考点集中:
- 选择题 10 道,基本上是单选,共 30 分;
- 简答题,4 道,共 25 分;
- 计算题,测试用例优先级排序,有公式;
- 应用题,基本测试思想去写蜕变规则、测试用例;
- 设计模糊测试
源码测试
随机测试
大数定律:测试执行次数够多、测试数据随机生成 \(\to\) 概率低的偶然现象发生
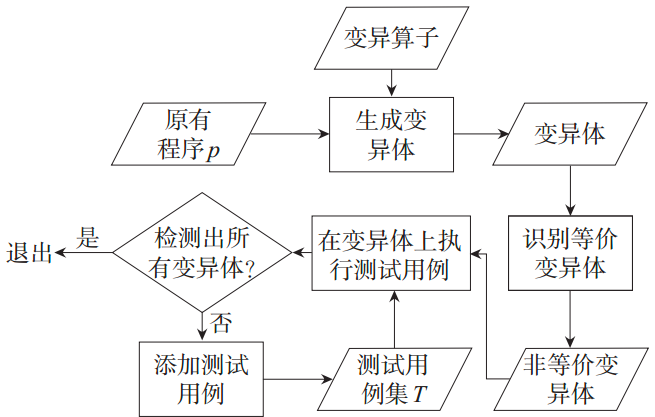
变异测试
变异测试旨在找出有效的测试用例,发现程序中真正的错误。
测试输入如何生成。

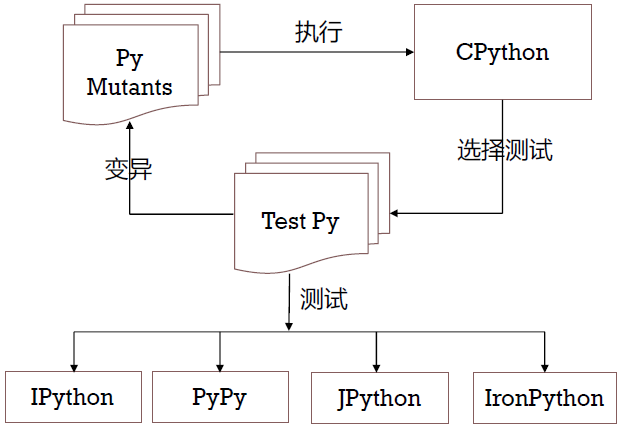
差分测试
基本思想:通过将同一测试用例运行到一系列相似功能的应用中观察执行差异来检测 bug。
同样的 python 源代码,使用不同解释器得到的结果应当是相似的。
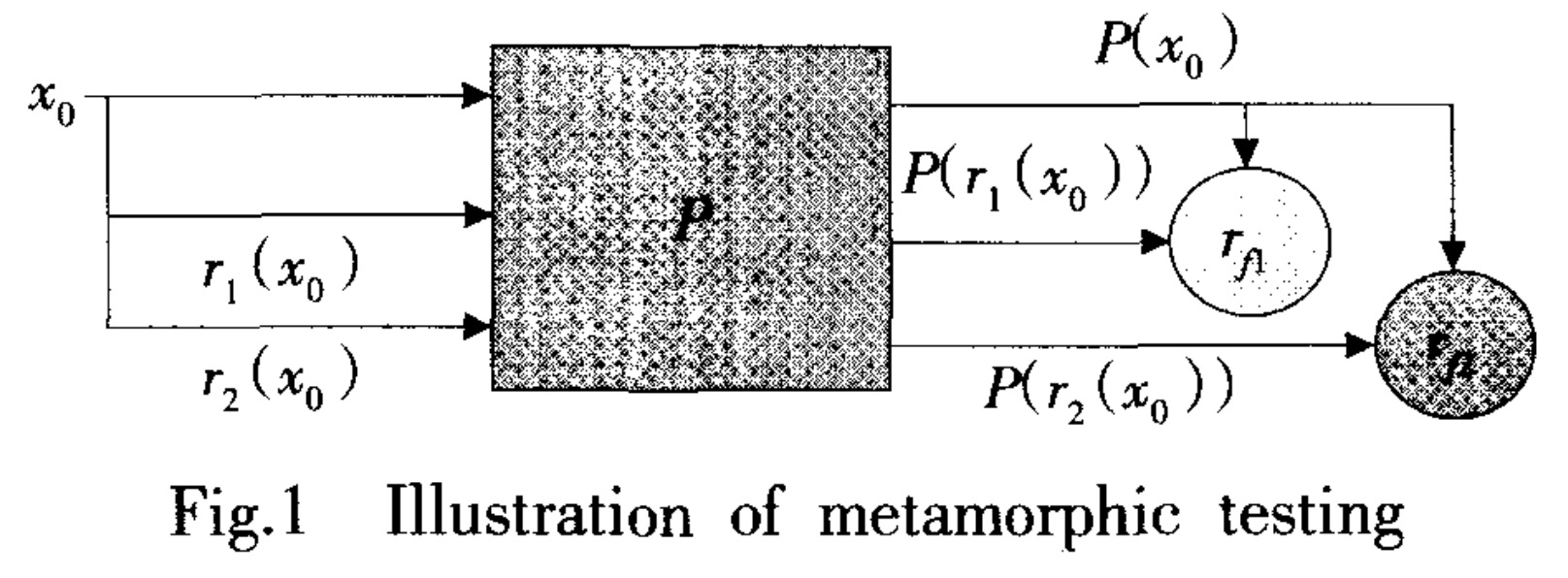
蜕变测试
蜕变关系(Metamorphic Relation,MR)是指多次执行目标程序时,输入与输出之间期望遵循的关系。
随机测试生成大量结果时,无法判断测试用例间的关系。
对 \(\sin\) 函数的额蜕变关系:
- MR1: \(\sin(x)=\sin(x+2\pi)\)
- MR2: \(\sin(x)=-\sin(x+\pi)\)
- MR3: \(\sin(x)=-\sin(-x)\)
- MR4: \(\sin(x)=\sin(\pi-x)\)
- MR5: \(\sin(x)=-\sin(2\pi-x)\)
- MR6: \(\sin2(x)+\sin2(\pi/2-x)=1\)
设计 MR 关系。
解决测试预言如何获取的问题。选择题在后面有答案。
测试用例优先级
主要算法的流程及复杂度
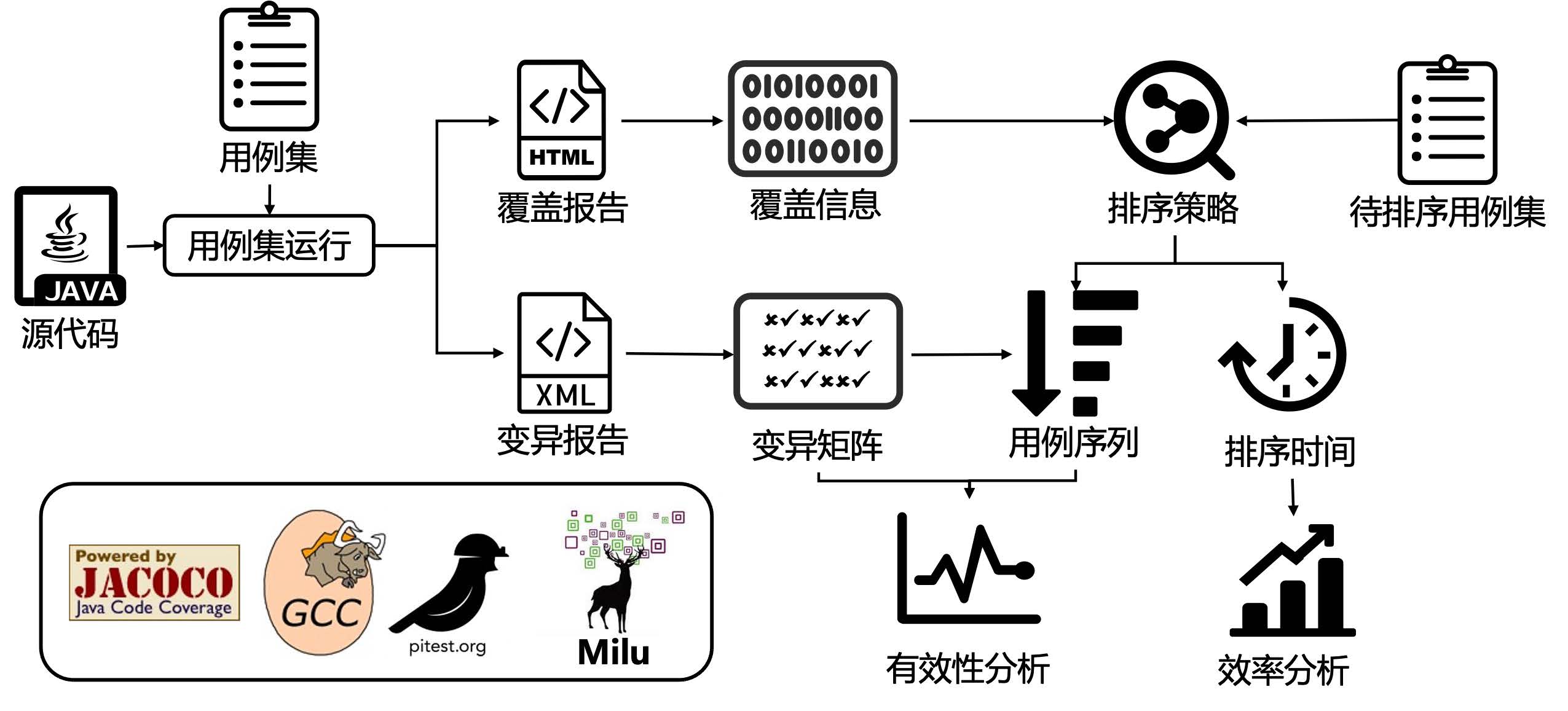
- 特征提取:选择合适的特征表示测试用例。
- 优先级策略:操纵测试用例的特征进行优先级排序。
- 评估准则:选择恰当指标评估优先级排序的效果。
基于贪心的 TCP
全局贪心策略:
- 每轮优先挑选覆盖最多代码单元的测试用例。
- 多个用例相同随机选择。
增量贪心策略:
- 每轮优先挑选覆盖最多,且未被已选择用例覆盖代码单元的测试用例。
- 所有代码单元均已被覆盖则重置优先级排序过程
- 多个用例相同随机选择
假设有 \(n\) 个测试用例以及 \(m\) 个代码单元,共需排序 \(n\) 轮,每轮选择一个测试用例。第 \(k\) 轮时,存在 \(n - k + 1\) 个待排序用例,每个用例需与 \(m\) 个代码单元计算情况,那么时间复杂度为 \(O(n^2m)\)
基于相似性的 TCP
自适应随机策略。
基本定义:每轮优先与已选择测试用例集差异性最大的测试用例。让测试用例均匀地分布在输入域中。
基于搜索的 TCP
基本定义:探索用例优先级排序组合的状态空间,以此找到检测错误更快的用例序列。
基于机器学习的 TCP
编译器场景中的测试用例优先级
基本定义:对测试用例特征进行学习,根据预测的缺陷检测概率进行优先级排序。
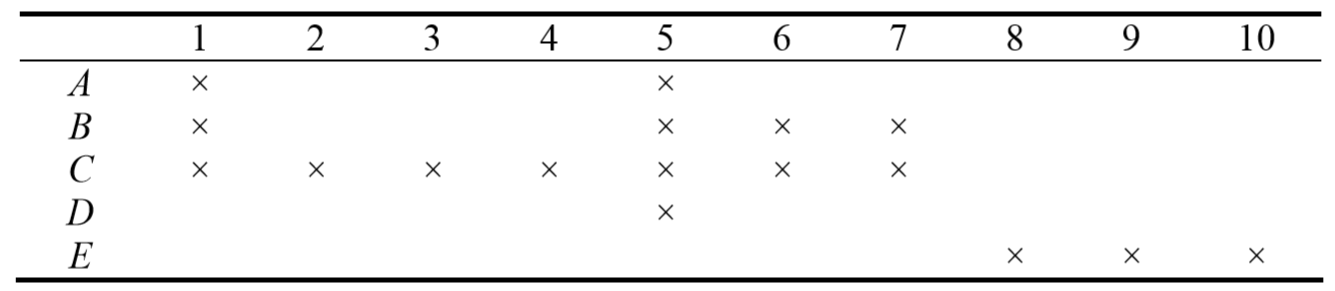
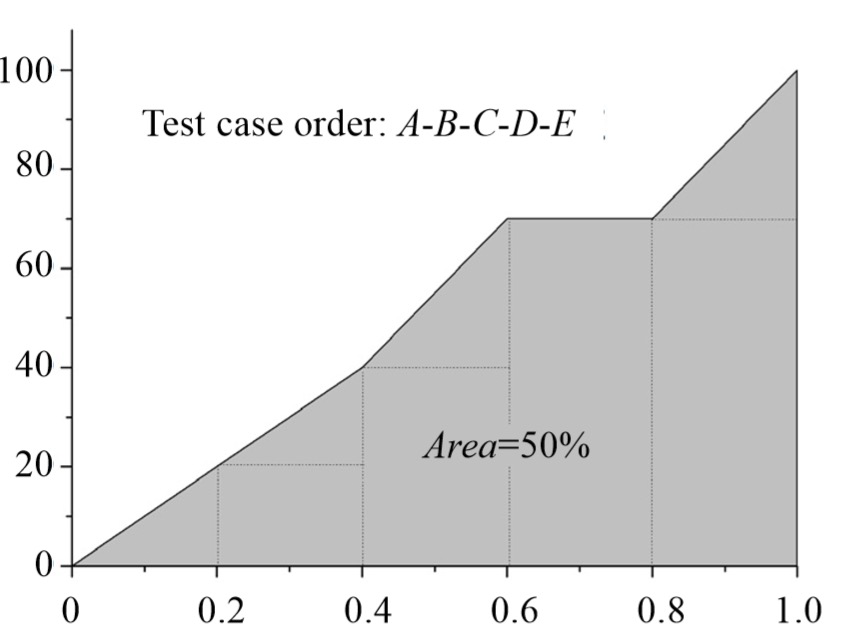
APFD 计算
指标:平均故障检测百分比(Average Percentage of Faults Detected, APFD)
说明:当给定测试用例的执行次序时,该评测指标可以给出测试用例执行过程中检测到缺陷的平均累计比例。
特点:其取值范围介于 0~100% 之间,取值越高,则缺陷检测速度越快。
一般性描述:给定程序包含 \(m\) 个故障 \(F = \{f_1, f_2, \dots, f_m \}\) 和 \(n\) 个测试用例 \(T = \{ t_1, t_2, \dots, t_n\}\) ,\(T'\) 为 \(T\) 的一个优先级序列,\(TF_i\) 为该测试用例序列 \(T'\) 中第一个检测到故障 \(f_i\) 的测试用例下标,则该优先级序列 \(T'\) 的 \(APFD\) 值计算公式为:
\[ APFD = 1 - \frac{\sum_{i=1}^{m}TF_i}{n \times m} + \frac{1}{2n} = 1 - \frac{1}{m}\sum_{i=1}^{m}\frac{TF_i-\frac{1}{2}}{n} \]
算法应用
测试用例选择
安全测试用例选择。
测试用例和待测程序的关系、依赖哪些类?
定义:旨在从已有测试用例集中选择出所有可检测代码修改的测试用例。
适用场景:适用于因测试预算不足以致不能执行完所有测试用例的测试场景。
回归测试用例选择(Regression Test Selection,RTS)最主要的目标包括:
- 降低回归测试的开销
- 最大化缺陷探测能力
主要方法
根据不同的选取策略,测试用例选择可大致分为以下四类:
- 最小化测试用例选择技术(Minimization Techniques)
- 安全测试用例选择技术(Safe Techniques)
- 基于数据流和覆盖的测试用例选择技术(DataFlow-Coverage-Based Techniques)
- 特制/随机测试用例选择技术(Ad-Hoc / Random Techniques)
安全测试用例选择技术
目标:针对某种特定的测试需求,选取出源测试套件 \(T\) 中所有能够暴露修改后被测程序 \(P'\) 中的一个或多个缺陷的所有测试用例,构成安全回归测试集 \(T_s\)
要求:一个安全测试用例选择技术要求在目标程序 \(P\) 运行回归测试时,\(T_s\) 中的每个测试都能够满足以下条件之一:
- 执行至少一条在 \(P'\) 中被删除的语句;
- 执行至少一条在 \(P'\) 中新增的语句
动态静态
静态分析:静态(程序)分析是指在没有实际执行程序的情况下对计算机软件程序进行自动化分析的技术(手动分析一般被称为程序理解或代码审查)。大多数情况下,分析的材料为源语言代码,少部分静态分析会针对目标语言代码进行(例如:分析 Java 的字节码)。
动态分析:动态(程序)分析通过在真实或虚拟处理器上执行程序来完成对程序行为的分析。为了使动态程序分析有效,必须使用足够的测试输入来执行目标程序,以尽可能覆盖程序所有的输出。进行动态分析时一般需要注意最小化插桩对目标程序的影响。
与测试用例优先级的区别和联系
移动应用测试
基于图像理解的移动应用自动化测试
回放、自动探索、自动深度遍历:
- 能够了解各个任务的难点
- 能够论述各个任务的解决方法
- 核心思想
- 方法步骤
背景介绍
GUI 测试脚本录制与回放:
- 基于坐标:录制内容为用户的动作和相应的点击坐标
- 基于控件树:主流方法,对 UI 控件树进行解析,以控件的唯一标识(如 xpath)对控件进行定位
- 基于图像:对比控件截图与屏幕截图从当前 UI 中定位控件
移动平台的碎片化问题:平台多样、操作系统版本、品牌、型号、屏幕尺寸分辨率……
GUI 测试脚本录制与回放:大多数移动应用在不同平台上设计的 UI 布局结构极为相似,因此可以利用这种相似性进行移动应用的 GUI 测试脚本录制与回放
基于群智协同的众包测试
众包的过程、报告的问题(重复、错误),发包方的审查序列,典型案例。
看图说话,简答题选择题。
- 能够了解众包的难点
- 能够了解基本的机制
- 能够了解解决方法
众包测试流程
- 申请上传:用户将自己的应用程序上传到众测平台,并指定相应的测试任务和酬劳信息。
- 任务选择和环境设置:众测人员自由选择他们想要完成的任务。选择后测试人员从平台上下载应用程序进行测试。
- 提交报告:众测人员根据选择的待测应用,对测试到的缺陷提交缺陷报告。
- 生成最终测试报告:平台收集补充信息,生成最终的缺陷报告,包括:一般信息、设备信息、操作路径等。
- 报告验证:客户将验证所有最终的缺陷报告,并决定如何酬劳每个提交报告的众包测试人员。
困难和解决
大量的测试报告——较多的重复数据:
- 懒惰和缺乏经验的用户。
- 测试报告搜索功能较差。
- 偶然的重复——由于网络等原因不小心提交了多次。
- 给开发者增加了许多工作量。
- 不同的信息可以使开发者对 Bug 有一个更全面的了解。
解决方案:
- Aggregator:对所有的测试报告做聚类,将相同的或相似的测试报告聚为同类。
- Summarizer:对每一类测试报告做整合,将其中的相关信息以可视化的方式最大化的呈现给开发者。
AI 测试
AI 测试概述
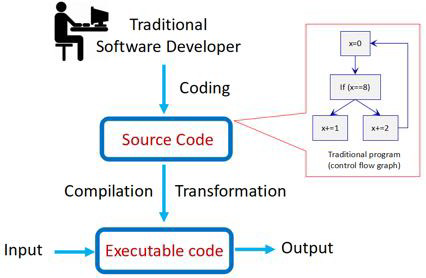
传统软件:测试流控制流,各种逻辑控制
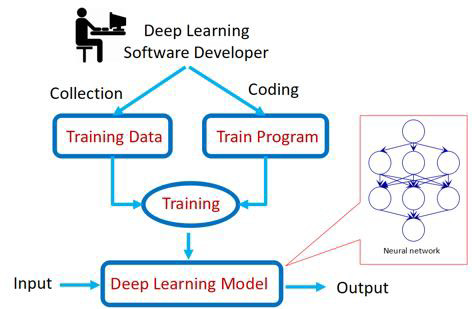
AI 系统:所有神经元都会被覆盖到,数据驱动
- 与传统测试的区别
- 测试的难点
与传统测试的区别
决策逻辑的差异:
- 传统软件的决策逻辑:程序代码控制决策逻辑
- 智能软件的决策逻辑:深度学习模型的结构、训练后得到的权重节点
程序特征的差异:
- 传统软件系统程序特征:控制流和数据流构建的业务处理
- 智能软件系统程序特征:数据驱动构建的参数化数值计算
不同基础编程范例:
- 传统软件的决策逻辑:代码形式
- 深度学习系统的决策逻辑:DNN 的结构、在数据上训练的连接权重
 |
 |
|---|
测试难点
- 数据量不够
- 低质量数据
- 数据分布不均
- 不充分测试
模糊测试
基本流程
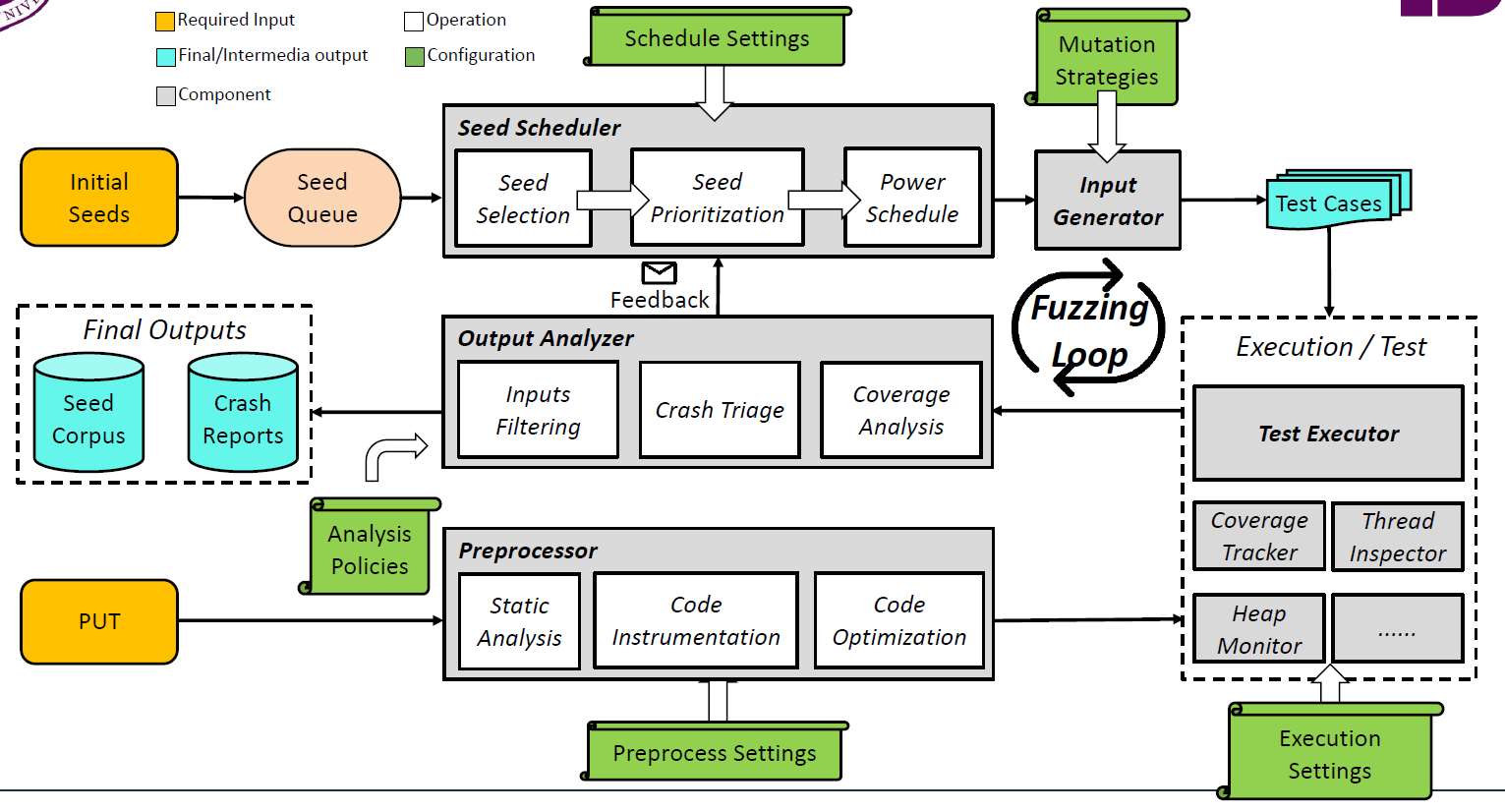
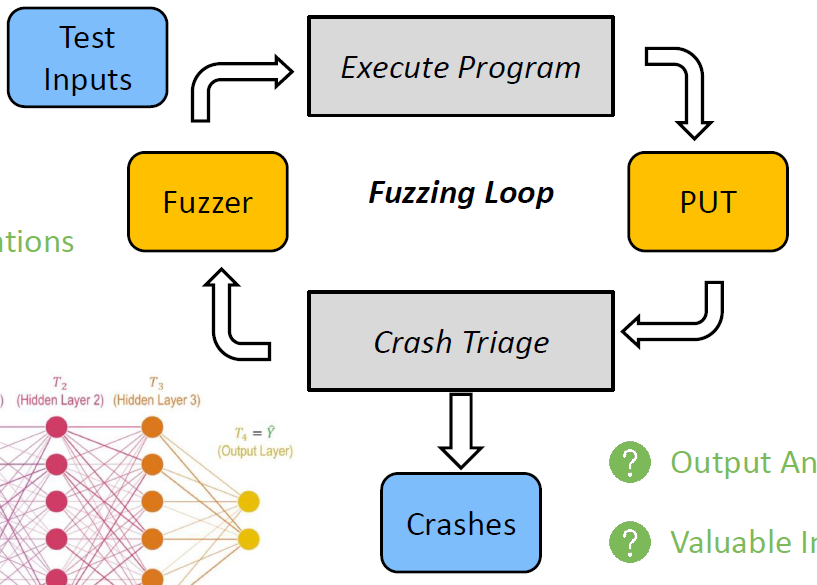
数据生成
数据扩增:通过轻微变换现有数据或创建新的合成图像来得到新数据的技术。应用领域有图像扩增、文本扩增、雷达扩增……

数据扩增原因:
- 领域数据稀缺
- 数据分布挑战
- 数据标注困难
- 隐藏信息干扰
结果反馈
简单应用
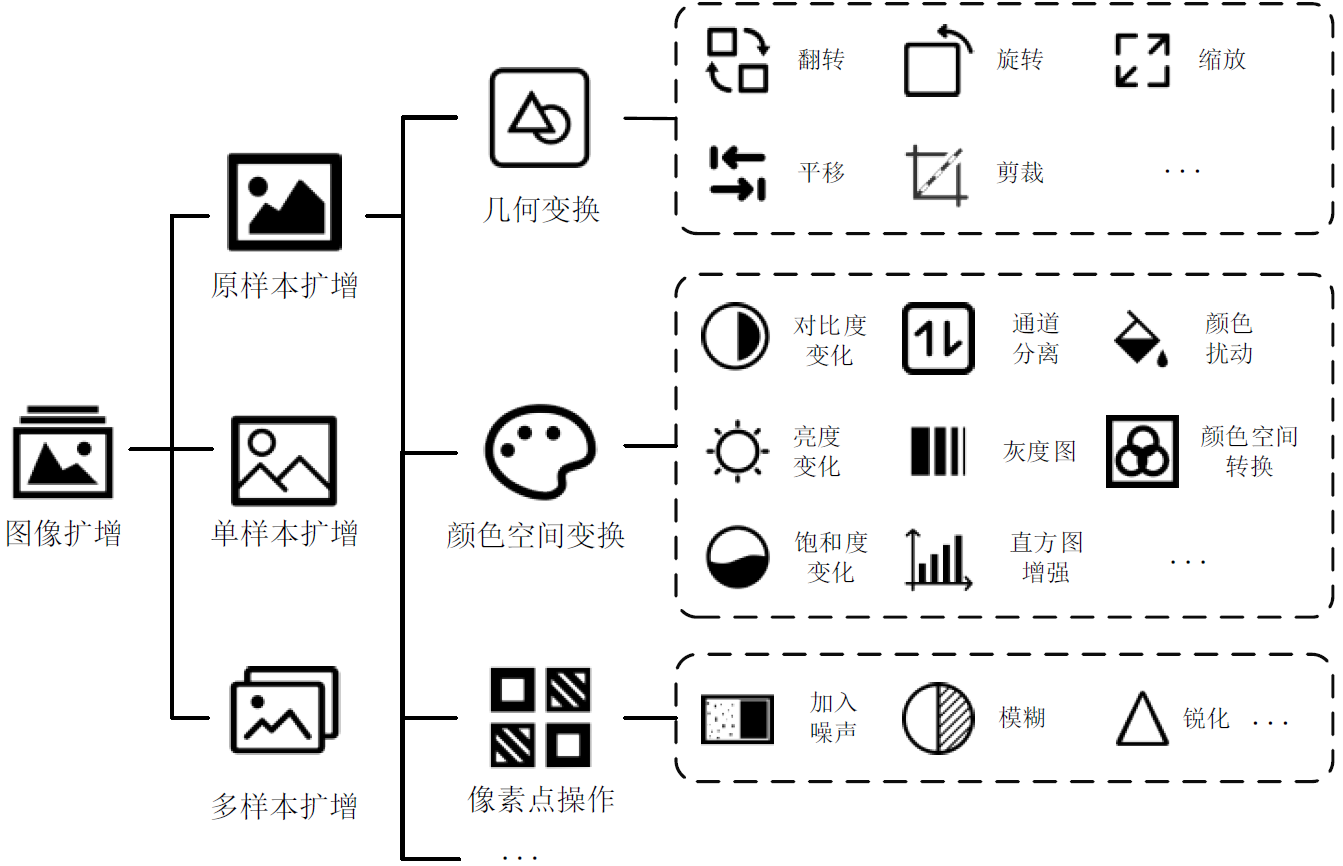
图像扩增
PS,翻转、旋转、缩放、裁剪、平移、高斯噪声、生成对抗网络 GAN、基于语义的(医疗上病灶抹除、生成病灶)。扩增出的图片要有标签。
基本原则
- 扩增后的标签保持不变/相应修改标签
- 扩增需要基于先验知识。针对不同任务和场景,数据扩增的策略不同。
- 不引入无关的数据
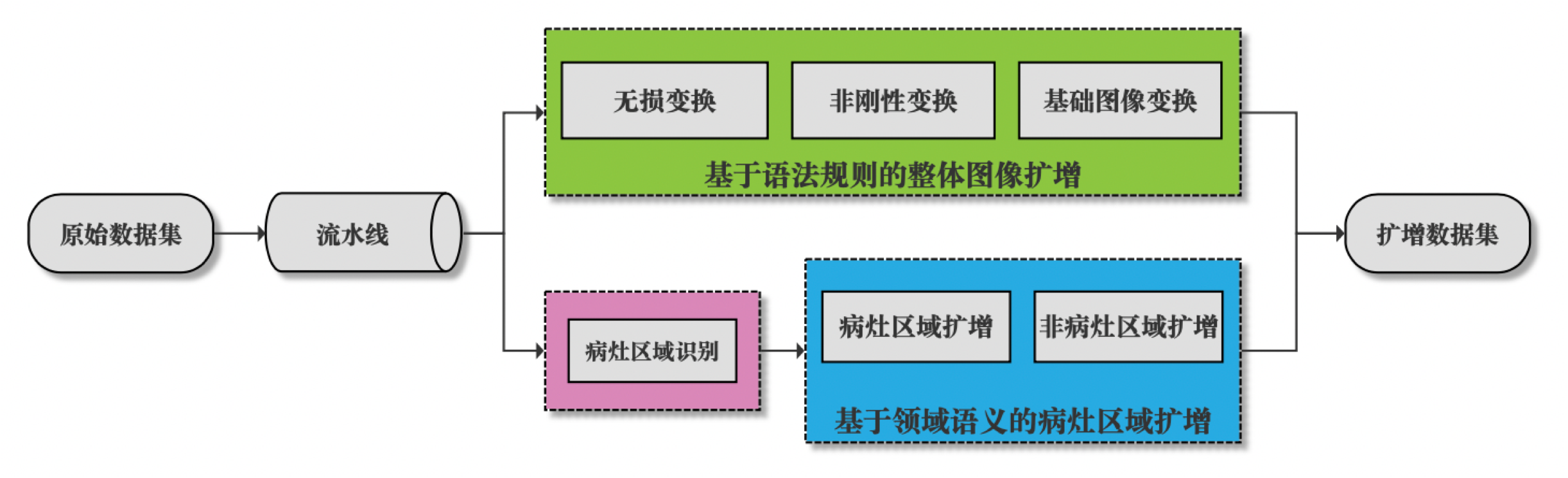
图像扩增方法
医疗图像扩增
- 患者隐私保护,医学影像匮乏;
- 共享临床数据困难;
- 影像质量参差不齐;
- 需要专家手动贴标签。
公平性
如果数据有偏差、有失公平。如:
- 软院的性别比例;
- 司法判定系统的法条推荐,和特殊地域人种有关。



后门攻击

 |
 |
|---|

