大数据导论
数据挖掘是什么?
发现具有以下特征的模式(模型):
- 有效性
- 可用性
- 出乎意料
- 可理解性
什么是数据挖掘:在大量数据的情况下发现数据的有效的,可用的,新的,可理解的模式
数据挖掘的常见任务:
- 描述类方法:如聚类,找出人类可理解的模式来描述数据
- 预测类的方法:如推荐系统,使用一些变量来预测未知的或者未来的其他变量的值
数据挖掘的风险:发现”没有价值的模式
在数据挖掘中需要考虑三个维度的问题:
- 挑战性:数据是否可测量、质量如何,能否有效利用等;
- 操作性:数据如何收集和准备,数据如何建模,如何解释数据乃至于实现数据可视化;
- 数据的形态:数
- 据是结构化的数据吗?是网络数据?文本数据?多媒体?
大数据平台
考察记忆性内容
Hadoop 是一个开发和运行大规模数据分析程序的软件平台,是一个开源的软件框架,在大量普通服务器组成的集群中对大量数据实现分布式的计算。
其主要模块包括:Hadoop Common;Hadoop Distributed File System(HDFS);Hadoop YARN;Hadoop MapReduce。
Hadoop 相关 Apache 项目

作用与功能
- 采用 HDFS,提高读写速度,扩大存储容量
- 采用 MapReduce 来整合分布式文件系统上的数据,提高分析和处理数据的效率
- 基于 Java 语言开发的,这使得其可以部署在低廉的计算机集群中,且不限操作系统
- 采用存储冗余数据的方式保证了数据的安全性
Hadoop 中 HDFS 的数据管理能力,MapReduce 处理任务时的高效率,以及它的开源特性,使其在同类的分布式系统中大放异彩,并在众多行业和科研领域中被广泛采用。
与传统关系型数据库的比较
| 传统关系型数据库 | MapReduce | |
|---|---|---|
| 数据大小 | GB | PB |
| 访问 | 交互型和批处理 | 批处理 |
| 更新 | 多次读写 | 一次写入多次读取 |
| 结构 | 静态模式 | 动态模式 |
| 集成度 | 高 | 低 |
| 伸缩性 | 非线性 | 线性 |
优点
- 可靠的,维护多个工作数据副本 存储冗余数据
- 高效的,并行工作,可伸缩,能够处理 PB 级数据 使用 MapReduce
- 成本低,依赖于廉价服务器,任何人都可以使用 基于 Java 语言开发
- 运行在 Linux 平台上,带有 Java 语言编写的框架,运行在 Linux 生产平台上是非常理想的
- 支持多种编程语言,应用程序可以使用其他语言编写
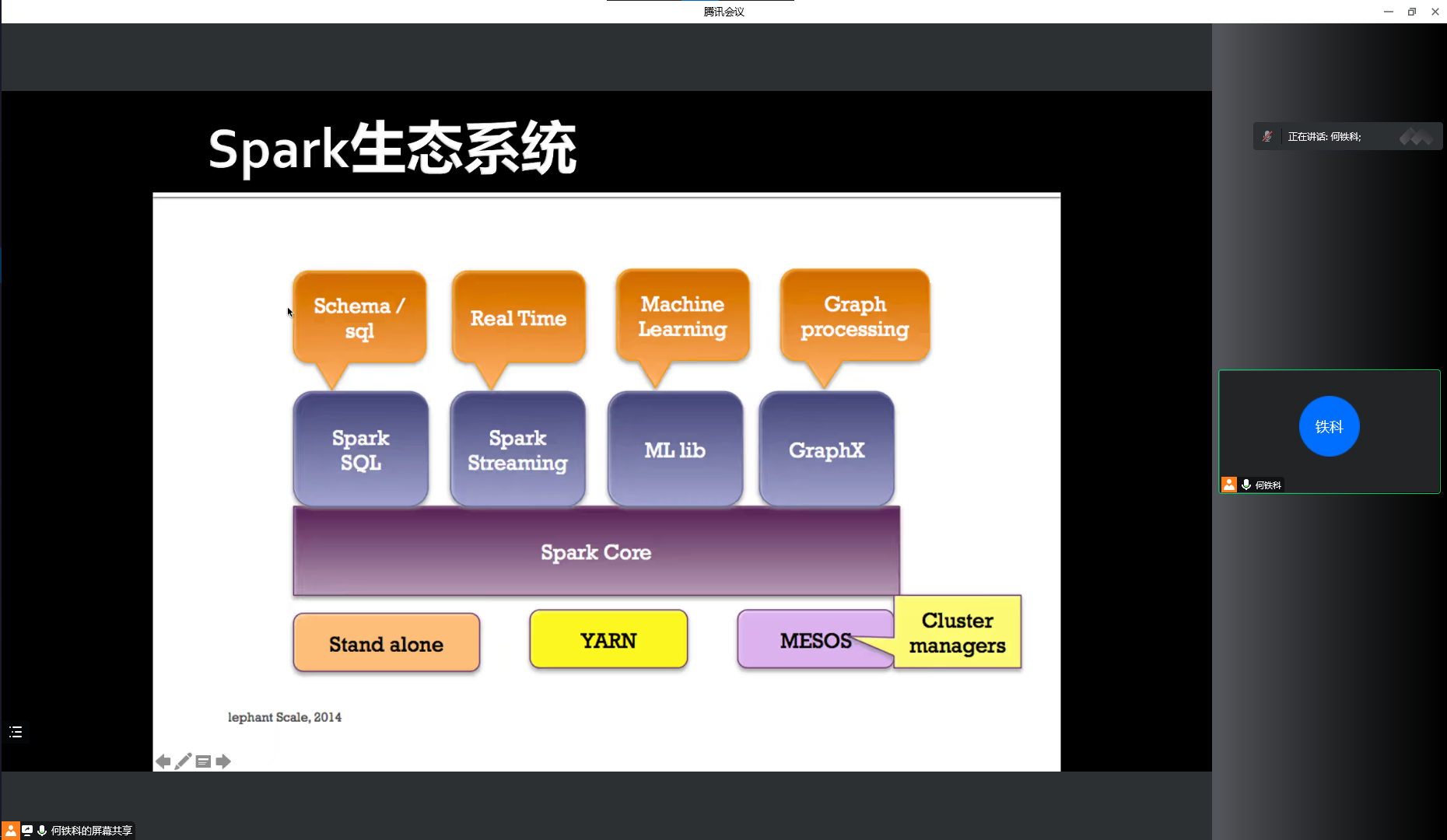
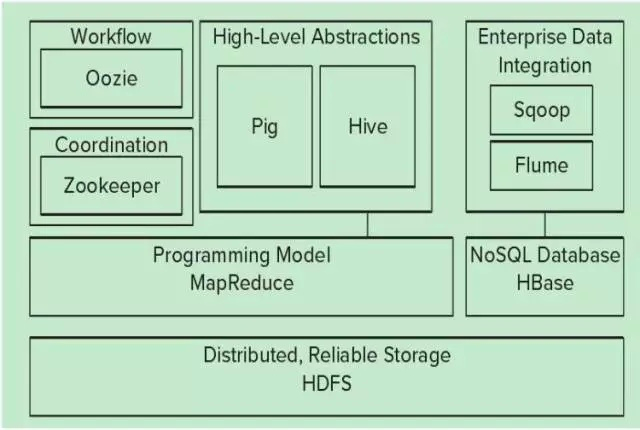
生态圈
- 分布式可靠存储 HDFS:HDFS 是一种分布式文件系统,运行于大型商用机集群,为 HBase 提供了高可靠性的底层支持
- 编程模型 MapReduce:MapReduce 是一种分布式数据处理模式和运行环境,为 HBase 提供高性能的计算能力
- NoSQL 数据库 HBase:HBase 是一个分布式的列存储数据库
- 高层抽象 Pig & Hive:Pig 是一种数据流语言和运行环境,用于检索非常大的数据集,极大地简化了常见任务;Hive 是一个建立在 Hadoop 基础上的数据仓库,提供了一些用于数据整理、特殊查询和分析存储在 Hadoop 文件中的数据集的工具
1 代架构与 2 代架构
Client 链接到 Job Submission Node,由其中的 JobTracker 程序负责,JobTracker 同时还链接到各个 Slave Node 中的 TaskTracker,各个 Slave Node 中的 DataNode 由 HDFS Master 中的 NameNode 负责。
即一代架构中 MapReduce 模块负责了数据了数据处理和资源集中管理;
而二代架构中数据处理由 MapReduce 和其他模块负责,资源集中管理由新的 YARN 模块负责。
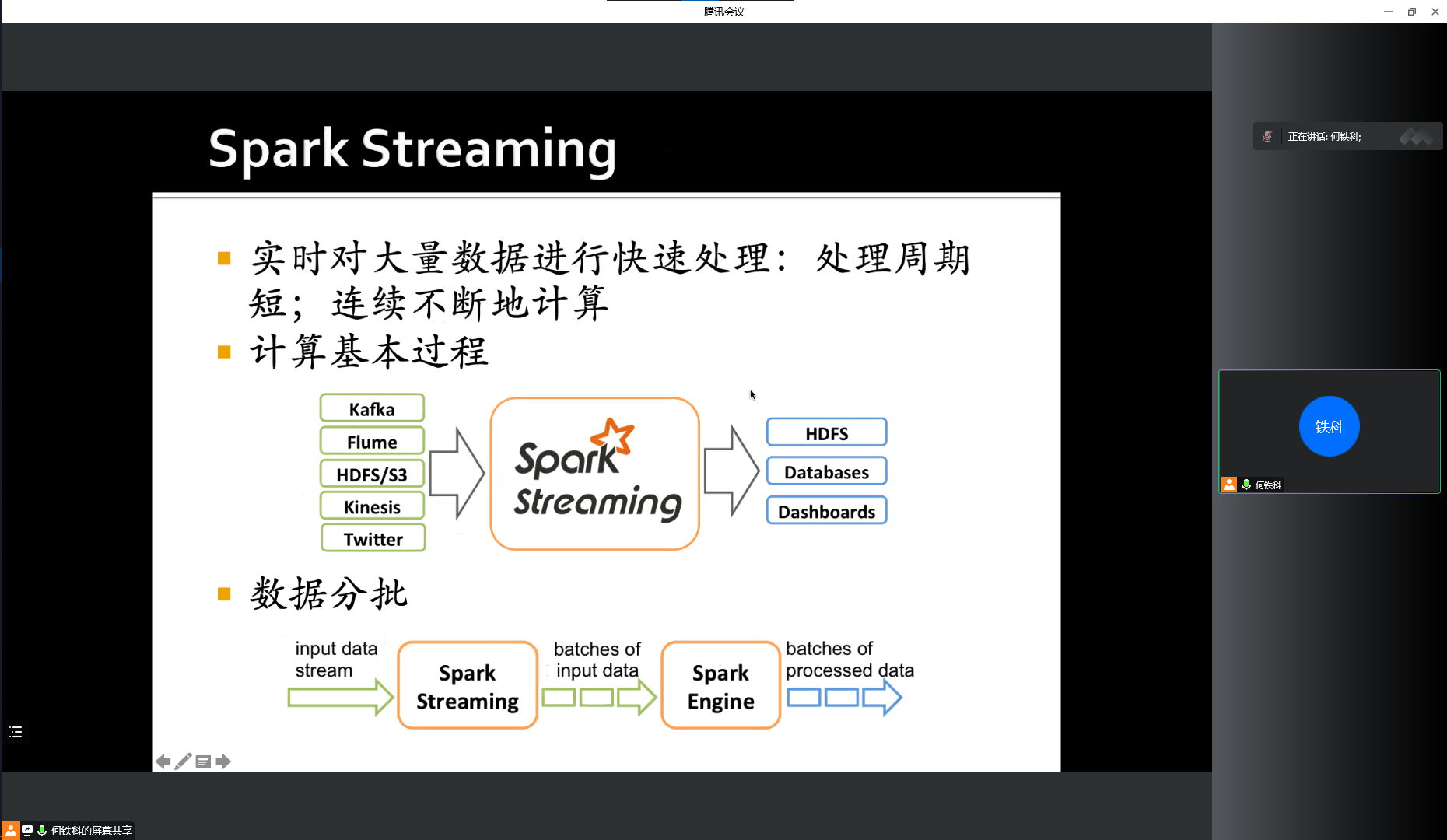
MapReduce
Hadoop 与分布式开发
Hadoop 使用 MapReduce 计算模型,非常适合于在大量计算机组成的大规模集群上并行运行。每一个 map 任务和 reduce 任务均可同时运行于单独的计算节点上,保证运算高效率。
并行计算的实现通过数据的分布存储,分布式的并行计算和本地计算,划分任务粒度,分割、合并、Reduce 数据,再经由任务管道实现。
Input - Map - Sort - Combine - Partition - Reduce - Output
HDFS
数据存储操作
- 适合大量的大文件
- 适合一次写入,多次读出的场合
- 单个文件的内容不可被修改,除非在文件尾添加新数据
- 可进行的操作:
- 创建新文件
- 向文件尾添加内容
- 删除文件
- 修改文件名
- 修改文件属性
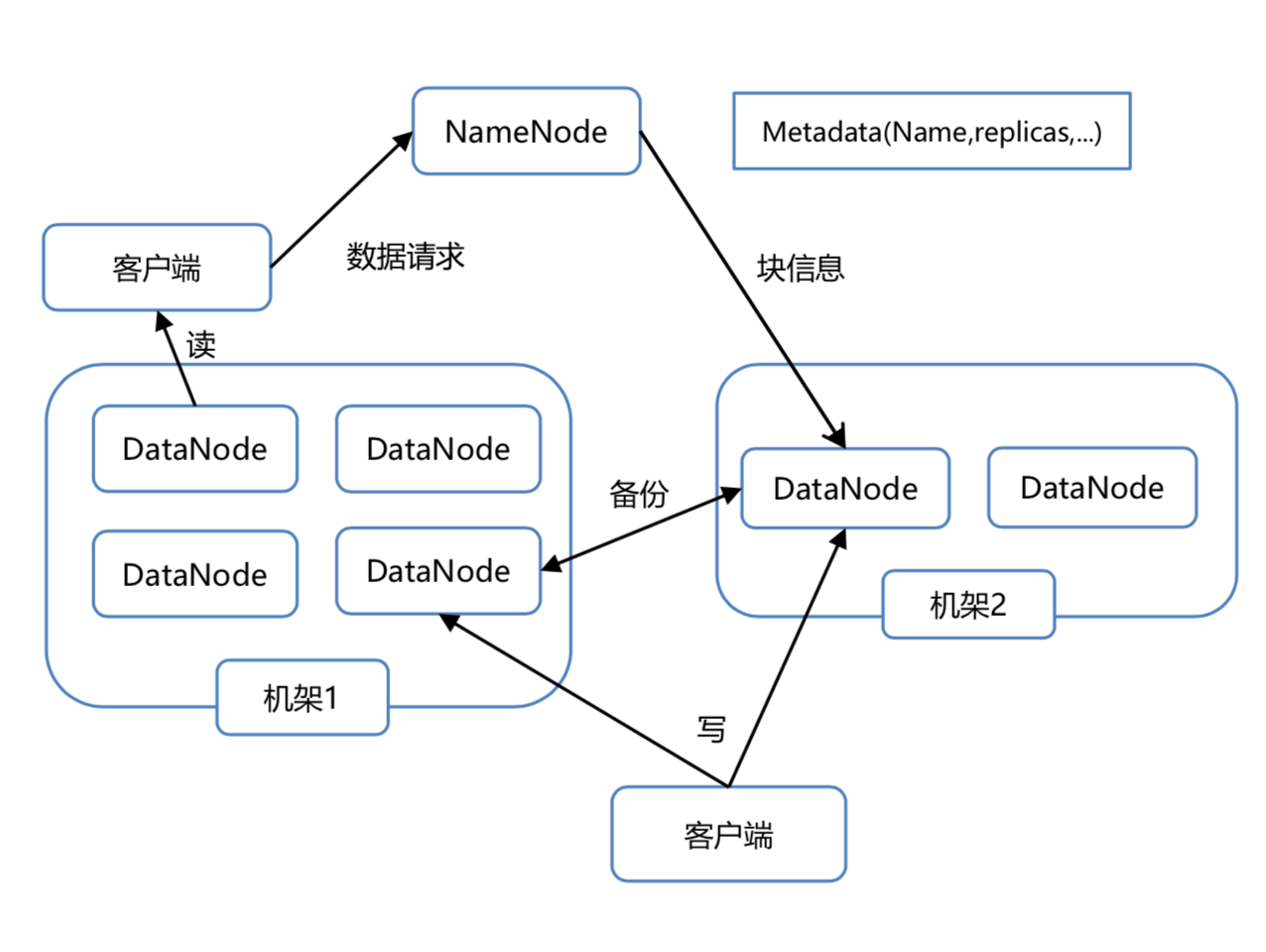
架构
客户端从服务器机架的 DataNode 中读取数据,将 Metadata 放在 NameNode 中以 Block 发送给机架,机架中的 Blocks 中存放 DataNode,多个机架冗余存储数据拷贝,服务器向 DataNode 中写入数据。(块 1.0 默认 64M 2.0 默认 128M)
Namenode
管理者,存储文件系统的 metadata,负责管理文件系统的命名空间,集群配置信息,存储块的复制。
包括两个文件:EditLog 和 FsImage。
Secondary Namenode
相当于秘书,负责合并和保存 EditLog 和 FsImage。
DataNode
文件存储的基本单元。存储文件块到本地文件系统中,保存了文件块的 metadata,同时周期性地发送所有存在的文件块的报告给 Namenode。
基本原理
读文件
HDFS 客户端打开分布式系统;从 NameNode 中获取节点位置;读取 FSData InputStream;InputStream 从多个 DataNode 中读取数据;关闭 FSData InputStream
写文件
HDFS 客户端创建分布式系统;创建 NameNode ;向 FSData OutputStream 中写入数据;OutputStream 向多个 DataNode 写入包;OutputStream 确认包写入完成;关闭 FSData OutputStream;完善 NameNode 内容
HBase
- 一个数据库
- 分布式的、非结构化的,稀疏的,面向列的
- 基于 HDFS,山寨版的 BigTable,继承了可靠性、高性能、可伸缩性
介绍
- 以 Java 编写
- 在 HDFS 基础上开发的分布式数据库
- 提供一种容错的方式存储大量的非结构化的稀疏数据
- 可靠,高效
数据模型
- Table
- RowKey 主键,记录按照主键排序
- Timestamp 每次数据操作的时间戳,相当于 version number,可用于垃圾清理
- Column Family 由任意多个 Column 组成
- Region
- 记录增多后,Table 会逐渐分裂成多份 splits,成为 region
- region 由 [startkey, endkey) 表示
- 不同 region 会被 master 分配给相应的 regionserver 进行管理
- .META. 记录用户表的 Region 信息,可以有多个 region
- -ROOT- 记录 .META. 表的 Region 信息,只有一个 region
- Zookeeper 记录了 -ROOT- 表的 location
角色
- Zookeeper 高效的,可拓展的协调系统,并不属于 HBase,是 Hadoop 的子项目
- HMaster 管理对 Table 的增删改查,和 HRegionServer 的负载均衡
- HRegionServer 管理一系列 HRegion,Region 读写的地方
- HRegion 对应 Table 的一个 Region,包含 HStore,HLog
- HStore 对应 Table 中一个 Column family 的存储,包含 MemStore,StoreFile(HFile)
- StoreFile 包含 Compact 和 split
Hive
Hive 是基于 Hadoop 的数据仓库工具
- 学习成本低
- 提供完整的 sql 查询功能
- 可以将结构化的数据文件映射为一张数据库表
- 可以将 sql 语句转换为 MapReduce 任务进行运行。
- 可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用
介绍
- 基于 Hadoop 的数据仓库工具
- 提供完整的 sql 查询功能,学习成本低
- 可以将结构化的数据文件映射为数据库表
- 可以将 sql 语句转换为 MapReduce 任务运行
运维要点
- 元数据应使用单独的数据库存储
- 表分区和主键需定义合理
- 分桶数据量合理
- 表压缩
- 定义外部表使用规范
- 合理控制 Mapper Reducer 数量
Pig
介绍
使用 Pig Latin 语言编写 Pig 脚本执行特定任务,应用 Pig 框架的一系列转换来生成所需输出,Pig Latin 提供了丰富的数据类型和操作符,Pig 在内部会将降本转换为一系列 MapReduce 作业,减轻程序员工作
架构
- Parser 解析器检查脚本语法,类型检查和其他检查,输出逻辑运算符为节点,数据流表示的边的有向无环图
- Optimizer 优化器对有向无环图进行优化
- Compiler 编译器将优化后的逻辑计划编译为一系列 MapReduce 作业
- Execution engine 执行引擎将 MapReduce 作业顺序提交到 Hadoop
链接分析
图数据
社交网络,媒体网络,信息网络,技术网络,Web 页面组织
链接分析算法 PageRank

- “流”模型小规模例子 2. 求解矩阵等式 r = M _ r 1. 特征值为 1 的特征向量 2. Power Iteration 从 1/n 开始迭代 1. 原理 M^k _ r0 逼近 M 的主特征向量
- Random Walk
- 存在性和唯一性
两大问题
Dead Ends
- Always Teleport 随机跳转到别的页面
Spider Traps
- Teleports 一部分可能(0.8-0.9)随机选择一条出路径,一部分可能随机跳转到别的页面
Google Matrix A = b _ M + (1-b)*[1/N]_(N*N)*
Page Rank 完整算法正常迭代+均分损失概率
数据降维
目的
- 发现隐藏的联系和主题
- 移除相似和噪音
- 数据解释和可视化
- 便于处理和存储
标准 SVD(无失真)

- A[m*n]=U[m*r]*X[r*r]*(V[n*r])^T
- r 矩阵秩
- X 对角矩阵
SVD vs. CUR
- 稠密稀疏大小
分类
Bayes

- 计算属于各个类别的概率最大类
Decision Tree
- 节点 + 边内部节点为特征,外部节点为类别
- 构建决策树
- ID3 算法
- 使用所有没有使用的属性并计算相关的样本熵值
- 信息熵
- 信息增益率
- 选择熵值最小的
- 生成节点
- 使用所有没有使用的属性并计算相关的样本熵值
- C4.5 算法克服 ID3 问题
- 偏向于选择分支比较多的属性值,即取值多的属性
- 不能处理连续属性
- CART 算法 Classification And Regression Tree 分类回归树算法
- 将样本递归划分进行建树的过程
- 用验证数据进行剪枝
- GINI 指数
- gini
- Gini(split)
- 连续特征的处理两个之间取中值 N 条样本 -> N-1 种离散方式
- ID3 算法
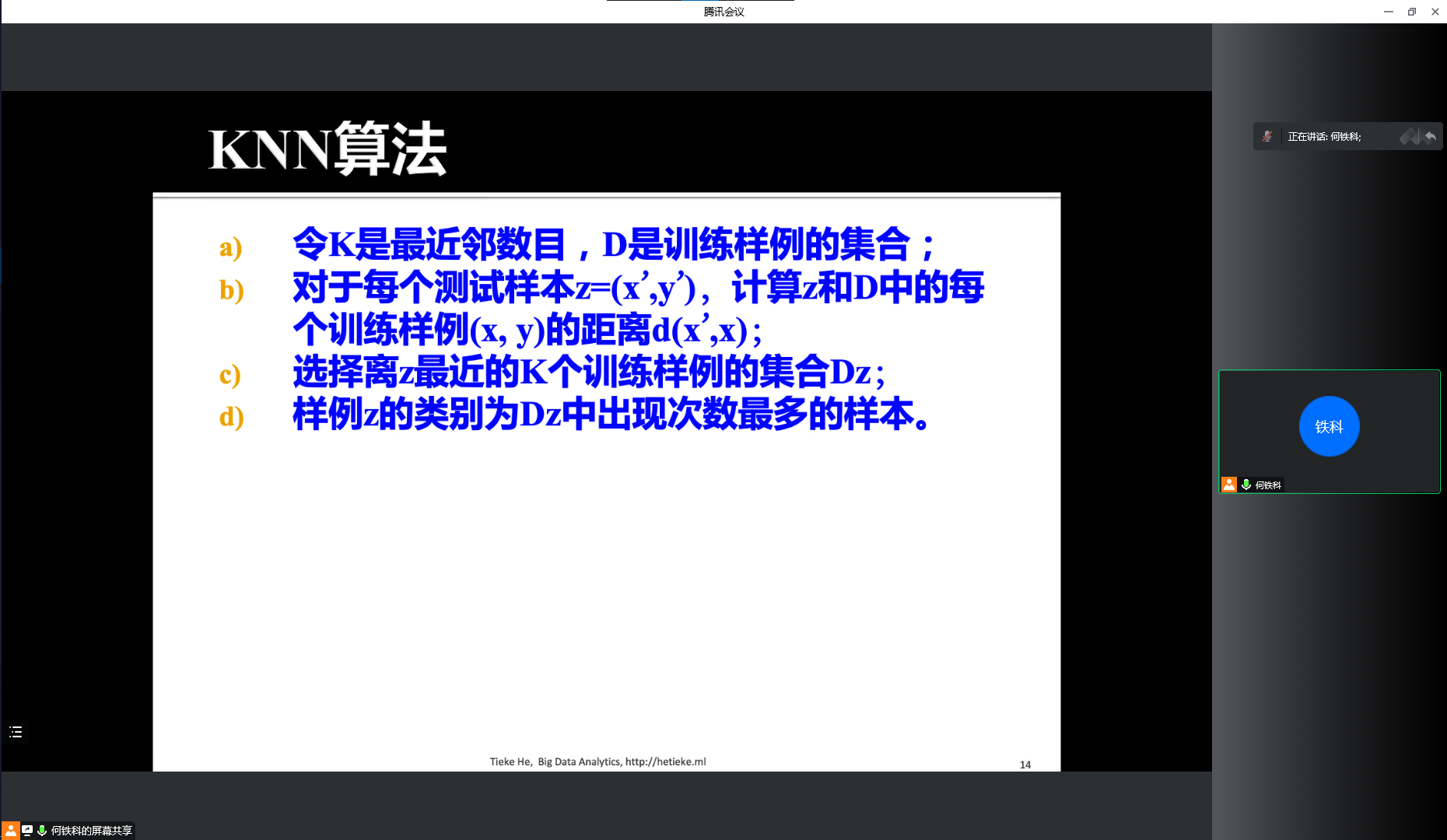
KNN
- K 最近邻的数目,计算距离,离 z 最近的若干样本中出现次数最多的为一类
- 归一化
SVM
Logistic Regression
神经网络
深度学习
集成学习
聚类
- 硬聚类一个样本只属于一个类别
- 软聚类一个样本可能属于多个类别
方法论
- Partitioning methods 构建一种将数据库中的数据划分为几个类别的方法
- 全局优化:全枚举
- 启发式方法
- k-means 所有类别由中心模拟成员表示
- k-medoids 所有类别由类别中的一个成员表示
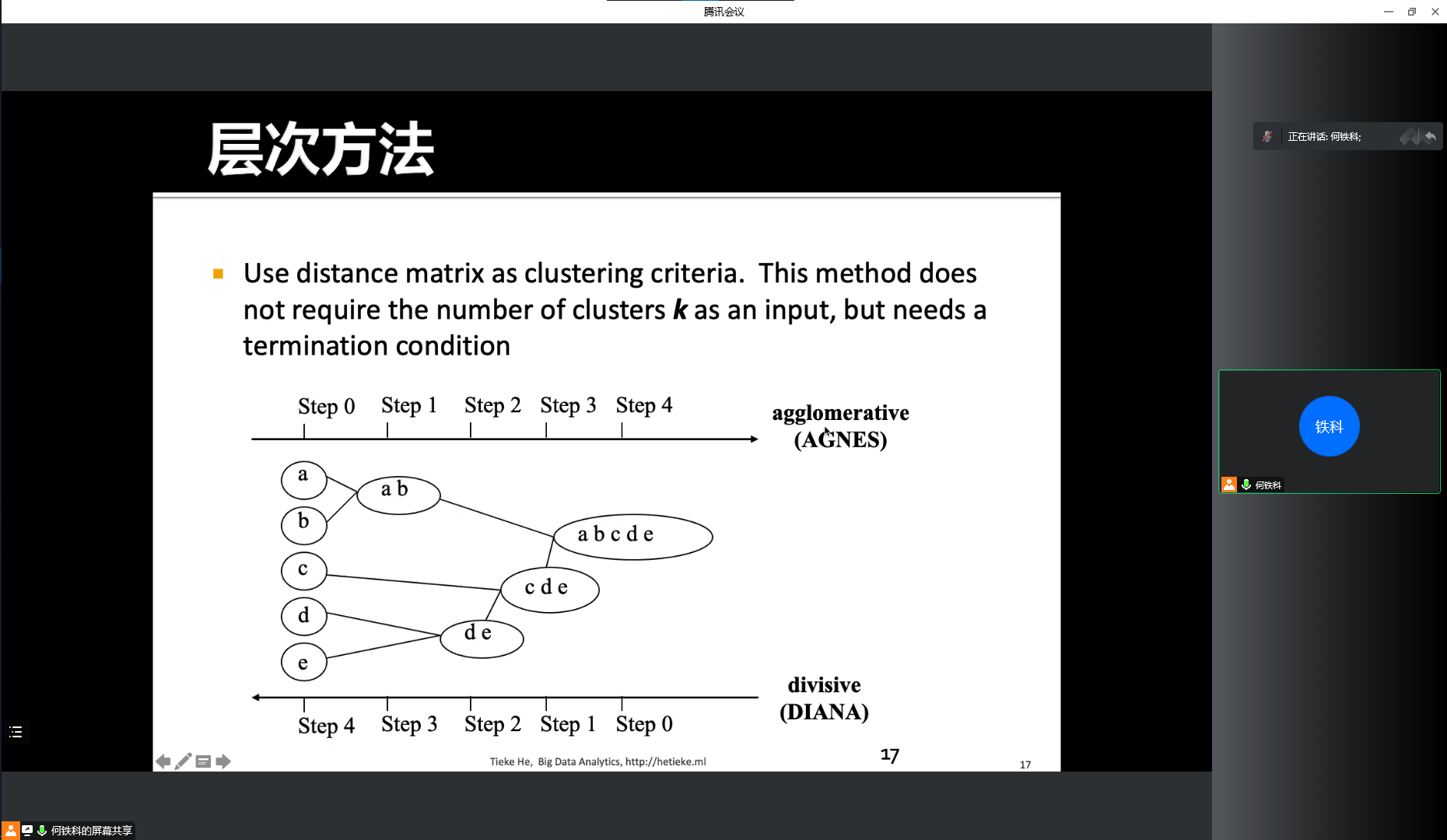
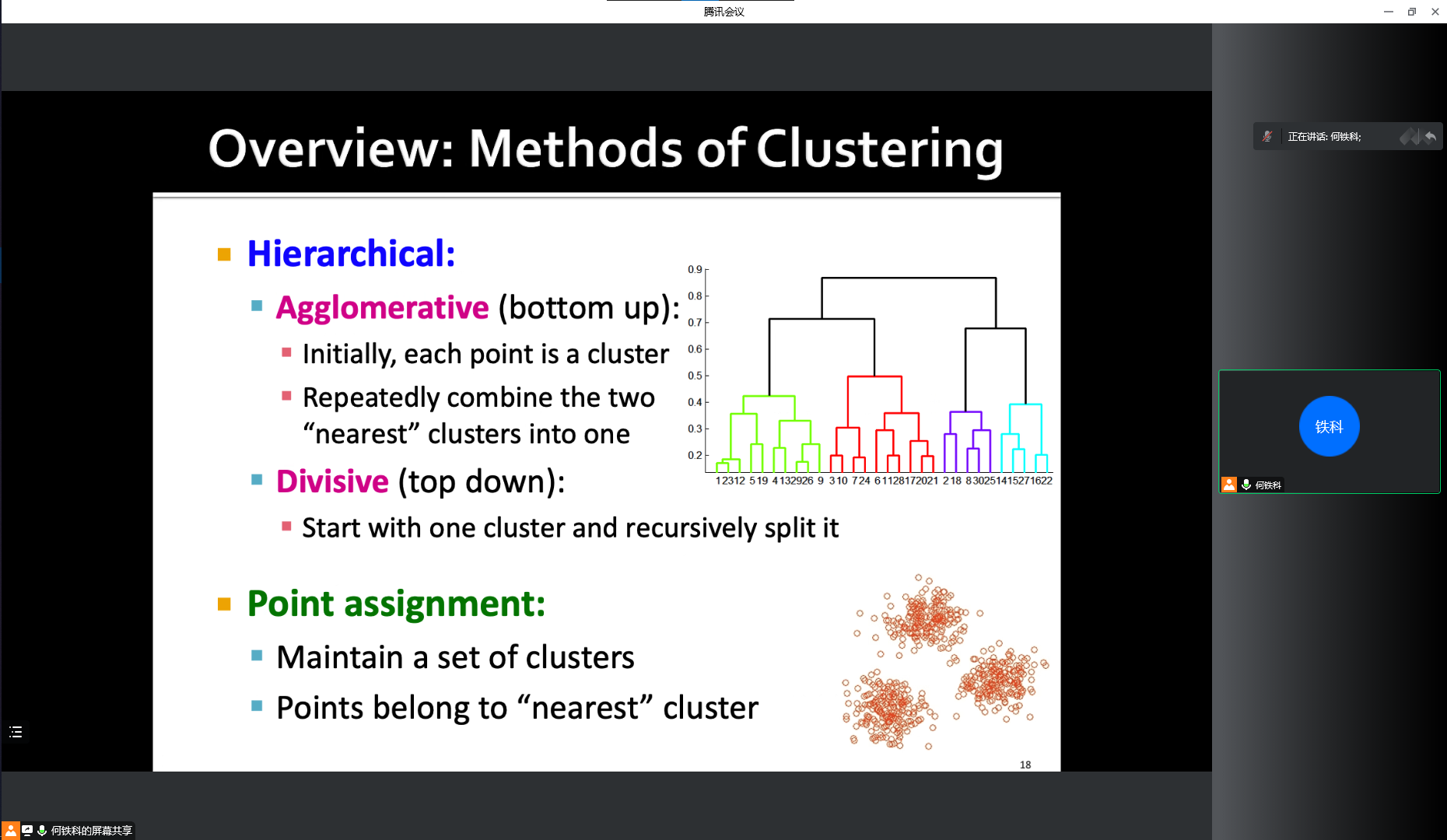
- Hierarchical methods 层次化方法
- 自下而上重复合并最近的两个类别
- 点分配(点属于“最近”的集群)
- “最近”集群定义
- single-link
- complete-link
- centroid
- average-link
- “最近”集群定义
- 点分配(点属于“最近”的集群)
- 自上而下
- 自下而上重复合并最近的两个类别
- Model-based methods
- Density-based methods
- K-Means 算法
- 优点
- 相对有效,复杂度和开销可控
- 以局部最优终止,可使用退火、遗传等其他算法达到全局最优解
- 缺点
- 只有定义了 mean 才可用
- 需要提前指定 k
- 存在噪音数据和异常值的问题
- 不适合具有非凸形状的类别簇
- 优点
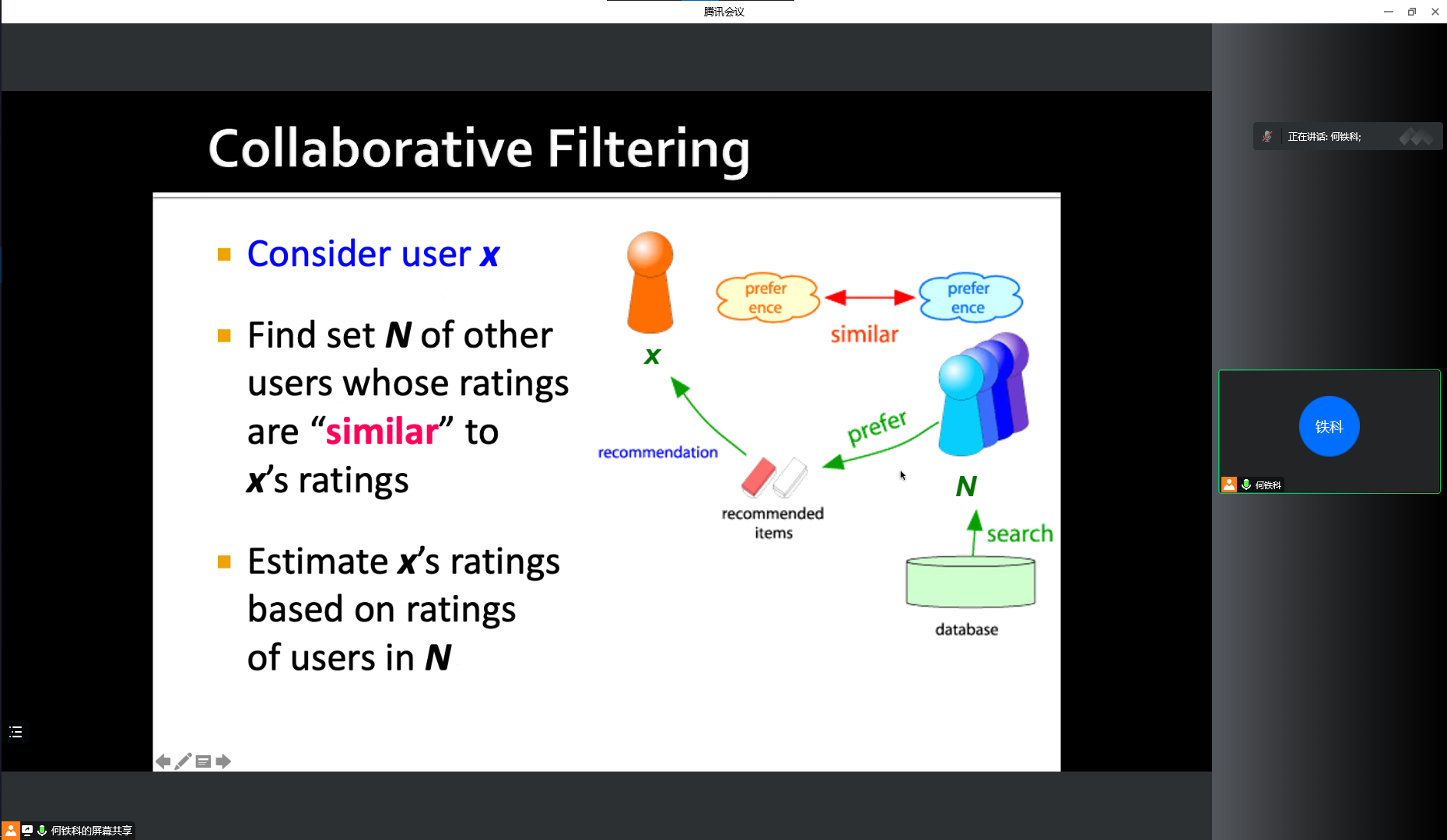
推荐系统
- 关键问题
- 获取已知评分
- 基于内容的模式优缺点
- 优点
- 不需要其他用户的数据
- 可以为特殊用户提供推荐
- 可以推荐新的和不流行的项目
- 可以提供项目解释
- 缺点
- 难以寻找恰当的特征
- 无法为新用户推荐
- 过度特化
- 优点
- 协同过滤优缺点
- 优点
- 适用于所有项目
- 缺点
- 需要足够的用户数据
- 用户数据稀疏
- 未被评分过的项目无法预估
- 无法为特殊用户或新的项目进行推荐
- 优点
- 混合方法
- 基于内容的模式优缺点
- Apache Hadoop & Apache Spark
- NoSQL
- graph stores
- document databases
- key-value stores
- wide-column stores
- Neo4j
- social computing and data mining
- 4 categories of centric communities:node group network hierarchy
- 完全相互性:集团
- geodesic distance
- Natural Language Processing
- features
- word segmentation
- optional matching
- based on understanding
- based on statistic
- unigram bigram trigram
- 词的编辑距离
- one-hot encoding
- bag of word
- topic model
- 词项-文档矩阵
- 共现矩阵
- 基于共现矩阵词向量
ID3 算法
选择信息增益最大的特征作为分类特征:

C4.5 算法

KNN 算法
硬聚类 VS 软聚类

K-Means 优缺点

cluster 的直径










知识图谱部分应该没有。
Spark