什么是聚类
聚类是一种无监督学习,有时候被叫做被统计学分类、被物理学家排序、被营销人员分段。
将数据划分成类,并且满足以下两个条件:
- 类内相似度高
- 类间相似度低
不同于分类问题的是,我们直接从数据中获取到类标签和类的数量,也就是找到自然分类。
聚类的应用
| 应用方向 | 描述 |
|---|---|
| 市场营销 | 帮助市场营销人员根据他们的用户发现独特的分组,然后使用这个发现(只是)来发展有针对性营销程序 |
| 土地使用 | 在地球观测数据库中确定类似土地利用的区域 |
| 保险 | 发现具有索赔成本的汽车保险持有人分组 |
| 城市规划 | 根据房屋类型识别房屋组,重视地理位置 |
| 地震学 | 观察到的地震震中应沿大陆断层聚集 |
聚类度量
度量距离
- 定义:令 \(O_1\) 和 \(O_2\) 是来自可能对象集合的两个对象。\(O_1\) 和 \(O_2\) 之间的距离是一个实数,表示为 \(D(O_1, O_2)\)
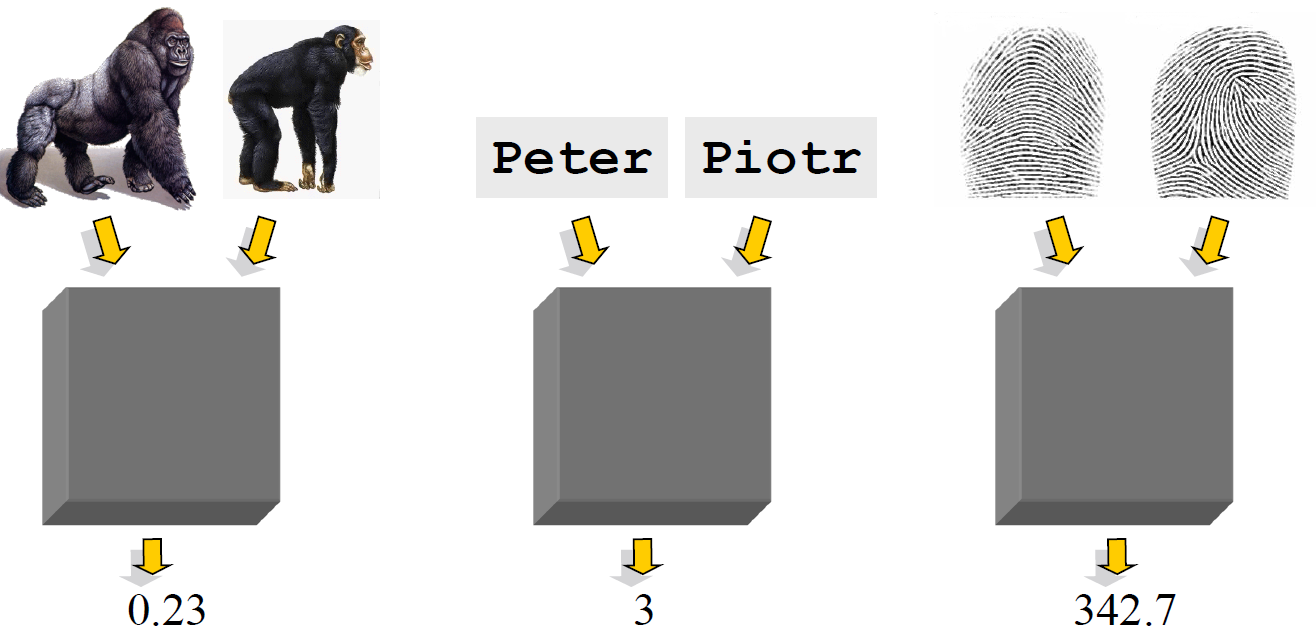
度量距离的性质引入
我们观察黑盒,我们可以发现关于两个变量的一个函数,这个函数可能比较简单,也可能比较复杂,但是我们很自然的想要知道这个函数有什么性质。
度量距离的性质
| 性质 | 形式化表述 | 描述 |
|---|---|---|
| 对称性 | \(D(A, B) = D(B, A)\) | 若无此性质, A 和 B 相似,但是 B 和 A 不相似 |
| 自相似常量 | \(D(A, A) = 0\) | 若无此性质,A 比 B 还像 B |
| 正向性 | \(D(A, B) = 0 \iff A = B\) | 若无此性质,你的世界里有不同的物体,但是你不能分辨他们 |
| 三角不等式 | \(D(A, B) \leq D(A, C) + D(B, C)\) | 若无此性质,A 非常像 B,A 非常像 C,但是 B 很不像 C |
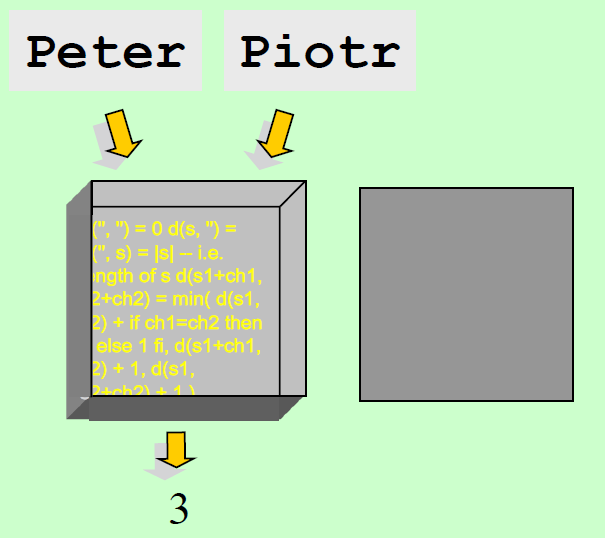
编辑距离
- 我们是可以只使用替换、插入和删除将字符串 Q 转换为字符串 C
- 假设每一个操作都有一个代价与之相关联
- 两个字符串之间的相似度被从字符串 Q 转换为字符串 C 的最小代价
 |
 |
|---|
聚类算法的理想特性
- 时间和空间上规模可控,对输入顺序不敏感,可以结合用户给定的约束
- 有能力处理不同的数据类型:可以处理二维及以上平面
- 有能力去处理噪声和离群点
- 需要极少的领域知识去了解输入变量参数
- 可解释容易使用
聚类问题定义
给定一组点,并带有点之间的距离的概念,将这些点分组为一定数量的簇,以便
- 一个簇中的成员彼此之间足够相似
- 不同簇间的成员彼此并不相似
通常:
- 数据点是在高维空间
- 相似度是通过举例度量来定义:欧几里得,余弦,雅卡德,编辑距离等
类簇和离群点
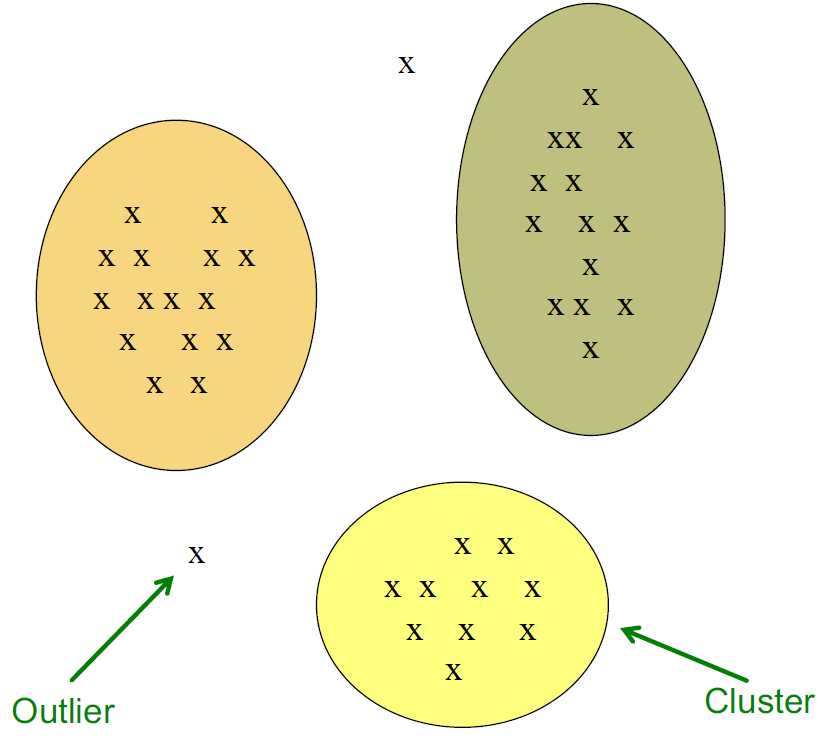
难点与挑战
- 二维空间下的聚类问题相对比较简单,然而在很多的应用中,并不是在二维空间上操作,而是十维或者更高维度。
- 小数据量的聚类问题相对比较简单,然而在很多的应用中,数据量是相对比较大的。
- 在大多数情况下,外观并不具有欺骗性(指类的形状)
- 高维空间则是不一样,几乎所有成对的点都在大约相同的距离处
星系问题
20 亿个“天体”的目录通过其在 7 个维度(频带)中的辐射来表示对象
问题:聚集到类似的物体中,例如星系,附近的恒星,类星体等

音乐 CD 问题
音乐分为几类,客户更喜欢几类
问题:类别到底是什么?
由一组购买 CD 的客户代表 CD
相似的 CD 具有相似的客户群,反之亦然
所有 CD 的空间:
- 假设有一个一维空间(即向量)。对于每个客户:
- 向量中的值只能是 0(未购买)或 1(已购买)
- CD 是此空间中的一个点 \((x_1, x_2, ..., x_k)\),如果第 i 个客户购买了 CD,则 \(x_i=1\)
- 对于亚马逊,规模为数千万甚至更多。
- 任务:查找相似的 CD 的簇
文档
使用向量来代表一个文档:\((x_1,x_2,...,x_k)\) 如果在排列中第 i 个位置上的单词出现在文档中,则\(x_i = 1\)
如果 k 是无限的也没有什么问题,我们不限制词集的大小
带有相似词集的文档可能涉及同一主题
距离度量
理想:语义相似。
实用:术语统计相似性
- 我们将使用余弦相似度
- 文档被存储成向量
- 对于许多算法,更容易根据文档之间的距离(而不是相似性)来考虑。
- 我们将主要讲欧几里德距离:但是实际实现上使用的是余弦相似度
与 CD 一样,当我们将文档视为单词时,我们可以选择:
- 集合作为向量:使用余弦夹角
- 集合作为集合:使用 Jaccard 距离:用 1-Jaccard index(相交元素处理其并集)
- 集合作为点:使用欧几里得距离
硬聚类和软聚类
硬聚类:每个文档恰好属于一个聚类(更简单,更容易做到)
软聚类:一个文档可以属于多个聚类
- 对于创建可浏览层次结构的应用程序更有意义
- 您可能希望将一双运动鞋分为两类:
- 运动服装
- 鞋子
- 您只能使用软聚类方法来做到这一点。
聚类方法
- 划分方法
- 基于层次的方法
- 基于模型的方法
- 基于密度的方法
划分方法
分割方法:将 n 个对象的数据库 D 的分区构造为 k 个聚类的集合
给定一个 k,找到一个 k 簇的分区,以优化所选分区标准
- 全局优化:详尽列举所有分区,属于启发式算法
- 启发式方法:k-mean 和 k-medoids 算法
- k-mean 法:每个聚类由聚类的中心表示,聚类中心不一定是实际存在的点
- k-medoids 法:每个聚类由聚类中的一个对象表示
启发式
- 启发式方法用于快速得出希望接近最佳答案的解决方案,即“最佳解决方案”。
- 启发式是“经验法则”,有根据的猜测,直观的判断或简单的常识。
- 启发式是解决问题的一种通用方法。启发式作为名词是启发式方法的另一个名称。
启发式算法
仿动物类的算法:
- 粒子群优化
- 蚂蚁优化
- 鱼群算法
- 蜂群算法
仿植物类的算法:
- 向光性算法
- 杂草优化算法
仿人类的算法:
- 和声搜索算法
k-mean 算法(启发式算法)
假设文档是一个实数向量,基于类中点的 centroid(也称为重心或均值)的类
\[ \vec{\mu}(c) = \frac{1}{|c|}\sum\limits_{\vec{x} \in c}\vec{x} \]
将实例重新分配给类是基于到当前类 centroid 的距离:或者可以用相似性来等同地表述。
欧式空间的 k-mean 算法描述
假设是欧几里得空间/距离,k-mean 算法过程
- 首先确定 k(簇数)
- 随机选择 k 个点作为 k 个聚类的中心来初始化聚类,保证每一点都与其他的点尽可能的远
- 填充每个聚类
- 对于每个点,将其放置在当前 centroid 最近的聚类中
- 分配所有点后,更新 k 个聚类的 centroid 的位置
- 将所有点重新分配到它们最近的 centroid:有时在群集之间移动点
- 重复 2 和 3 直到收敛,收敛被定义为点在簇之间不移动,centroid 稳定
终止条件:(有很多的候选条件)
- 一个固定数量的循环次数
- 文档向量分簇不变
- centroid 的位置不变
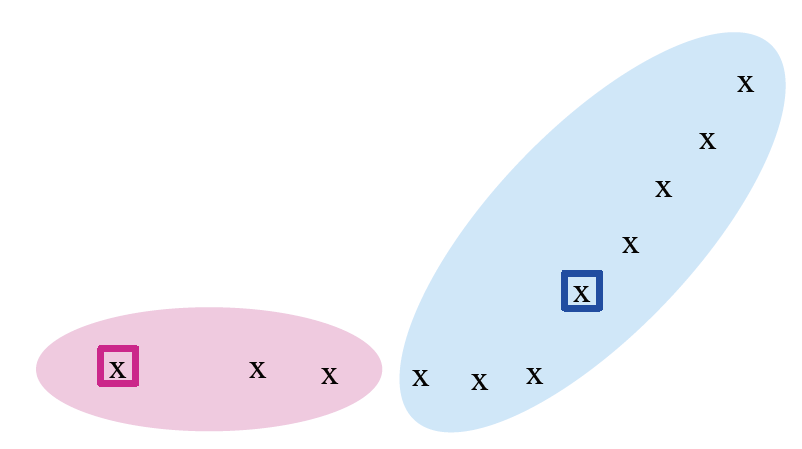
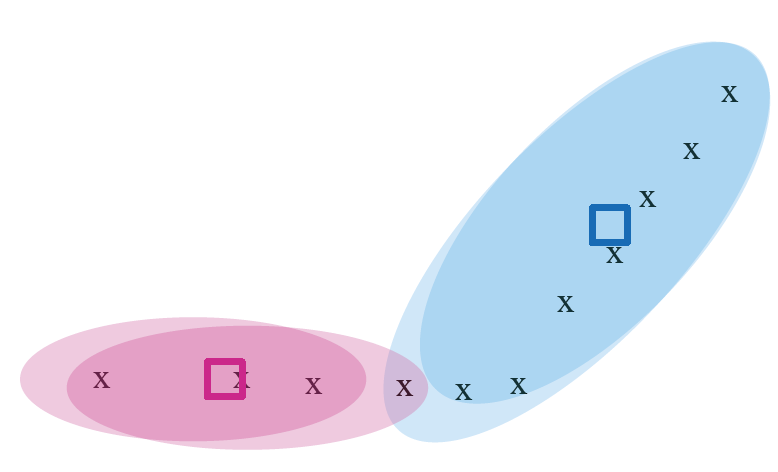
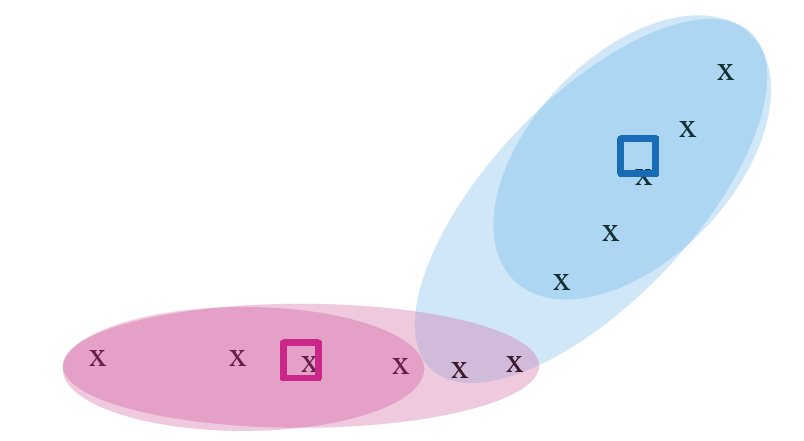
k-mean 算法示例
例子一
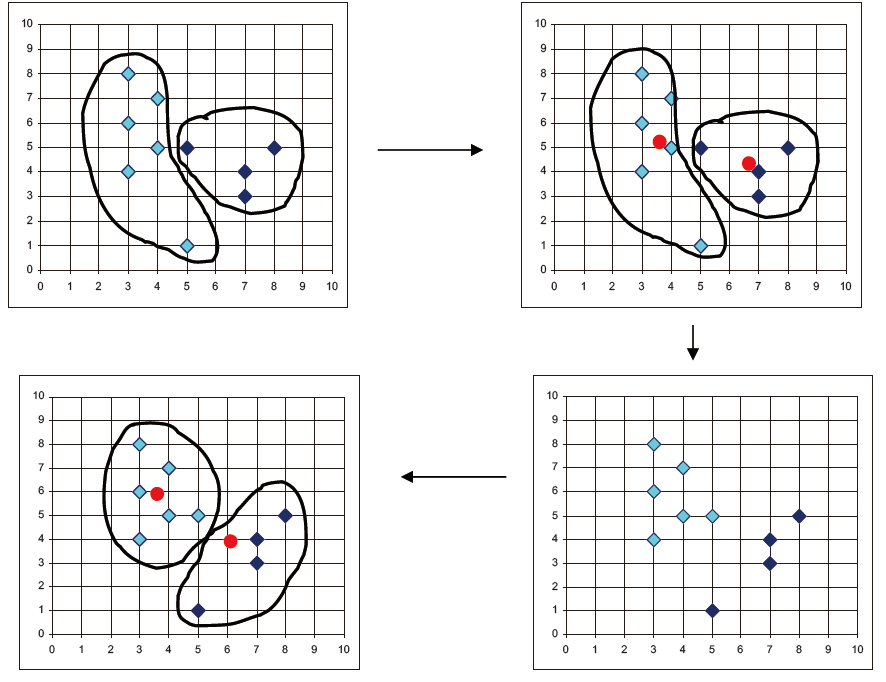
例子二
 |
 |
|---|---|
 |
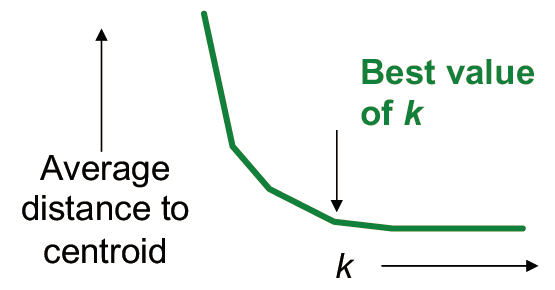
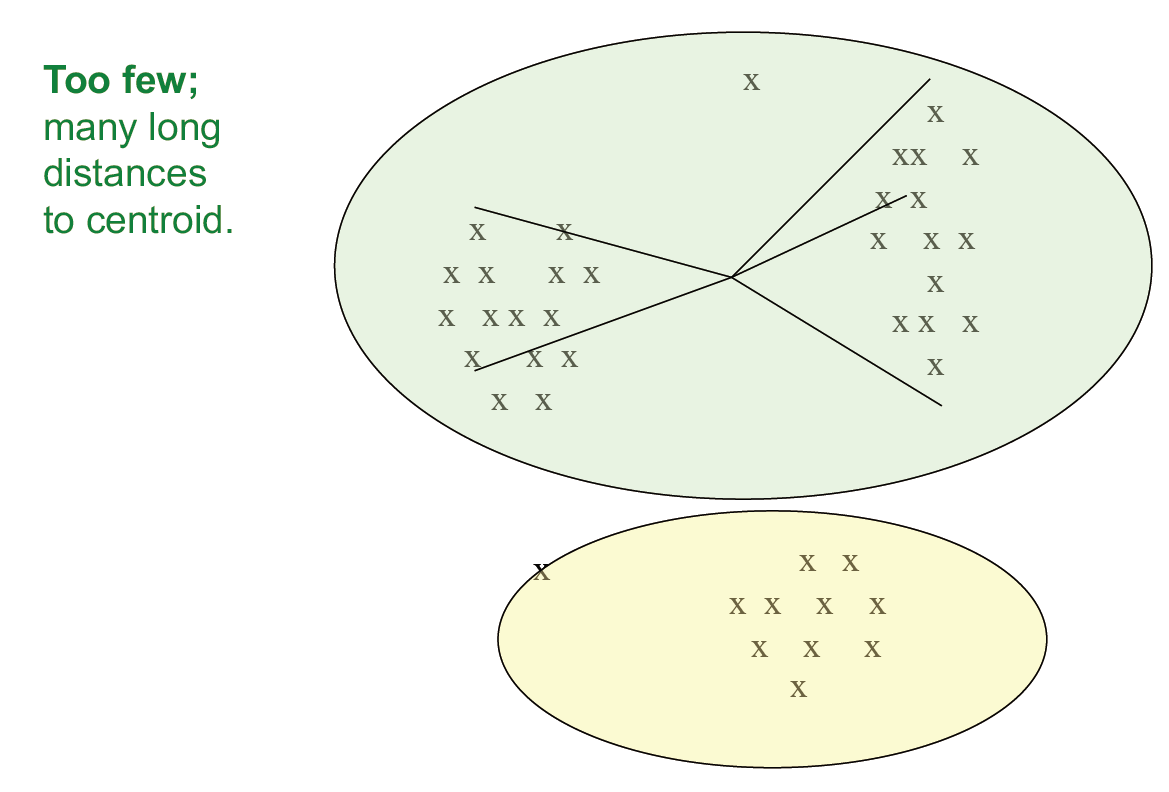
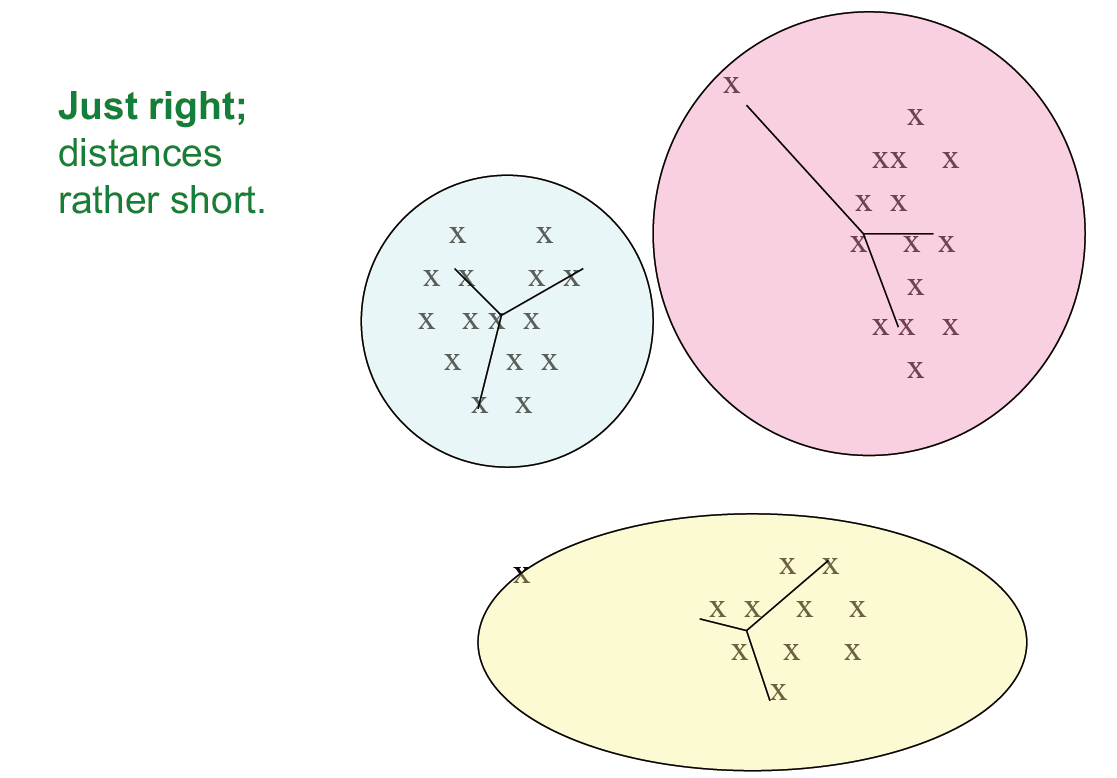
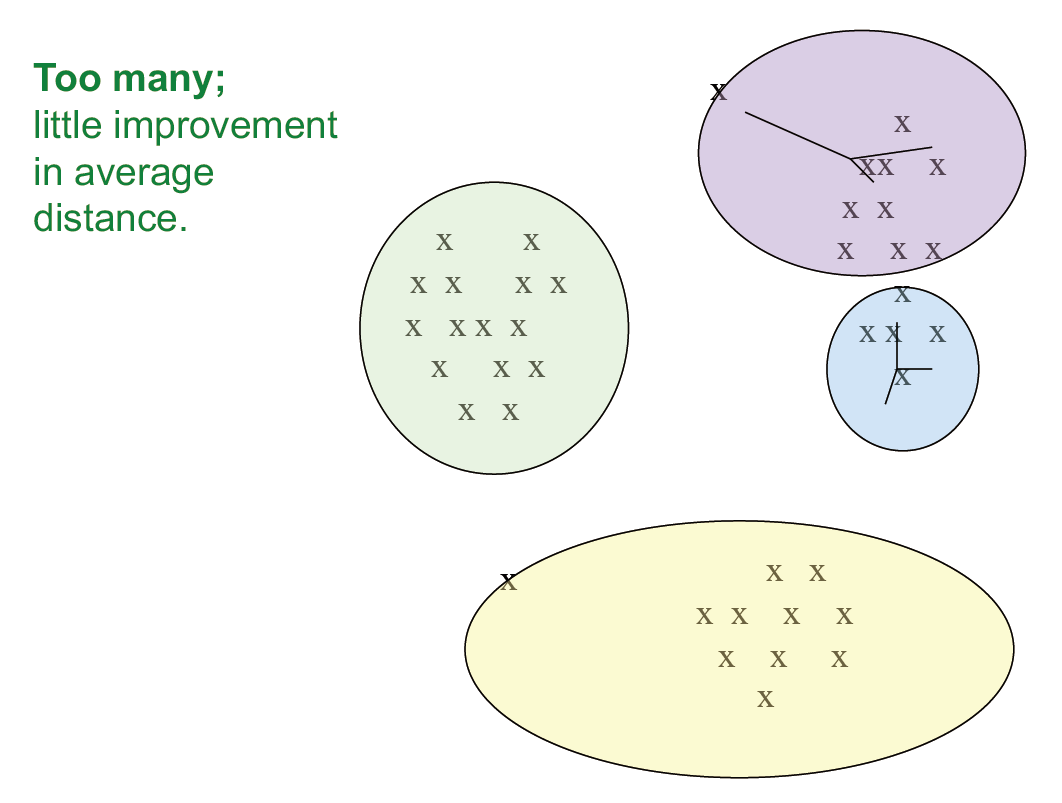
如何正确的选择 k 值
- 尝试不同的 k,观察随着 k 增大,到 centroid 的平均距离的变化
- 平均值迅速下降直到右 k,然后变化很小
| K 值选择过少 | K 值选择刚好 | K 值选择过多 |
|---|---|---|
 |
 |
 |
- k 值选择过少:距离 centroid 长度过大
- k 值选择过多:在平均距离上很难有提升
k-mean 的优缺点
优点
- 相对高效: \(O(tkn)\),n 是物体数量,k 是聚类数量,t 是迭代次数,一般来讲:\(k,t \ll n\)
- 通常以局部最优值终止。可以使用诸如模拟退火和遗传算法之类的技术找到全局最优值
缺点
- 仅在定义均值时适用
- 需要预先指定 k,即簇数
- 嘈杂的数据和异常值的问题
- 不适合发现具有非凸形状的聚类
基于层次的方法
使用距离矩阵作为聚类标准。此方法不需要输入簇数 k,但是需要终止条件。
数据点的划分:数据点属于一个簇或者是数据点属于最近的一个簇。
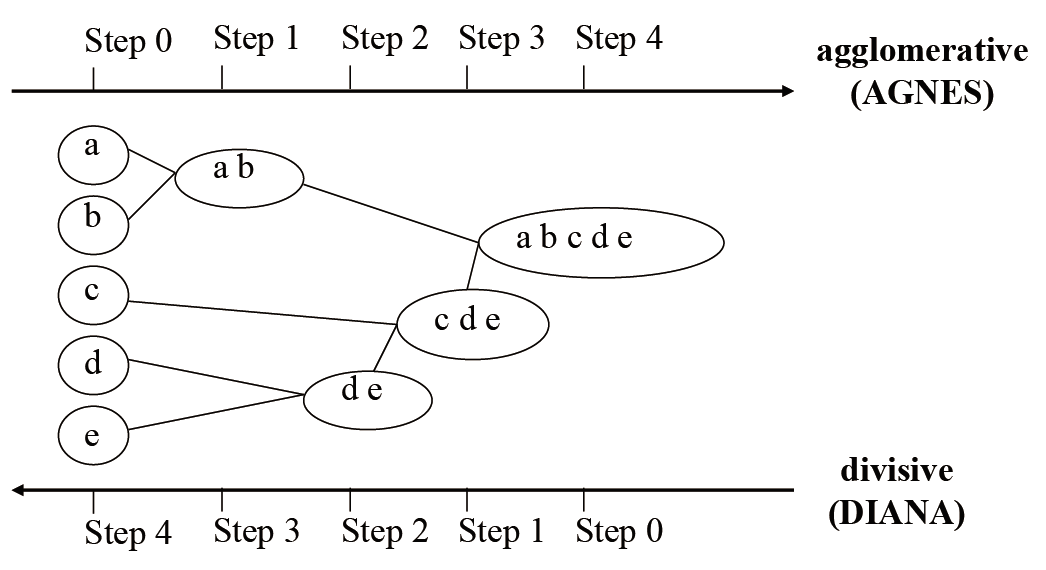
基于层次的方法分类
- 基于聚合(自下而上):AGNES,最初每一个点都是一个簇,重复将两个最近的群集合并为一个
- 基于切分(自上而下):DIANA,从一个簇开始,进行递归拆分
基于层次的核心操作
重复合并(或拆分)距离最近的两个簇
度量簇距离的变量
- 单链接:余弦相似度最高的相似度(单链接)
- 全链接:最远点的相似度,最小余弦相似度
- 质心:centroid 最接近余弦的聚类
- 平均链接:成对元素之间的平均余弦
基于层次的方法的三个重要问题
分为欧式空间和非欧式空间进行讨论:在非欧式空间中,我们唯一可以谈论的“位置”就是数据点本身,没有两点的“平均值”
- 您如何表示一个多点的簇?
- 您如何确定簇的“附近”?
- 什么时候停止合并簇?
您如何表示一个多点的簇?

欧式空间:
- centroid = 数据点的均值
- 我们选择使用质心 centroid 作为簇的代表
非欧式空间:
- clustroid = 与其他点“最近”的一个点
- 最近的含义:
- 最小化每个点之间的最大距离
- 最小化每个点之间的平均距离
- 最小化和其他店之间的距离平方和:对于距离矩阵 d,簇 C 的中心 c 是:\(\min\limits_c\sum\limits_{x \in C} d(x, c)^2\)
如何确定簇的附近
欧式空间:
- 我们使用 centroid 的距离来度量簇的距离
非欧式空间
- 当计算类间距离时,我们把 clustroid 作为 centroid
- clustroid 的计算方法:
- 簇内距离:任何两个点之间的最小距离,每个群集中的一个
- 选择簇的“内聚”概念,例如距 clusteroid 的最大距离,合并两个簇如果这两个簇的并集是最内聚的。
- 内聚的定义:
- 方法一:使用合并簇的直径=簇中点之间的最大距离
- 方法二:使用簇中点之间的平均距离
- 方法三:使用基于密度的方法,取直径或平均值。 距离,例如,除以群集中的点数
欧式空间的合并层次方法实例
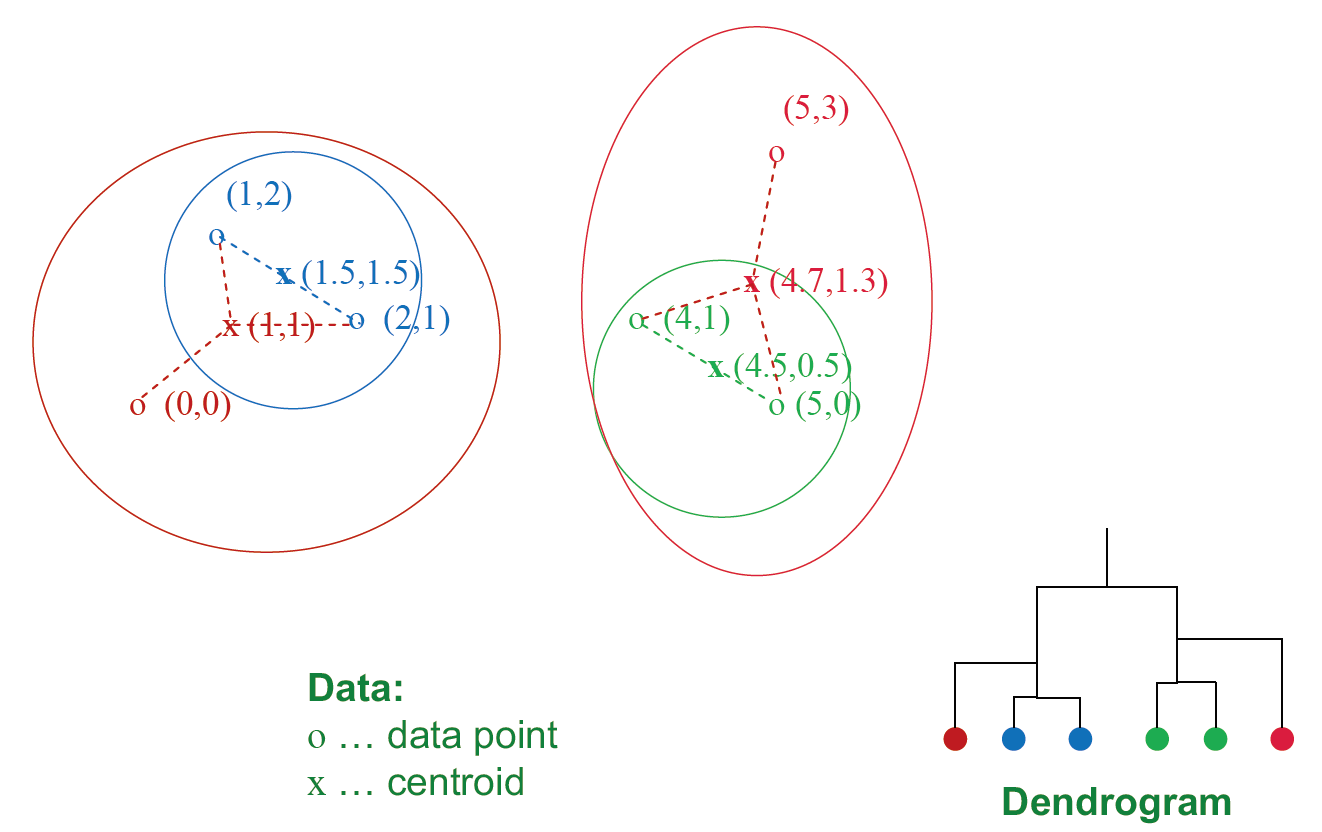
基于层次的聚类的实现
- 在每个步骤中,计算所有簇对之间的成对距离,然后合并
- 时间复杂度:\(O(N^3)\)
- 如果我们使用优先级队列可以将时间复杂度降解到 \(O(N^2 \log N)\),但是对于无法容纳在内存的大型数据集来说仍然太昂贵
其他层次聚类方法
聚集聚类方法的主要缺点:
- 伸缩性不好:时间复杂度至少为 \(O(n^2)\),其中 n 是对象总数
- 永远不能撤销以前所做的事情
将层次结构与基于距离的聚类集成
- BIRCH:使用 CF 树并逐步调整子簇的质量
- CURE:从聚类中选择分散良好的点,然后将它们向聚类中心缩小指定比例
BIRCH(层次聚类方法改进)
- BIRCH:平衡迭代减少和聚类使用层次结构(Zhang,Ramakrishnan & Livny,1996)
- 逐步构建 CF(聚类特征)树:
- 参数:最大直径,最大子代数
- 阶段 1:扫描数据库以构建初始的内存 CF 树(每个节点:#points,总和,平方和)
- 阶段 2:使用任意聚类算法对 CF 树的叶子节点进行聚类
- 线性扩展:通过一次扫描即可找到良好的聚类,并通过几次其他扫描来提高质量
- 弱点:仅处理对数据记录顺序敏感的数字数据。
聚类特征向量
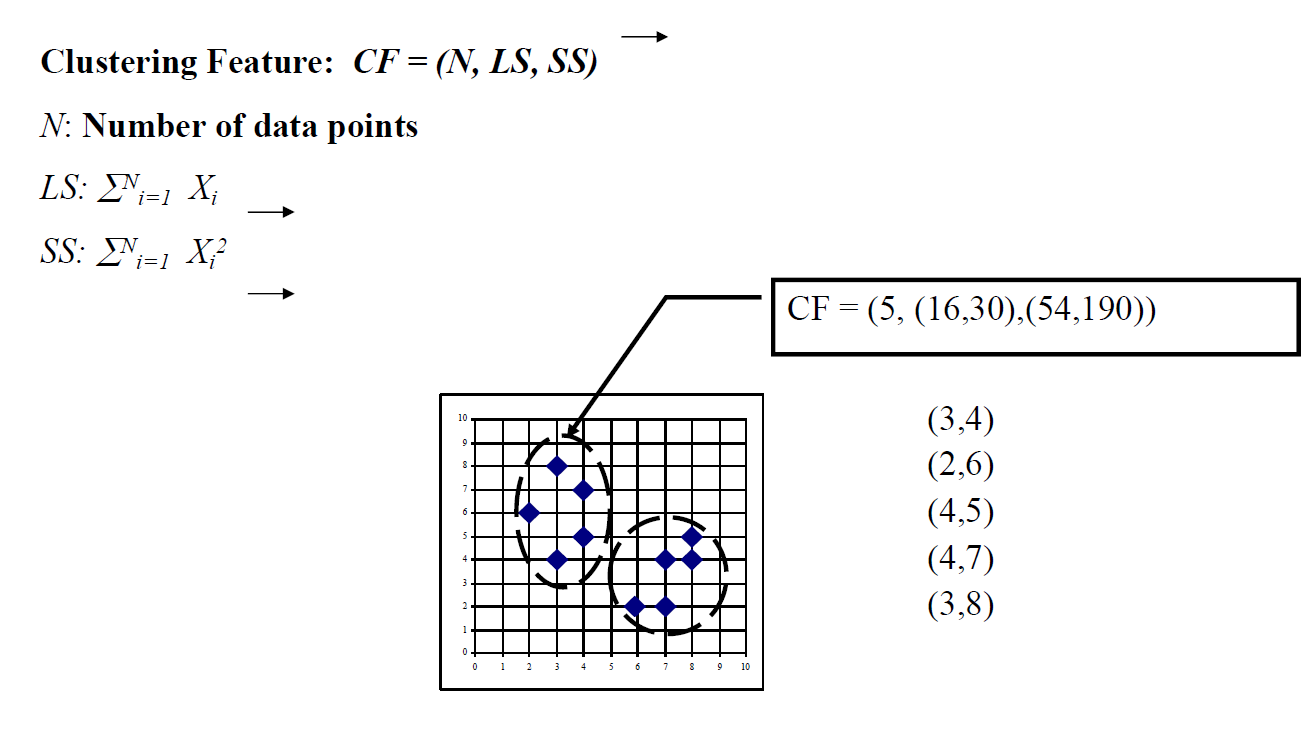
CF Tree
CURE(Clustering Using REpresentatives),层次聚类方法的改进
CURE:非球形簇,鲁棒的离群值
- 使用多个代表点评估群集之间的距离
- 如果一个级别包含 k 个簇,则停止创建簇层次结构
基于平方误差的聚类方法的缺点
- 仅考虑一个点作为簇的代表
- 仅适用于大小和密度相似的凸簇,并且如果可以合理估计 k
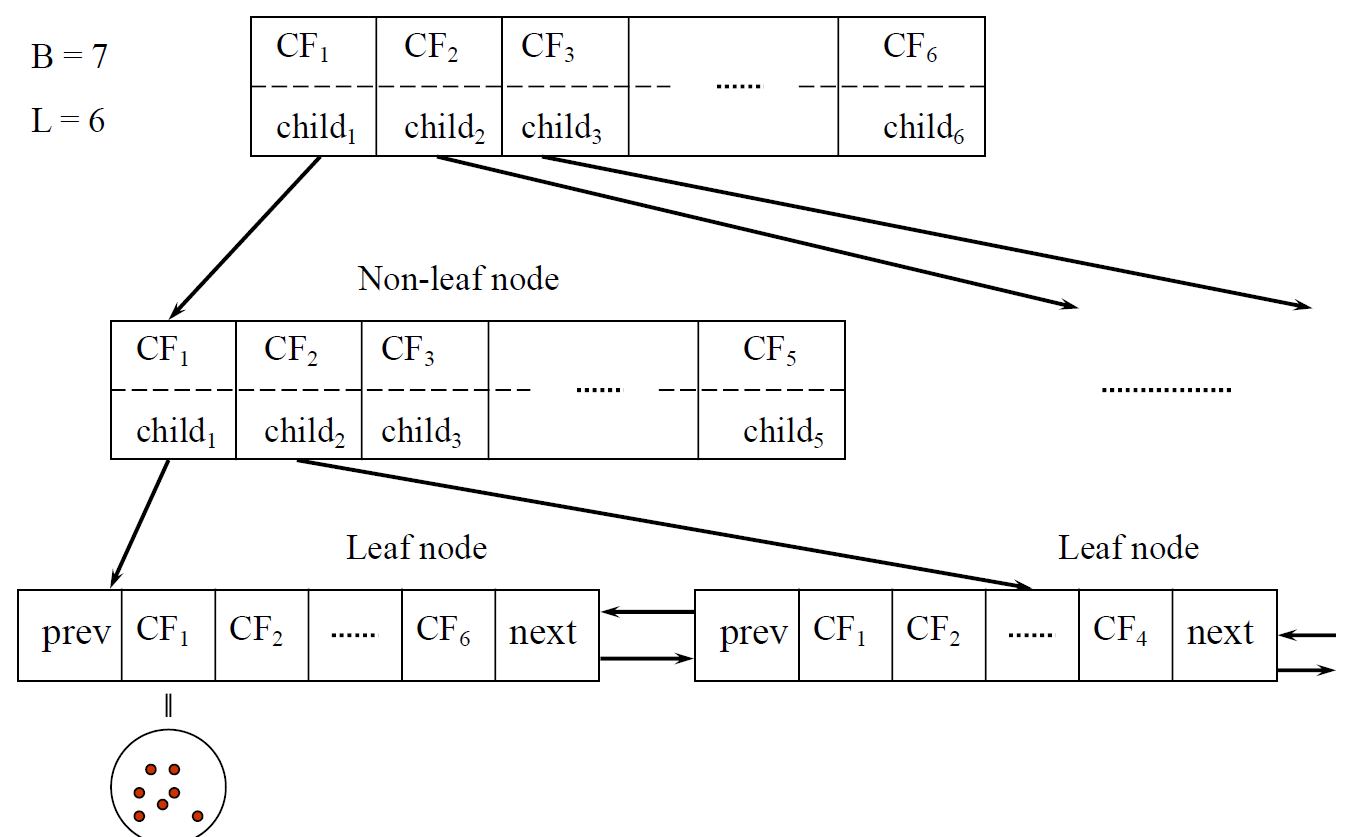
CURE 算法
- 抽取随机样本 s
- 分区样本为大小为 \(\frac{s}{p}\) 的 p 个分区
- 部分簇分区为 \(\frac{s}{pq}\) 簇
- 簇部分簇,不断缩小中心点
- 磁盘上的标签数据
数据划分和聚类
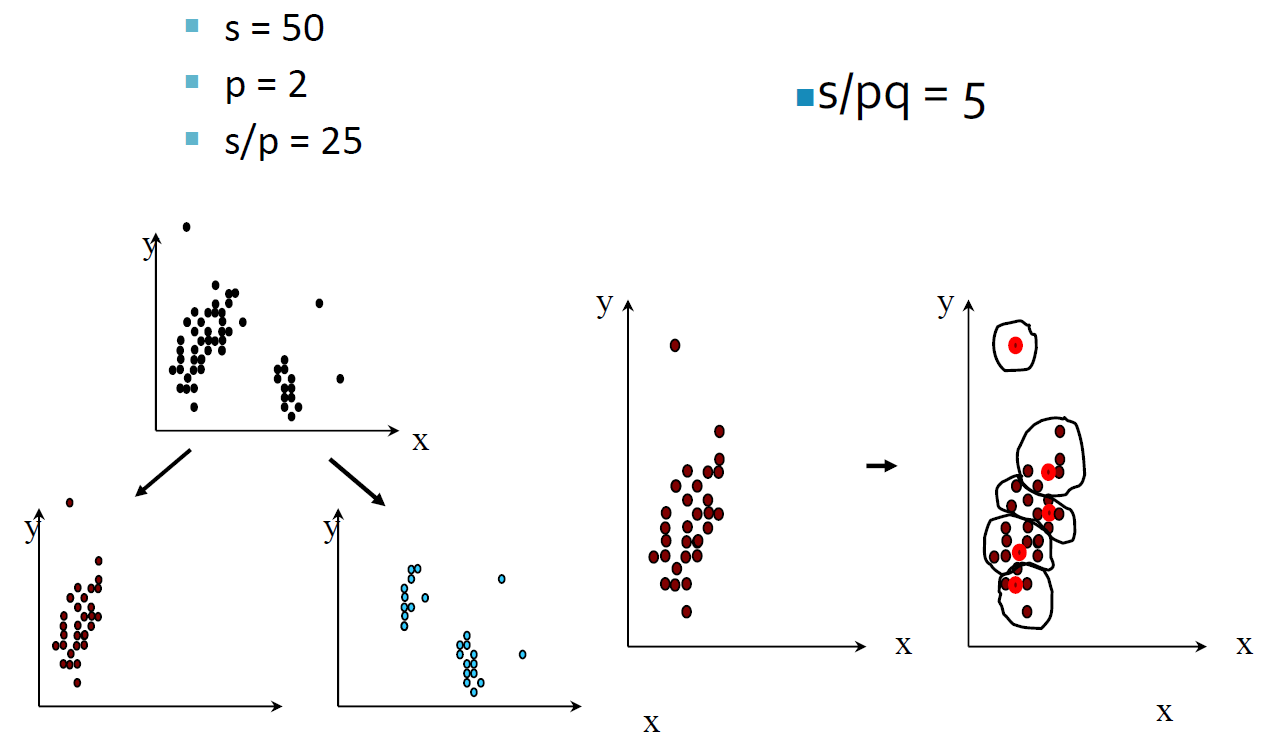
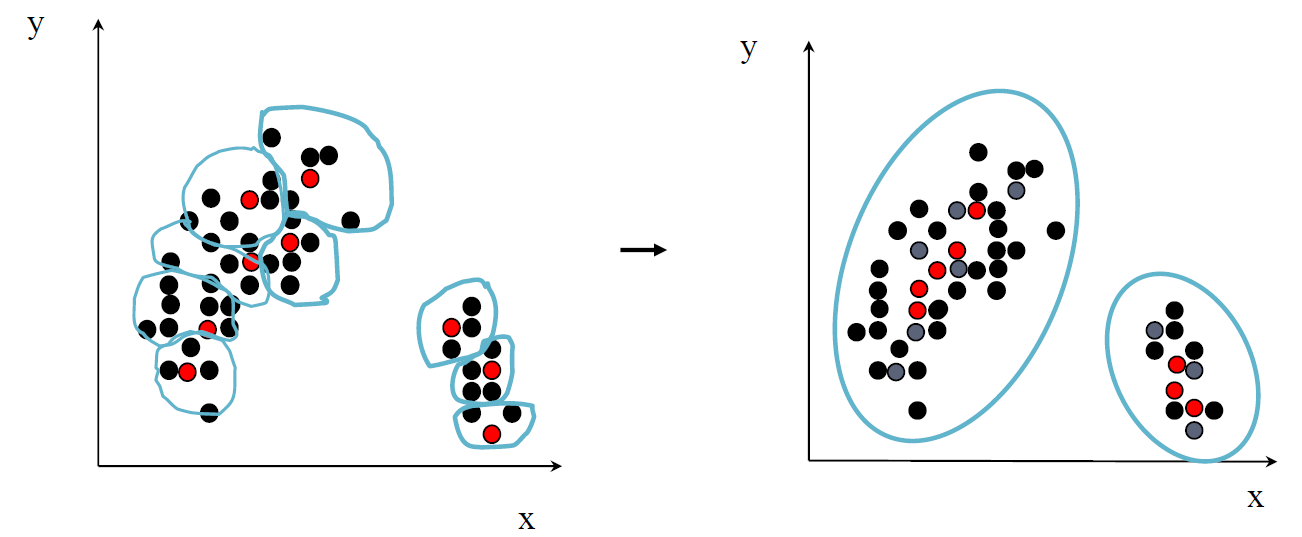
缩小代表点
- 将多个代表点向重心缩小几分之一。
- 多个代表捕获簇的形状
模型方法(Model-based methods)
基本思想:
- 把聚类作为概率估计
- 每个簇一个模型,提供一些参数
主要使用的是生成模型(Generative Model):假设数据是通过典型的概率分布生成的,满足相应的概率模型
- 选择簇的可能性
- 在簇中生成对象的可能性
- 推荐阅读:LDA 的推导
找到最大似然或 MAP 模型
使用 EM 算法
聚类的质量:测试集的结果
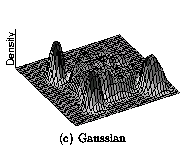
使用高斯方法合并
- 聚类模型:正态分布(均值,协方差)
- 假设:对角协方差,已知方差,所有聚类均相同
- 最大可能性:平均值 = 样本均值
- 但是给定簇的样本是什么?对应点属于簇的概率
- 平均值=点数和权的加权平均值,权就是概率
- 但要估计概率。我们需要模型
- “鸡和鸡蛋”问题:使用 EM 算法
使用 EM 算法合并
- 初始化:随机选择均值
- E 步骤:
- 对于所有的 point 和 mean,计算 \(Prob(mean|point) = \frac{Prob(point|mean)}{Prob(point)}\)
- M 步骤
- 每一个 mean 都等于所有点的加权(Weight)均值
- 权(Weight)= \(Prob(mean|point)\)
- 重复直到收敛
- 保证收敛到局部最优
- K 均值算法是 EM 算法的特例
EM 算法
【机器学习基础】EM 算法:https://blog.csdn.net/u010834867/article/details/90762296
使用自分类合并
- 由 NASA 发明,使用了贝叶斯模型,在实践中被广泛使用
- \(Prob(attribute|class)\) 的各种可能模型
- 缺少信息:每个样本点的类簇
- 像以前一样应用 EM 算法
- 缺少值的学习贝叶斯网的特殊情况
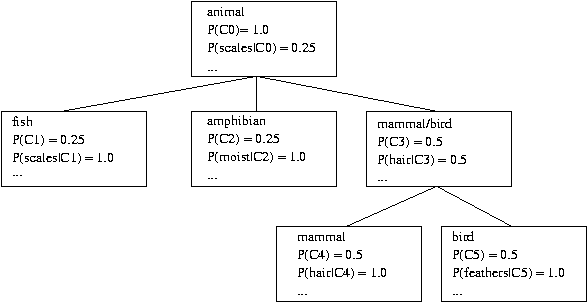
COBWEB 方法
- 生成聚类树
- 每一个节点都有 \(P(cluster)\) 和 \(P(attribute|cluster)\) 对每一个属性
- 物体被线性按序表示
- 操作:添加节点、新节点、合并、划分
- 质量度量:类别实用程序:增加属性/簇的可预测性
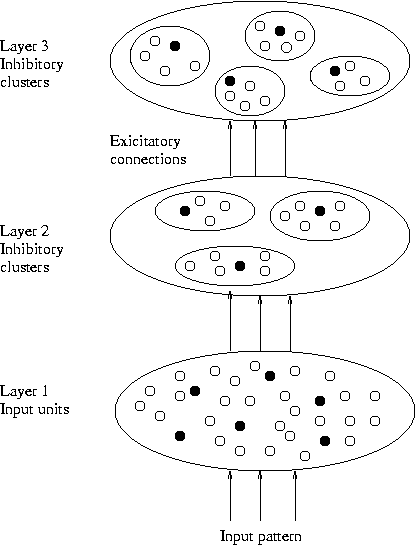
神经网络方法
- 神经元 = 簇 = 内部空间的 centroid
- 层 = 层次的级别
- 每层中有几个竞争的簇集
- 将对象顺序呈现给网络
- 在每个集合中,神经元竞争赢得对象
- 获胜的神经元移向物体
- 可以看作是从低级功能到高级功能的映射
自组织特征映射(Self-organizing Feature Maps)
- 通过让多个单元竞争当前对象来执行聚类
- 权重向量最接近当前物体的单位获胜
- 获胜者及其邻居通过调整权重来学习
- SOM 被认为类似于大脑中可能发生的过程
- 有助于可视化二维或 3-D 空间中的高维数据
基于密度的方法
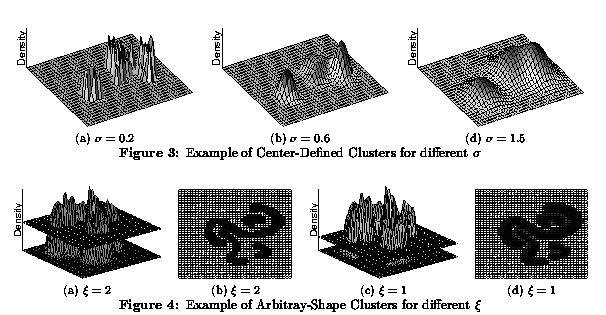
可以处理非凸数据
基于密度(局部聚类标准)的聚类,例如密度连接点
主要特点:
- 发现任意形状的簇
- 处理噪音
- 一次扫描
- 需要密度参数作为终止条件
代表性算法:
- DBSCAN(Ester 等,1996)
- DENCLUE(Hinneburg & Keim,1998)
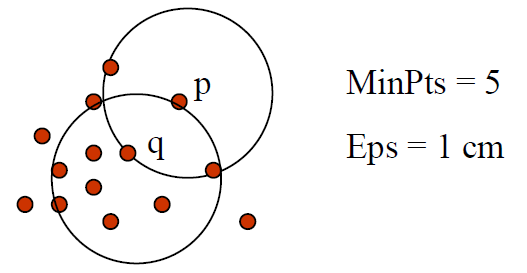
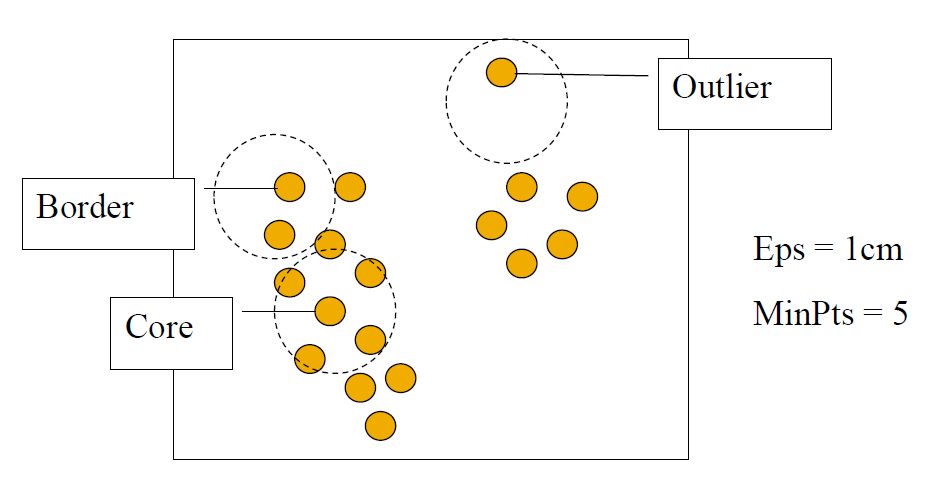
基于密度的方法的参数
- 两个参数
Eps:最大邻域半径MinPts:点的 Eps 邻域中的最小点数
\[ N_{Eps}(p) = \{q \in D | dist(p, q) \leq Eps\} \]
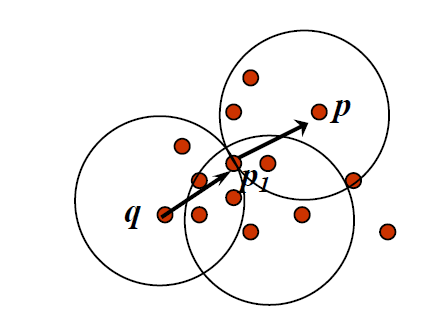
- 直接密度可达:一个点和另一个点直接密度可达,当且仅当 q 关于 Eps, MinPts 满足如下条件
- \(p \in N_{Eps}(q)\)
- q 是关键点:\(|N_{Eps}(q)|\geq MinPts\)
- 如果使用 p 进行计算,没有找到点,则为边界点,然后使用下一个点进行查找
- 密度可达:如果有一条链\(p_1,...,p_n, p_1 = q,p_2 = p\),并且\(p_i\)和\(p_{i+1}\)两两可达,则点 p 和点 q 关于 Eps、MinPts 密度可达
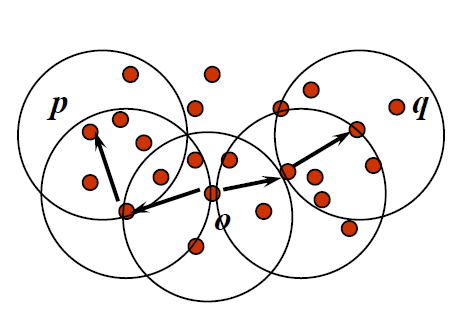
- 密度连接:如果这里有一个点 o,对于点 p 和点 q 都是点 o 关于 Eps、MinPts 密度可达,则点 p 和点 q 密度连接
| Density-reachable | Density-connected |
|---|---|
 |
 |
BNSCAN:Density Based Spatial Clustering of Applications with Noise
- 依靠基于密度的聚类概念:聚类定义为密度连接点的最大集合
- 发现带有噪声的空间数据库中任意形状的簇

DENCLUE:使用密度函数
- 基于密度的簇(Hinneburg & Keim,1998)
- 主要特点:
- 适用于噪声较大的数据集
- 允许对高维数据集中任意形状的簇进行紧凑的数学描述
- 比其他算法快很多(比 DBSCAN 快 45 倍),但是需要大量参数
- 使用网格单元,但仅保留有关确实包含数据点的网格单元的信息,并在基于树的访问结构中管理这些单元。
- 影响功能:描述数据点在其邻域内的影响。
- 数据空间的整体密度可以计算为所有数据点的影响函数的总和。
- 可通过识别密度吸引子以数学方式确定聚类。
- 密度吸引子是整体密度函数的局部最大值。
- 影响函数例子
\[ \begin{array}{l} f_{Guassian}(x,y) = e^{-\frac{d(x,y)^2}{2\delta^2}} \\ f^D_{Gaussian}(x) = \sum\limits_{i=1}^{N} e^{-\frac{d(x, x_i)^2}{2\delta^2}} \\ \triangledown f_{Gaussian(x, x_i)}^D(x, x_i) = \sum\limits_{i=1}^{N} (x_i - x) e^{-\frac{d(x, x_i)^2}{2\delta^2}} \end{array} \]
 |
 |
 |
|---|
评价聚类的好坏
内部标准
良好的簇将产生高质量的簇,其中:
- 组内(即组内)相似度很高
- 组间相似度低
- 群集的测量质量取决于文档表示形式和所使用的相似性度量
外部标准
- 通过发现黄金标准数据中某些或所有隐藏模式或潜在类别的能力来衡量质量
- 评估关于真正的聚类:需要标记的数据
- 假设文档使用 C 黄金标准类,而我们的聚类算法将生成带有\(n_i\)个成员的 K 个聚类\(w_1, w_2, ..., w_n\)。
简单的度量:纯度
- 群集 \(\pi i\) 中的优势类与群集 \(\omega i\) 的大小之比
\[ Purity(w_i) = \frac{1}{n_i}\max\limits_{j}(n_{ij}), j \in C \]
- 有偏差,因为具有 n 个簇使纯度最大化
- 其他是簇中类的熵(或类与簇之间的相互信息)

配对决策之间的兰德指数度量(RI = 0.68)
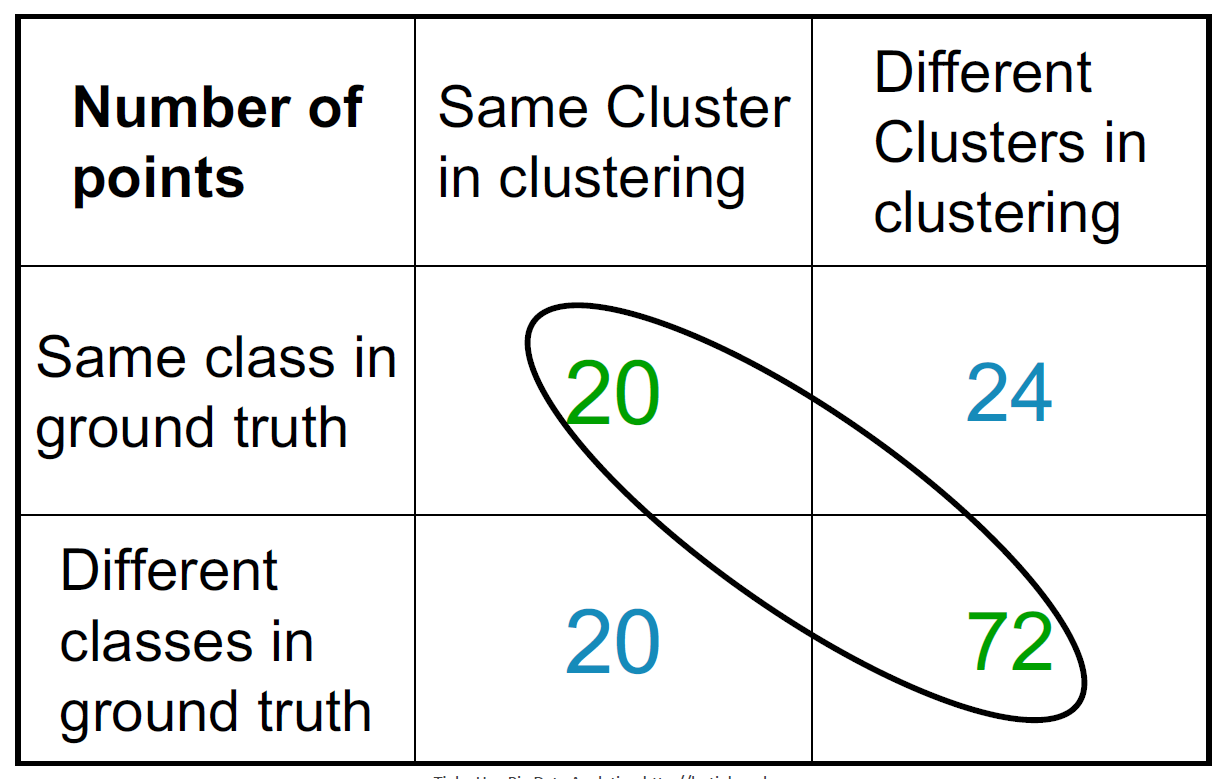
Rand Index 和簇 F 度量
\[ RI = \frac{A + D}{A + B + C + D} \]
- 比较标准准确率和召回率
\[ \begin{array}{l} P = \frac{A}{A + B} \\ R = \frac{A}{A + C} \\ \end{array} \]
- 人们还定义和使用簇 F 度量,这可能是更好的度量。
总结
- 在聚类中,无需人工输入即可从数据推断聚类(无监督学习)
- 但是,在实践中,还不太清楚:影响聚类结果的方法有很多:聚类数,相似性度量,文档表示,

