编译预处理
- 与作用域、类型、接口等概念格格不入
- 潜伏于坏境:编译预处理,可以不写在程序中
- 穿透作用域:在编译预处理的时候,忽略作用域。
1 | |
- 设想:
- 置换
- 应用方式丰富,很难为其的找到具有更好的结构且高效的替代品
- 关于对于
#include、#define、#ifdef、#pragma的不同处理
#include
- include 会打开文件内容,然后将文件内容拷贝过来
- 保证接口的定义在本文件中有效
- 暴露源文本
#define
符号常量
#define pi 3.14
const pi = 3.14
不需要分号,因为他是编译预处理而不是代码
开放子过程
使用 inline 函数
过程函数泛型
#define max(a,b) (a) > (b) ? (a) : (b)这个 max 宏和函数有什么区别
- 为什么没有括号不行?因为他不懂乘法:
#define mul(a,b) a * b - 如果使用:
max(1+2,2+3)//1 + 2 * 2 + 3 - 宏还可能带来重复计算(只是一个编译预处理)
double int 等对函数重载
宏是定义和所有的同类型比较的泛型。
宏的严重缺陷:宏没有函数的类型检查
将 int 写成参数 T(类型参数):T max(T,T)
Generic types
- 使用模板来替代大量重复的部分
重命名 vaou
- namespace 的形式
字符串连接
不可以被替代
1 | |
这个是为了帮助框架的实现
特殊目的用法
不可以被替代
1 | |
1 | |
有些程序的部分是保障机制,在不同形式下的保障是不同的
使用开关量的编译选择,用来在发布的时候对于不应该被发布的东西进行开关量的调整(就可以不用删除)
有一些调试是不能通过断点调试的,所以我们就可以打开开关变量,用来记录更加清晰深刻的日志。
General macro processing
- 不可以被替代
- 我们可以将一些 warning 确认没有问题忽略掉
- 我们也可以通过将一些 warning 提高为 error 的高级别,这样子就可以更加清晰的发现问题(IDE 集成)
1 | |
#ifdef
- 版本控制
- 注释代码
#pragma
- 层间控制
- 告知编译器
#pragma pack()- 在计算机内存空间中,我们往往是要进行数据的对齐,这样子可以提高内存数据的读取效率
- 我们可以通过传递预编译指令用来对于指定数据的对齐
- #pragma pack()法详解
程序组织
- 逻辑结构:相关联的函数/文件形成的抽象上的图结构
- 物理结构:考虑到每个函数 f 存储的位置,不一定存在同一个 cpp
- 一个源程序不论有多少个源文件,只有一个源文件能包含 main 函数
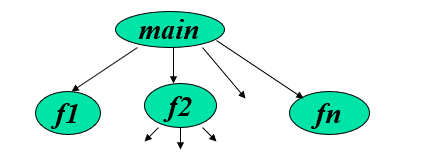
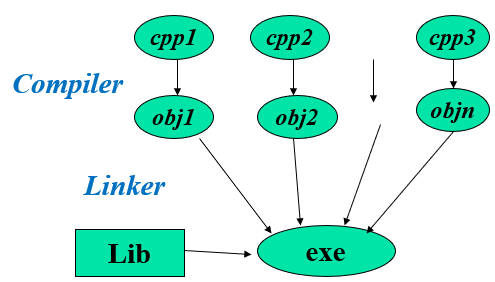
- 工程文件
- 外部函数
- 外部变量
- 组织是物理层面
- 我们直接将一些头文件
.h中写好函数原型
头文件和 cpp 文件
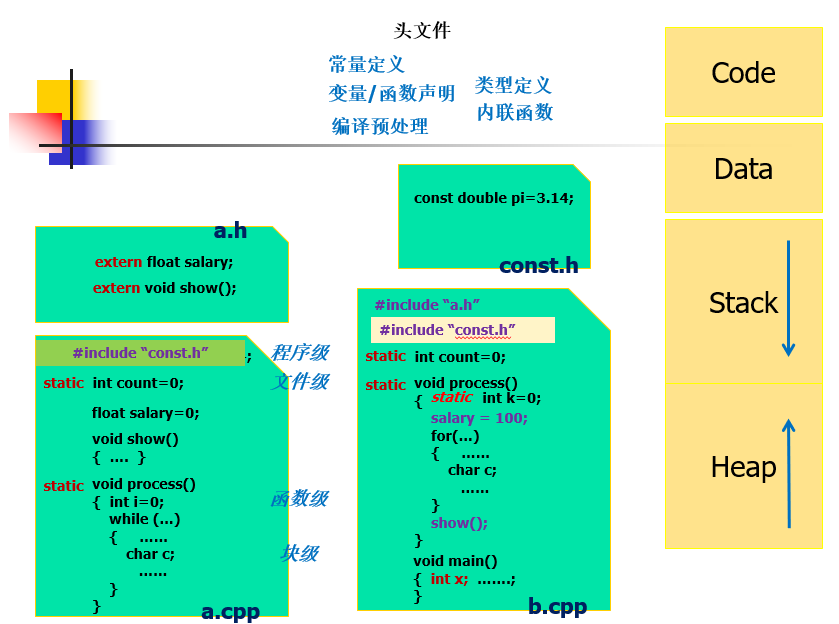
- 我们要始终注意 scope 和 lifetime
- 作用域
- 程序级作用域(函数外定义的变量):一个程序可能有很多源文件,程序级就是说整个程序可见
- 函数级作用域:在 Stack 中,同一个函数内可见
- 块级作用域:在 Stack 中,同一个代码块内可见,比如 while 循环中定义的一个变量
- 文件级作用域:在 A 和 B 中的 process()不同函数的,同一个文件中可见
- 协同:B 中使用 A 中的,需要标明 extern,然后在编译前确认查找
1 | |
- 将外部要用的,开发的,A 把对应的放到 a.h 头文件中,而 B 就不需要进行读取 A 文件内容,B 在使用时在文件头
#include "a.h":功能就是直接复制粘贴过来,是 preprocess 命令 - 如果有些服务不想要提供:将作用域限制到文件内:就是文件级作用域
- 常量作用域默认是文件作用域,我们也将其抽象成为
const.h文件来查看管理 - main 是全生命周期的,活在栈中。
extern 的另一个用法
- extern 可以用来修饰变量或函数,用来说明此变量/函数是在别处定义的,要在此处引用,而不会新开辟一块内存。
- 该变量或函数必须是唯一的,如果多个 cpp 文件中都有定义则会报错
- 一般不用 extern 修饰常量,因为常量默认作用域是文件
- 函数默认的生命是 extern 的,带有关键字仅仅是语义上这个函数可能在其他源文件里有定义。
头文件的内容
- 放置不占空间的部分
- 放置常量定义
- 放置变量/函数声明(为什么可以这么干?)
- a.cpp 和 a.h 并没有联系,link 时会从所有编译好的文件中找 B 需要的符号,如果几个不同文件中实现了同一个函数/定义了同一个全局变量,就会报错
- 编译阶段,B 虽然找不到该函数或变量(理解为符号表的信息不完整),但连接时会从 A 生成的目标代码中找到此函数
- 放置宏
- 放置类型定义
- 放置内联函数(必须写到头文件)
- 为什么内联函数要放置到头文件中?因为不这么做,无法正常使用
- inline 是基于源代码的复用,根据原型是不行的
- 如果头文件中有 inline,但是被拒绝了?如果头文件中的 inline 函数很复杂(loop 等),那么我们会将对应代码替换进去的时候,生成了多份的 static(局部于文件作用域)
- 相对的话:如果不是 inline 函数,那么函数只会有一份。
1 | |
- 头文件可以再次放置头文件

