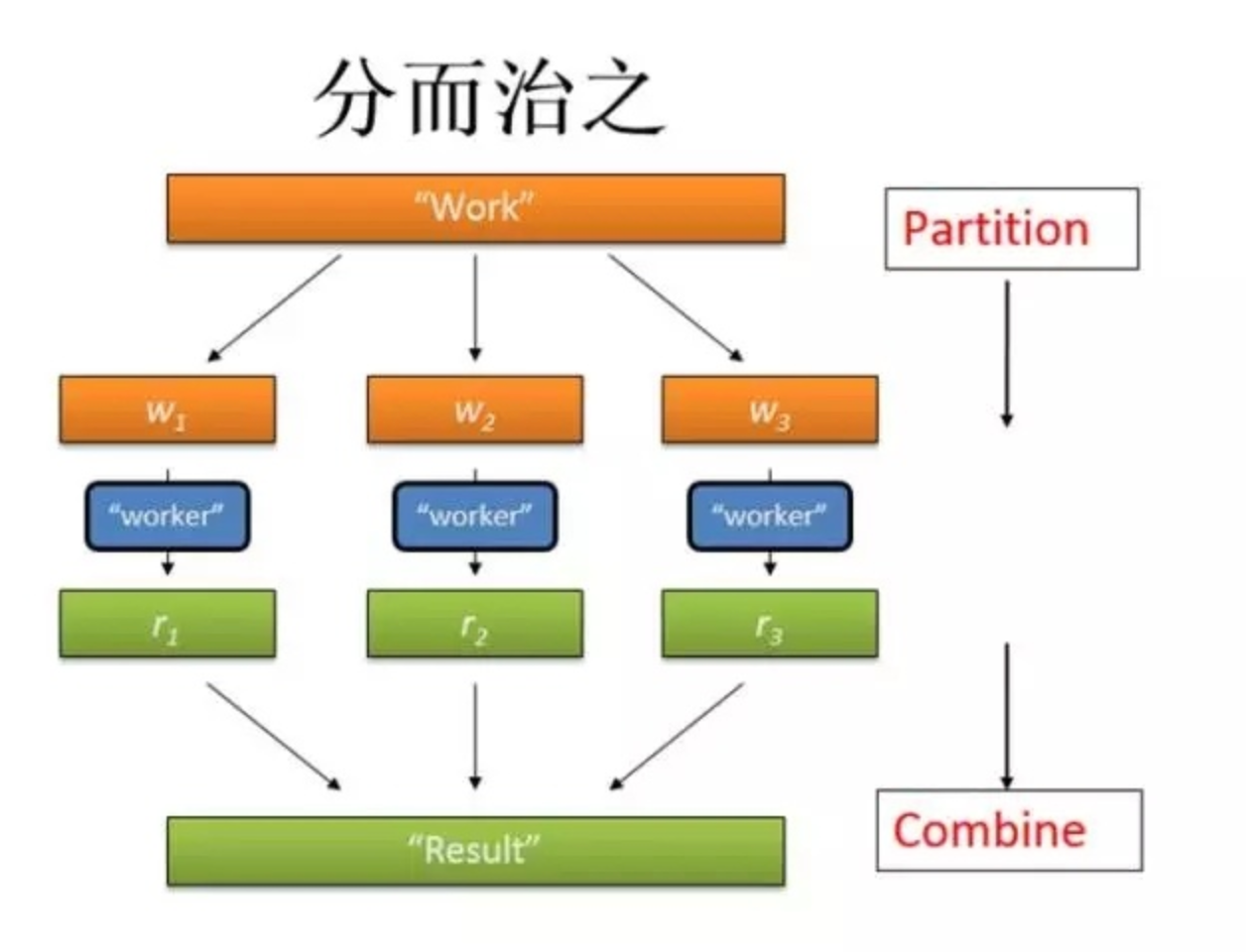
操作:Map、Reduce
数据流
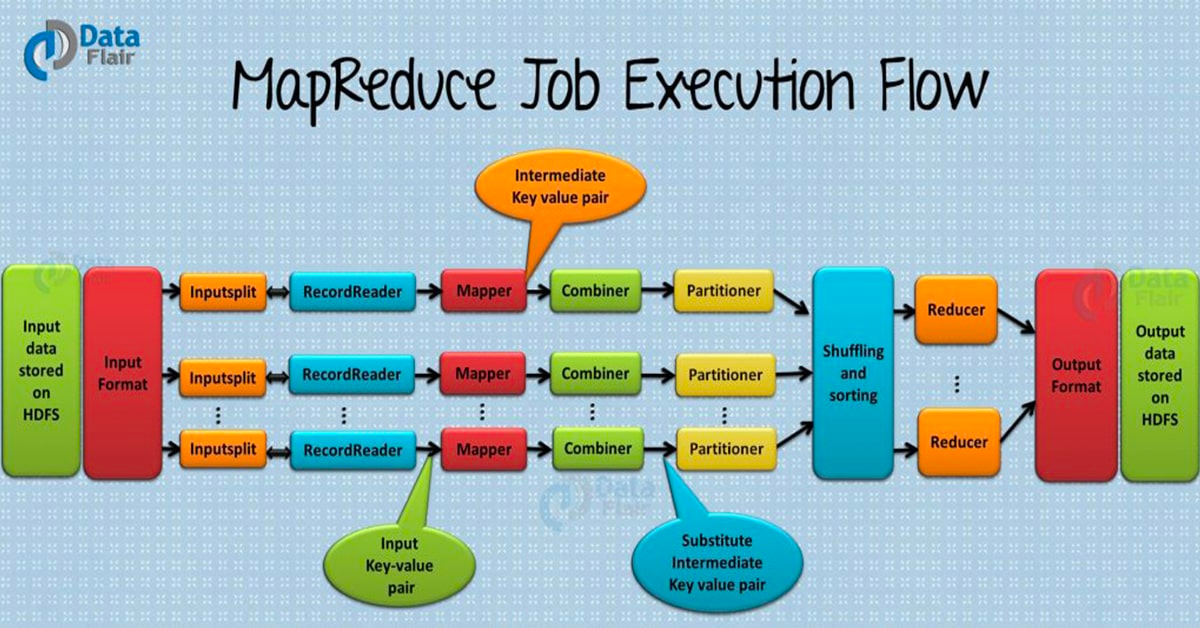
按照管道的方式对数据流进程处理,将 Mapper 和 Reducer 放到单一节点上提高计算效率

