新型数据:图数据
| 社交网络 | 媒体网络 |
|---|---|
 |
 |
| 信息网络 | 信息网络 |
 |
 |
| 技术网络 | |
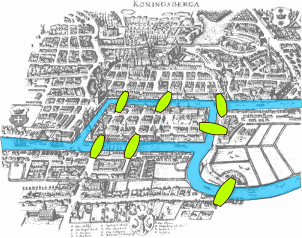 |
图数据形态的网络
Web 表示为有向图
| 图形 | 含义 |
|---|---|
| 节点 | 网页 |
| 边 | 超链接 |
如何组织网络
方式一:网页索引(人工编辑)
Yahoo、DMOZ、LookSmart
方式二:网络搜索
信息检索调查:在一个小而可信的集合中找到相关文档
被搜索集合:新闻报纸、文章、引用等等。
缺陷:网络是巨大的,充满不可信、过时和随机的东西
网络搜索中的挑战:
- 网络中存在多个来源的数据,那么我们相信哪一个来源的数据呢?Trick:可信的网页彼此互相引用和连接
- 查询数据的最佳回答是什么?没有单个的最佳答案,实际关于数据的页面往往指向许多“数据”
在图中作节点排序
所有的网页的重要性不是“平等”的。在网络图节点的连接中有极高的多变性,我们通过链接结构来对页面进行排序。
链接分析算法
我们将要集中介绍一下三种链接分析方法来计算图中节点的重要性:
- Page Rank 算法
- Topic-Specific (Personalized) Page Rank 算法
- Web Spam Detection Algorithms 算法
链接投票
解决方法:链接投票,页面拥有的入链权重和越大越重要,来自重要(高权重)的链接权重更大,地推问题
考虑来自外部网站的链接:
www.stanford.edu有 23400 个链接www.joe-schmoe.com有 1 个链接
所有入链都是等权重的吗?不是,来自重要的链接权重更大,递推问题
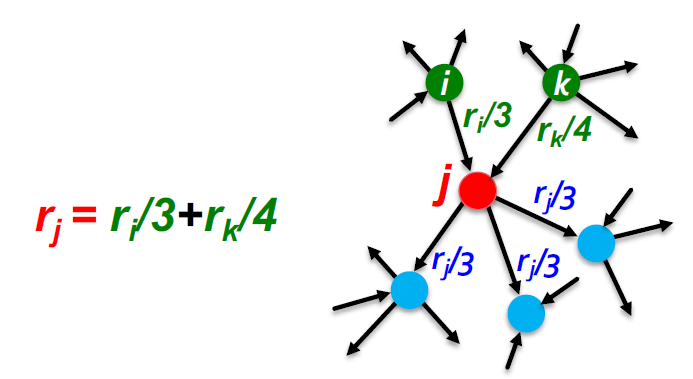
Page Rank 算法
Page Rank 的简单递推公式
- 所有链接的投票权重与其源网页的权重成比例
- 页面 j 的权重为 \(r_j\),拥有 n 个出链,则每个出链有的投票权重为:\(r_{j_{out}} = \frac{r_j}{n}\)
- 页面 j 自身的权重 \(r_j\) 为其入链权重之和
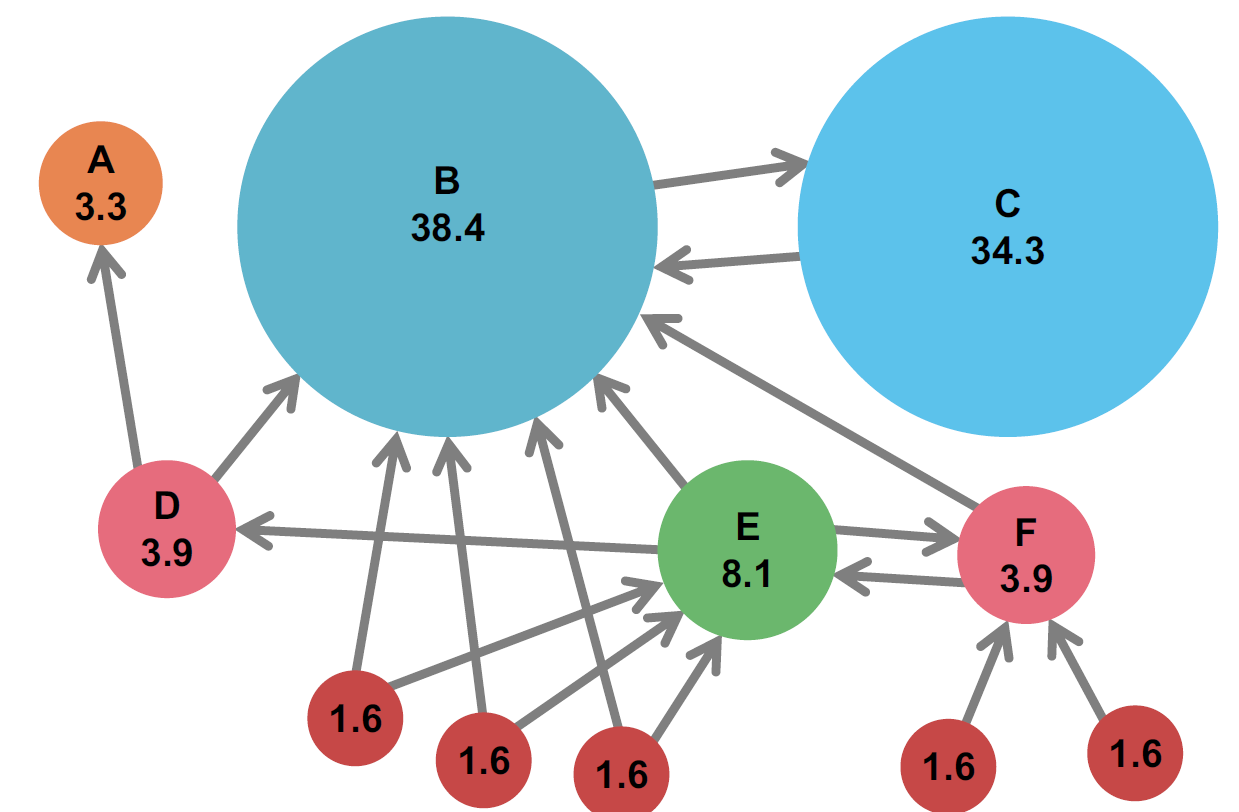
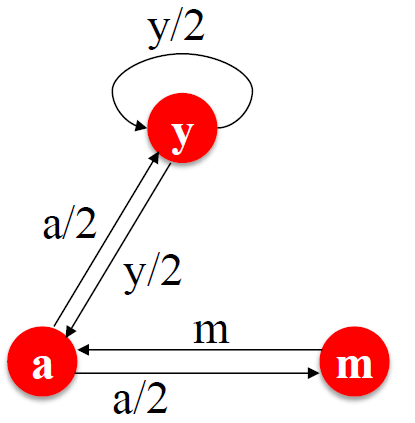
Page Rank 网络局部示意:
Page Rank:“流”模型
- 来自重要页面的连接权重较大
- 被其他页面指向的页面是相对重要的的
- 为页面 j 定义“rank”:\(r_{j}\)
\[ r_{j} = \sum\limits\limits_{i \to j} \frac{r_i}{d_i}\\ d_i 是节点 i 的出度 \]
| 图示意 | 本式没有特解 |
|---|---|
 |
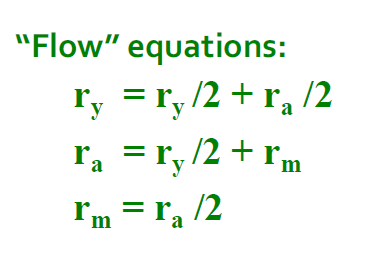 |
简单流等式的求解
上面的右图的式子没有特解,附加约束条件:
- 求解流等式:\(r_y + r_a + r_m = 1\)
- 得到结果为:\(r_y = \frac{2}{5}, r_a = \frac{2}{5}, r_m = \frac{1}{5}\)
高斯法消去只适用于小规模的例子,我们需要其他方法来应对大规模的 Web 图
PageRank 的矩阵等式(核心)
\(r^{(0)}\):给定四个网页的初始的 PR 值
随机邻接矩阵 M
- 页面 i 有 \(d_i\) 个出链
- 如果 \(i \to j\),则 \(M_{ji} = \frac{i}{d_i}\),不然 \(M_{ji} = 0\),列所有元素和为 1
排序向量 r
每一页有一个条目的向量。
\(r_i\) 是页面 i 的出链权重,\(d_i\) 是出链的个数
\[ \sum\limits_{i}r_i = 1 \\ r_j = \sum\limits_{i->j}\frac{r_i}{d_i} \\ 流等式:r = M * r \]

特征向量等式
由上式可知,排序向量 r 是随机邻接矩阵 M 的特征向量
- 其第一个或主要特征向量,对应的特征值为 1
- M 的最大特征值为 1,因为 M 为列随机(非负项)
- 我们知道 r 是单位长度,并且每一列和为 1,\(Mr \le 1\)
- 我们可以高效解出 r,这种方法叫 Power iteration

Power iteraion 方法
- 如果给定一个有 n 个节点的网络图(节点是页,边是超链接)
- Power iteration 算法描述
- 假设这里有 N 个网络节点
- 初始化:\(r^{(0)} = [\frac{1}{N}, ..., \frac{1}{N}]^{T}\)
- 计算:\(r^{(t + 1)} = M * r^{(t)}\),重复操作直到满足停止条件
- 停止条件:\(|r^{(t + 1)} - r^{(t)}| < \varepsilon\)
使用 power iteration 方法求解之前的例子

Power Iteration 方法原理
查找主要特征向量(对应于最大特征值的向量)的方法
\[ r^{(1)} = M \cdot r ^{(0)} \\ r^{(2)} = M^{2} \cdot r ^{(0)} \\ r^{(3)} = M^{3} \cdot r ^{(0)} \\ \dots \\ r^{(n)} = M^{n} \cdot r ^{(0)} \\ \]
证明:序列:\(M \cdot r ^{(0)}, M^{2} \cdot r ^{(0)}, M^{3} \cdot r ^{(0)}, \dots , M^{k} \cdot r ^{(0)}\) 接近 M 的主要特征向量
假设矩阵 M 有 n 个线性独立特征变量 \(x_1, x_2, \dots, x_n\),对应的特征变量为 \(\lambda_1,\lambda_2,\dots,\lambda_n\),并且 \(\lambda_1>\lambda_2>\dots>\lambda_n\)
向量 \(x_1,x_2,\dots,x_n\) 构成一组基向量,所以我们可以写成 \(r ^{(0)} = c_1 * x_1 + c_2 * x_2 + \dots + c_n * x_n\)
所以我们进行计算可得:\(M^k * r ^{(0)} = c_1 * \lambda^k_1 * x_1 + c_2 * \lambda^k_2* x_2 + \dots + c_n * \lambda^k_n* x_n\)
提出 \(\lambda^k_1\):\(M^k * r ^{(0)} =\lambda^k_1 * ( c_1 * x_1 + c_2 * (\frac{\lambda_2}{\lambda_1})^k * x_2 + \dots + c_n * (\frac{\lambda_n}{\lambda_1})^k * x_n)\)
由于之前的假设,可知 \(\frac{\lambda_2}{\lambda_1,\frac{\lambda_3}{\lambda_1},\dots < 1}\)
\(\lim\limits_{k\to\infty}\frac{\lambda_i}{\lambda_1}^k = 0\)
\(M^{k} * r ^{(0)} \approx c_1 * \lambda^k_1 * x_1\)
从上面证明的最后结论我们可以知道,如果 c1 等于 0,那么这个方法不能收敛
Random Walk 算法
假设我们有一个随机网络游标:
- 在任何时间 t,游标在第 i 个节点上
- 在时间 t+1,游标移动到 i 的随机一个外链上
- 最终结束到连接 i 节点的 j 节点上
- 重复以上的过程
\(p(t)\) 是页面上的概率分布
平稳分布
- 时间上满足等式:\(p(t+1) = M * p(t)\)
- 当满足等式:\(p(t+1) = M * p(t) = p(t)\) 的时候 \(p(t)\) 是 Random Walk 的一个平稳分布
- 结合之前矩阵形式的等式,我们可以知道 r 就是 Random Walk 的平稳分布
存在性和唯一性
随机游走理论(又称马尔可夫过程)的主要结果是:对于满足某些条件的图,平稳分布是唯一的,并且无论在时间 t = 0 时的初始概率分布如何,最终都会达到平稳分布
PageRank 的问题
- PageRank 是否收敛?
- PageRank 是否按照我们设想的方式收敛了?
- 结果是否有效可信?
- 有些点是死胡同?
- 有的网络拓扑形成了图结构(爬虫陷阱)?
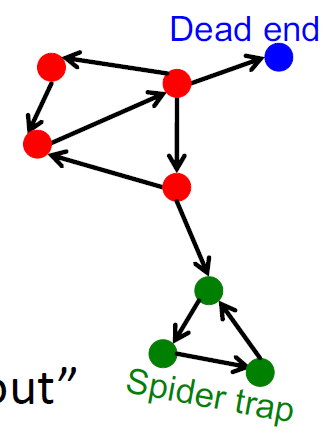
收敛判定
是否收敛至期待水平
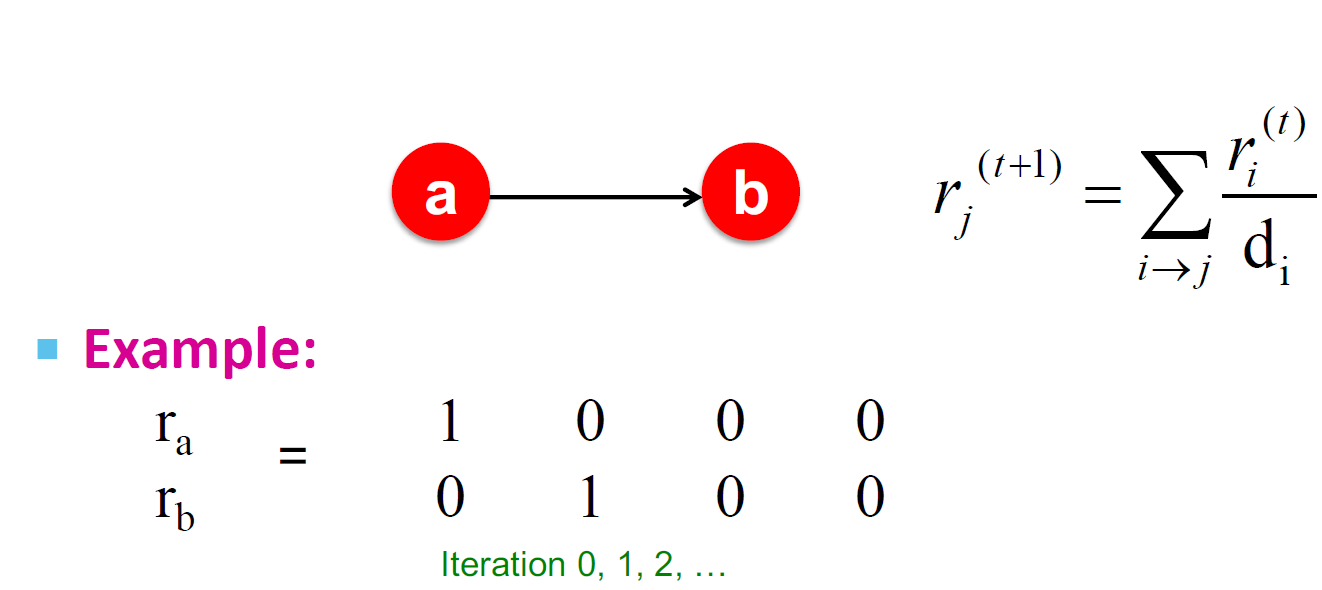
死胡同(Dead end)
- 随意漫步“无处可去”,这些页面导致权重被泄露
- 归根结底:该矩阵不是列随机的,因此无法满足我们的初始假设

解决方案:使用 Teleport
当无处可去时,总是通过传送使矩阵列成为随机的,调整 dead-ends 的权重,使其有随机的概率到图上的任意一个点。
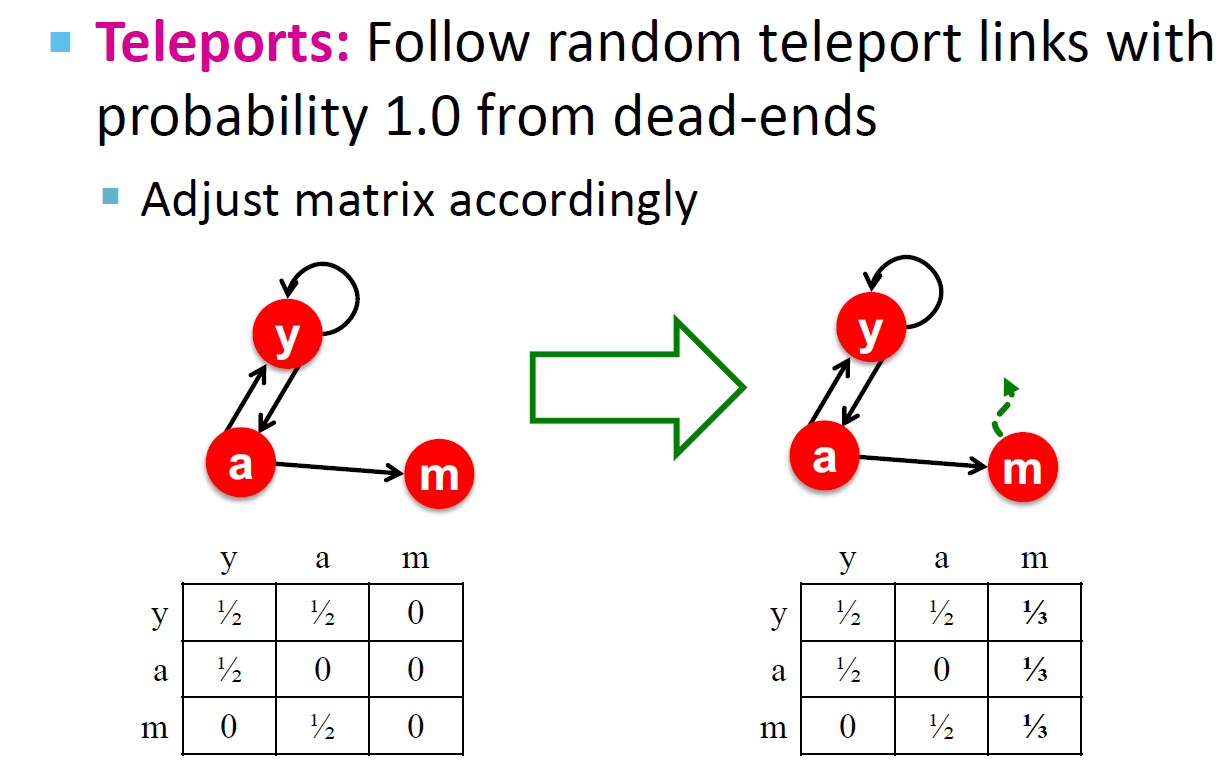
另一种解决方案(裁剪方案,考试使用)
爬虫陷阱
- 所有的出链形成了一个环状结构,随机游走将被困在环中
- 这个不是一个问题,但是不是我们想要的结果:这个环吸收走了模型的所有的重要性
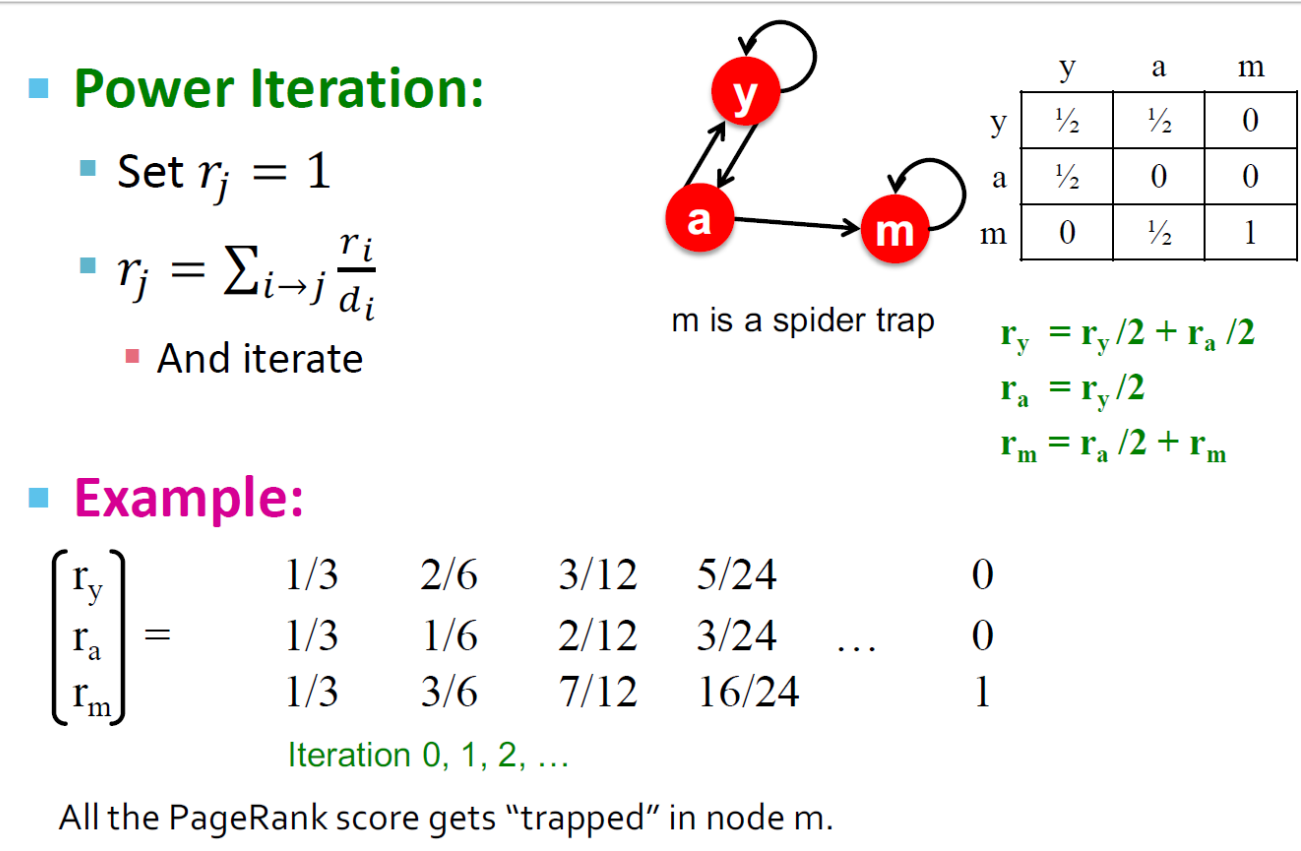
爬虫陷阱的解决方案:Teleports
Google 针对 Spider Traps 的解决方案:在每个时间步,随机冲浪者都有两个选择
- 对于概率 \(\beta\):选择随机一个出链行走
- 对于概率 \(1 - \beta\):选择随机一个点行走
- 概率 \(\beta\) 往往在 0.8-0.9 之间进行选择,经验上会选择 0.85,但是我们可以通过神经网络学习来确定 \(\beta\) 的值
冲浪者将在几步之内将其传送出 Spider Traps
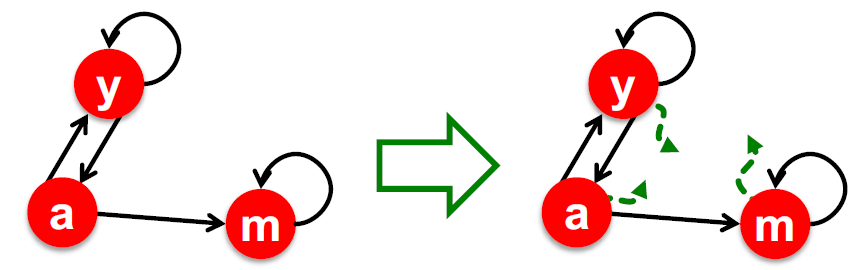

整体的解决方案:Random Teleports
Google 的解决方案是对于所有情况,每一步,随机冲浪者都有两个选择:
- 对于概率 \(\beta\):选择随机一个出链行走
- 对于概率 \(1 - \beta\):选择随机一个点行走
PageRank 等式的修正:
\[ r_j = \sum\limits\limits_{i-j} \beta * \frac{r_i}{d_i} + (1 - \beta) * \frac{1}{N} \]
该公式假定/没有 dead ends。 我们可以预处理矩阵/删除所有 dead ends,也可以从 dead ends 中以概率 1.0 显式地跟随随机传送链接。
\(A = \beta M + (1 - \beta)[\frac{1}{N}]_{N * N}\)
然后我们求解一个递归问题:\(r = A * r\)
Power Iteration 方法仍然适用
Random Teleports 例子(\(\beta = 0.8\))

问题:大规模网络计算会导致内存不足
假设 N = 1,000,000,我们很直观的可以感受到需要存储的数据数量极大
矩阵公式(Random Teleport 的等价形式)
- 从 i 到每隔一页添加一个传送链接并将传送概率设置为 \(\frac{1 - \beta}{N}\)
- 降低跟踪每个出站链接的可能性从\(\frac{1}{|d_i|}\)到\(\frac{\beta}{|d_i|}\)
- 等价于对每一个节点的权乘以\((1- \beta)\),然后均匀地重新分配
方程式重排
\[ r = A * r \\ A_{ji} = \beta*M_{ji} + \frac{1 - \beta}{N} \\ r_j = \sum\limits_{i = 1}\limits^{N}[\beta*M_{ji} + \frac{1 - \beta}{N}] * r_i \\ r_j = \sum\limits_{i = 1}\limits^{N}\beta * M_{ji}* r_i + \frac{1 - \beta}{N} * \sum\limits_{i = 1}\limits^{N}r_i \\ r_j = \sum\limits_{i = 1}\limits^{N}\beta * M_{ji}* r_i + \frac{1 - \beta}{N} \\ \]
所以:\(r = \beta*M*r + [\frac{1-\beta}{N}]_N\)
稀疏矩阵公式
\[ r = \beta*M*r + [\frac{1-\beta}{N}]_N \]
- \([\frac{1-\beta}{N}]_N\) 是一个 N 维 \(\frac{1-\beta}{N}\) 的列向量(常量)
- M 是一个稀疏矩阵
- 过程我们可以规划为如下
- 计算 \(r^{new} = \beta * M * r^{old}\)
- \(r^{new} = r^{new} + [\frac{1-\beta}{N}]_N\)
- 注意在上面这个过程中,如果 \(\sum\limits_{j}r_{j}^{new} < 1\),我们需要对 \(r^{new}\) 进行格式化,使其和为 1(这种情况是 M 包含 dead-ends)
稀疏矩阵编码
- 仅使用非零条目对稀疏矩阵进行编码
- 假设有 1,000,000 条数据,4 _ 10 _ 1 billion = 40GB 对于内存是不现实的,但是对于磁盘是可以的
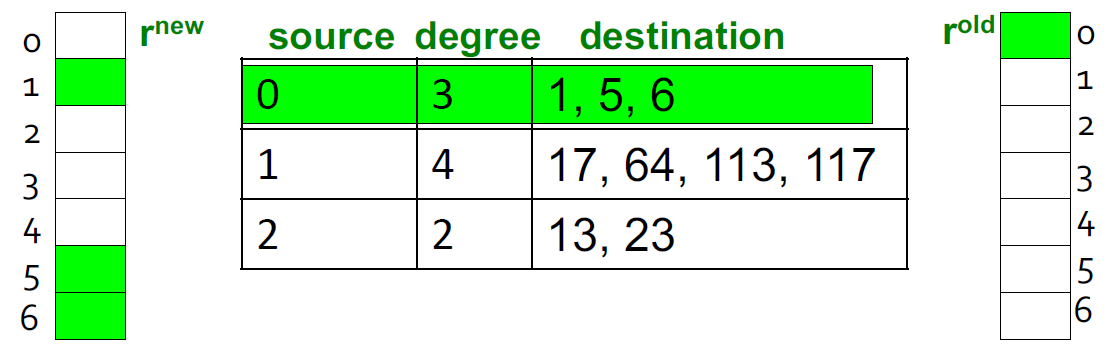
稀疏矩阵算法
我们假设 RAM 可以将 \(r^{new}\) 载入到磁盘,存储 \(r^{old}\) 和矩阵 M 在磁盘中。
power-iteration 的一个步骤:
- 初始化:\(r^{new} = \frac{1-\beta}{N}\)
- 对于页面 i(出度为\(d_i\))
- 从内存中加载:\(i,d_i,dest_1,...,dest_{d_i},r^{old}(i)\)
- 对于\(j = 1 ... d_i\)
- \(r^{new}(dest_j) += \frac{\beta r^{old}}{d_i}(i)\)
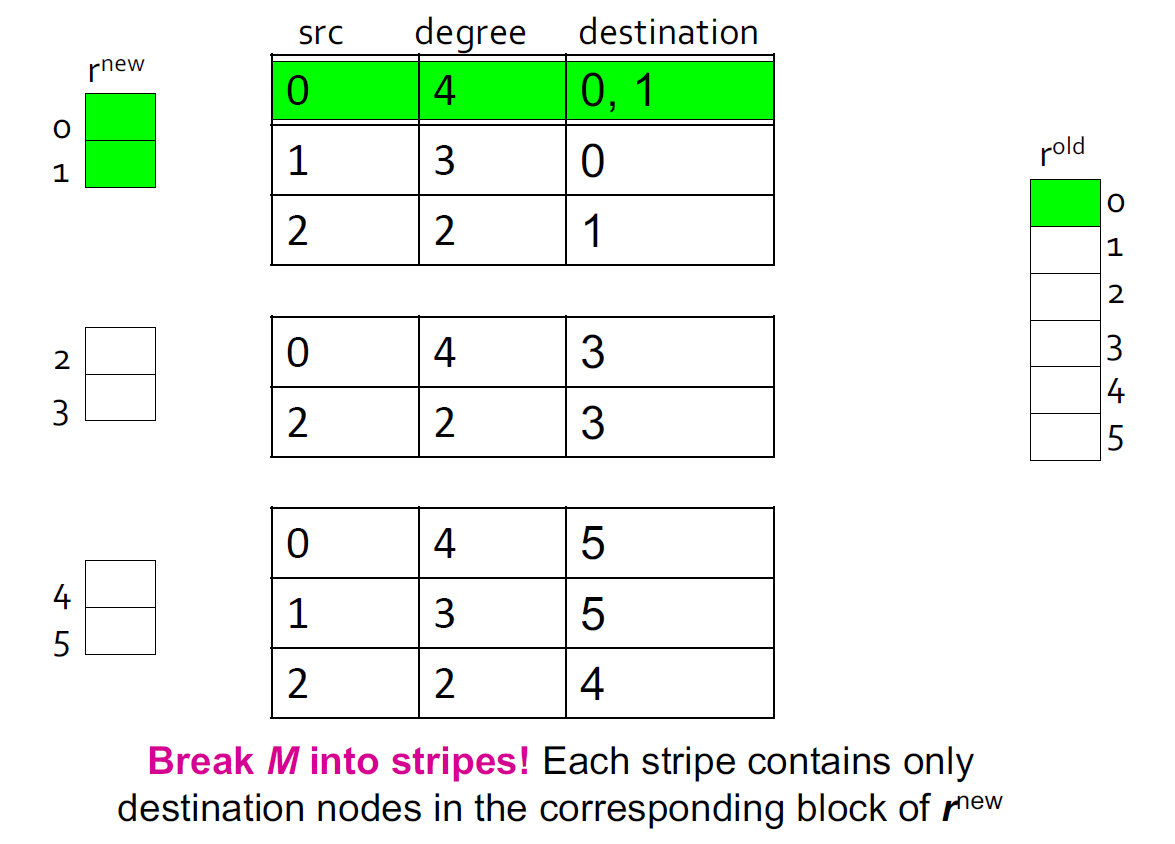
基于块更新的算法
进一步减少空间消耗,将 \(r^{new}\) 重新切分成 k 块,来适配内存,为每一块扫描 M 和\(r^{old}\)

块更新消耗:
- k 次扫描 M 和 \(r^{old}\)
- 每次 Power iteration 的消耗:\(k(|M| + |r|) + |r| = k|M| + (k+1)|r|\)
我们有没有做的更好了呢?
- M 相对于 r 更加大(大约有 10-20x),所以我们可以避免每一个迭代读 k 次
PageRank 完整算法
输入:
- 一个有向图 G,可以有 Spider Traps 和 Dead ends
- 参数\(\beta\)
输出:PageRank vector \(r^{new}\)
过程:
- 初始化:\(r_{j}^{old} = \frac{1}{N}\)
- 重复以下步骤直到收敛:\(\sum\limits_{j}|r_j^{new} - r_j^{old}| > \varepsilon\)
- \(\forall j: r_j^{'new} = \sum\limits_{i->j}\beta\frac{r_i^{old}}{d_i}\)
- \(\forall j: r_j^{'new} = 0\),if in-degree of j is 0
- 现在,重新插入的 PageRank:
- \(\forall j: r_j^{new} = r_j^{'new} + \frac{1 - S}{N}\ where\ S = \sum\limits_jr_{j}^{'new}\)
- \(r^{old} = r^{new}\)
如果图形没有死角,则泄漏的 PageRank 数量为 \(1-\beta\)。 但是因为我们有死胡同,PageRank 的泄漏量可能更大。 我们必须通过计算 S 来明确说明这一点。
一次迭代的消耗:2|r| + |M|
Topic-Sensitive PageRank
其实上面的讨论我们回避了一个事实,那就是“网页重要性”其实没一个标准答案,对于不同的用户,甚至有很大的差别。例如,当搜索“苹果”时,一个数码爱好者可能是想要看 iphone 的信息,一个果农可能是想看苹果的价格走势和种植技巧,而一个小朋友可能在找苹果的简笔画。理想情况下,应该为每个用户维护一套专用向量,但面对海量用户这种方法显然不可行。所以搜索引擎一般会选择一种称为 Topic-Sensitive 的折中方案。Topic-Sensitive PageRank 的做法是预定义几个话题类别,例如体育、娱乐、科技等等,为每个话题单独维护一个向量,然后想办法关联用户的话题倾向,根据用户的话题倾向排序结果。
算法步骤
确定话题分类
一般来说,可以参考 Open Directory(DMOZ)的一级话题类别作为 topic。目前 DMOZ 的一级 topic 有:Arts(艺术)、Business(商务)、Computers(计算机)、Games(游戏)、Health(医疗健康)、Home(居家)、Kids and Teens(儿童)、News(新闻)、Recreation(娱乐修养)、Reference(参考)、Regional(地域)、Science(科技)、Shopping(购物)、Society(人文社会)、Sports(体育)。
网页 topic 归属
这一步需要将每个页面归入最合适的分类,具体归类有很多算法,例如可以使用 TF-IDF 基于词素归类,也可以聚类后人工归类,具体不再展开。这一步最终的结果是每个网页被归到其中一个 topic。
分 topic 向量计算
- 在 Topic-Sensitive PageRank 中,向量迭代公式为 \[ v' = (1- \beta)Mv + s\frac{\beta}{|s|} \]
- 首先是单位向量 e 变为了 s。s 是这样一个向量:对于某 topic 的 s,如果网页 k 在此 topic 中,则 s 中第 k 个元素为 1,否则为 0。注意对于每一个 topic 都有一个不同的 s。而|s|表示 s 中 1 的数量。
- 还是以上面的四张页面为例,假设页面 A 归为 Arts,B 归为 Computers,C 归为 Computers,D 归为 Sports。那么对于 Computers 这个 topic,s 就是: \[ s = \begin{bmatrix} 0 \\ 1 \\ 1 \\ 0 \\ \end{bmatrix} \]
- 而 lsl=2,因此,迭代公式为

针对 PageRank 的 Spam 攻击与反作弊
Link Spam:造出来很多空页来提高自己的页的 rank 值
反作弊:
- 检测拓扑
- TrustRank:如果比可信网站的 rank 高太多那么有理由认为是有问题的

