函数
- 一个函数就是一个功能
- 函数包括
- 系统函数(库函数)
- 用户自己定义的函数
- 无参函数
- 有参函数
函数的原则
- 函数不可以被嵌套定义:函数内部不可以再次定义新的函数
- 函数可以通过原型完成有默认参数的函数
- 函数是先定义后使用,具体是指上下文环境
Runtime Environment在我们 C++中是使用Stack
函数模板
template <typename T>T max(T a, T b, T c){}- 在运行时确定 T 的类型
函数编译链接
- 编译时只编译当前模块
1 | |
- 编译每个编译单元(
.cpp)是相互独立的,即每个 cpp 文件之间是不知道对方的存在的,.cpp编译成.obj后,link 期时a.obj才会从b.obj中获得f()函数的信息(这就是为什么要预处理) - link 时将编译的结果连接成可执行代码,主要是确定各部分的地址,将编译结果中的地址符号全换成实地址(call 指令在 a.cpp 被编译时只是 call f 的符号,而不知道 f 确切的地址)
重载与重写
- overload:语言的多态
- override:父子类的,OO 语言独有多态
- 多态不是程序语言独有的,而是语言拥有的特性。
- C++支持重载,C 不支持重载。
函数的重载(Overload)
- 原则:
- 名称相同,参数不同(重载函数的参数个数、参数类型、参数顺序至少一个不同)
- 返回值类型不作为区别重载函数的依据
- 匹配原则:
- 严格匹配
- 内部转换
- 用户定义的转换
- 以下为几个例子
1 | |
函数的默认参数(是对函数重载的补充)
- 默认参数的声明:默认参数是严格从右至左的顺序使用的
- 在函数原型中给出
- 先定义的函数中给出
- 默认参数的顺序:
- 右->左
- 不间断
- 默认参数与函数重载要注意
void f(int); void f(int, int=2);
- 在定义中一般不给出默认参数(给出了也不会 CE),在调用的时候使用函数原型的时候给出默认参数。
- 函数默认重载,在面向对象编程中,子类即便修改默认参数,也不生效(即,以父类为准)。
1 | |
外部函数 extern
- 符号表:Name mangling: extern "C"
- 在 C++的 g 中调用 C 中的 f,会在 link 的时候出问题(因为不在 C++ 的符号表中)
- 解决方案:在函数名前面加上 extern 的关键词(这样子编译器就会在编译过程中从外部进行寻找)
- C 编译器编译的文件被放置在 lib 库中,C++不能直接调用,而是需要 extern 才可以
- 原因:符号表机制
1 | |
符号表机制
- 符号表:与编译的各个阶段都有交互,存有函数名、地址等信息;编译时会创建一个函数符号表
<name,address>,对应的符号后面的地址还没确定(link 期决定),call name 根据 name 找到符号表对应的地址,再执行 - 对于 c 语言来说,编译得到的符号表内函数 f 在符号表里的 name 就是 f(不存在函数重载)
- 对于 c++来说,因为有重载,所以 f(int) f(float) 符号表里的 name 是不同的
- c++对于 c 语言的函数 f 会按 c++的方式生成函数表中的 nameA,但 c 编译好的函数表内 f 对应的 nameB 和 nameA 不一致,导致 c++无法找到该函数
函数与内存
- 在内存中的 code,是不可以断章取义的。
- 需要按照类型来进行
- 函数是使用临时性存储空间,
存储空间与内存
- 从上往下分别是
- code:每个指令都有对应的单元地址。函数的代码存放的位置是受到限制的
- data:存放数据(全局变量、静态局部变量)
- Stack:由系统管理,存放函数
- Heap:可以用程序员进行分配,可以在运行时动态确定,
int p = (int )malloc(4),归还内存free(在 C++中不推荐使用这种方法进行处理,而是使用 new 和 delete)
- compiler 组织成符号表。CPP 是一个文件一个文件进行编译的。
- 在编译 A 文件的时候,是不知道 B 文件存在的,也就是说每一个文件都是单独编译的。
- 借助符号表来获取存储地址,问题? 函数名相同,重载(多态)的问题,解决:不仅仅按照函数名,还要按照函数参数来划分。
- 所以函数表,不仅仅存储函数名,还存储函数的参数返回值类型。
- 问题:可以在不降低可读性的前提下,降低 COST 吗?
- 运行逻辑是由 Runtime Environment 是有差异的:注意合作方的运行环境(使用 Lib 的注意)
RunTime Environment
- 每一个函数都有栈空间,被称为 frame(active frame 是当前运行函数的栈空间)
- 以下类似是一种契约,这种约定被 compiler 和 linker 共同管理
_cdecl
函数空间(参数)归调用者管理,本章讲解的是这种,调用者清空栈。
问题:函数调用结束后,原空间的参数仍然在(未归还)
好处:由调用者管理所有的调用参数,可以灵活管理参数
- 例子:
printf()函数是可变参数,根据字符串形式决定(由调用者控制):int printf(const char format,...)。这种情况只能由调用者归还。
坏处:安全问题,调用者环境被破坏。
- 无法控制传递参数的个数,写了 8 个
%d,但是只传递了 1 个,则会导致调用者环境被破坏。 - 同样的问题,就算环境不被破坏,也会导致软件内部不应该被看到的数据被拿出来
_stdcal
函数调用后,函数空间由被调用者管理,被调用者清空栈。调用者来传递参数(申请空间),由被调用者归还参数(归还空间),这部分空间被称为中间地带。
好处:空间节省,跨平台性:比如 C++ 调用 C 的时候(C 不允许重载)
坏处:对于可变参数的函数无法计算 %ebp 的参数个数,但是对于调用者是知道的,这样只能使用_cdecl
_fastcall
第 1 个参数放入 %ecx,第 2 个参数放入 %edx,其余参数放入栈中。
函数执行机制
建立被调用函数的栈空间
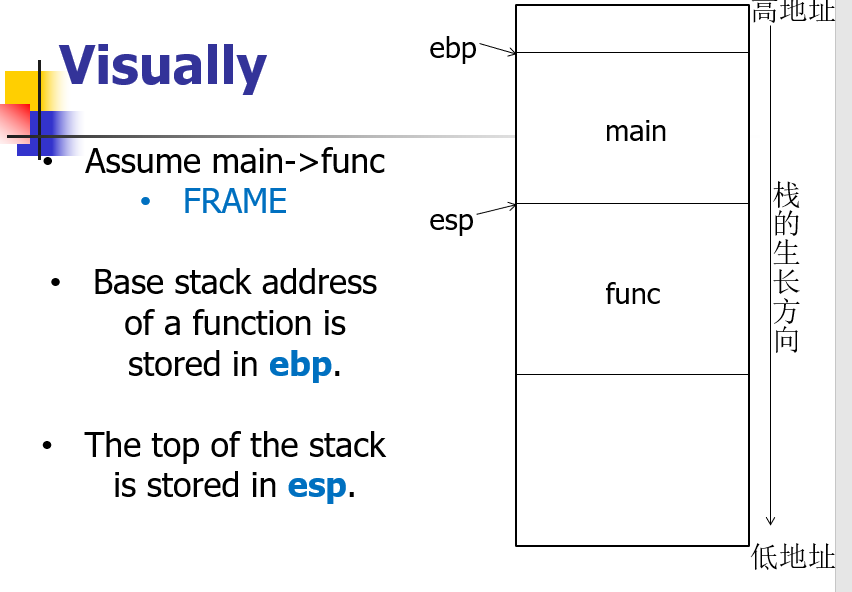
- 栈空间是从高地址向低地址生长
- 栈底:ebp(当前函数的存取指针,即存储或者读取数时的指针基地址)
- 栈顶:esp(当前函数的栈顶指针)
- 保存:返回地址、调用者的基指针
- 过程描述:调用一个函数时,先将堆栈原先的基址(ebp)栈,以保存之前任务的信息。然后将栈顶指针的值赋给 ebp,将之前的栈顶作为新的基址(栈底),然后在这个基址上开辟相应的空间用作被调用函数的堆栈。函数返回后,从 ebp 中可取出之前的 esp 值,使栈顶恢复函数调用前的位置;再从恢复后的栈顶可弹出之前的 EBP 值,因为这个值在函数调用前一步被压入堆栈。这样,EBP 和 ESP 就都恢复了调用前的位置,堆栈恢复函数调用前的状态。
参数传递
值传递

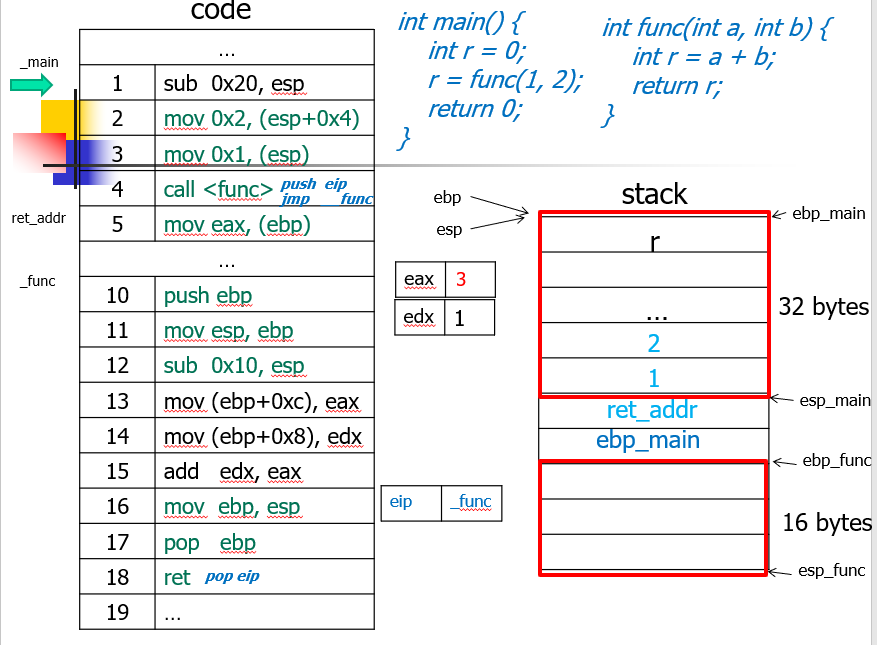
- 最上面是 main 函数,左侧,下面是 Function.
- 为什么 ebp 和 esp 之间距离很大,因为我们要对齐,提高内存管理效率。
- 数据类型决定存放数据的空间的大小
- 函数调用过程:
- 开始调用 esp 从栈顶向下移动 32 位,存 ret_addr,开辟 main 函数的栈空间
- 然后 esp 继续向下存 ebp_main
- 然后 ebp 到 esp 处
- 然后 esp 到新的函数空间的栈顶
- 函数处理
- esp 先返回到 ebp
- 然后 ebp 根据 ebp_main 返回,然后 esp 加一(向上)
- 之后 esp 回到 ret_addr 位置即可。
- 动画过程看 PPT 50 页
- eip 存放了 ret_addr
引用传递:函数副作用
- 传递的是地址,会同时修改对应地址单元中的值。

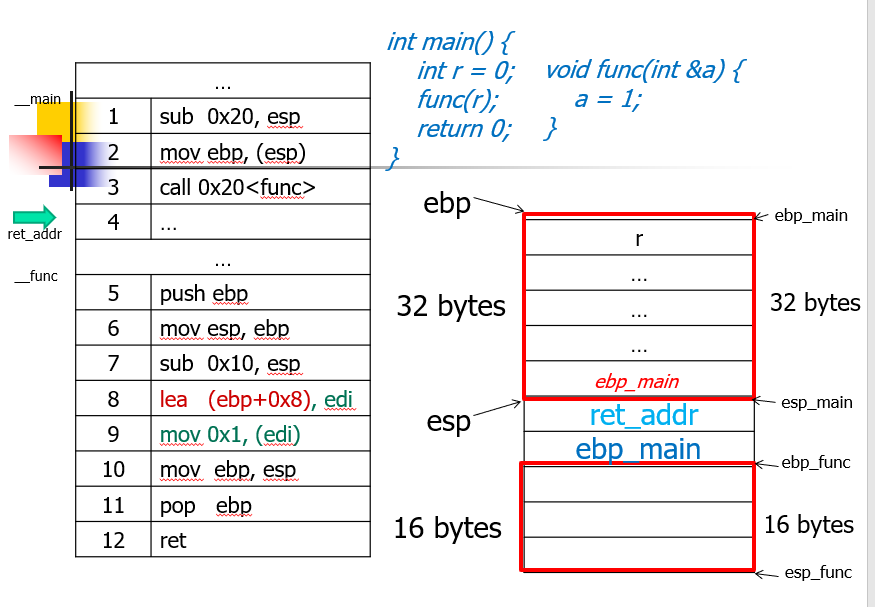
call by name
- call by name 是指在用到该参数的时候才会计算参数表达式的值。
1 | |
call value-result: copy-restore
1 | |
保存调用函数的运行状态(额外的 Cost)
- 存储新的基指针:如上面,将 ret_addr 和 main_esp 进行存储。
- 分配函数存储的空间
- 执行某些功能
- 释放不必要的存储空间
将控制转交给被调函数
- 加载调用者的基指针
- 记载返回地址
Summary
- 加载参数(进栈)
- 保存上下文环境
- 保存返回地址
- 保存调用者基指针
- 执行函数
- 设置新的基指针
- 分配空间(可选)
- 执行一些任务
- 释放空间(如果分配了的话)
- 恢复上下文环境
- 加载调用者基指针
- 加载返回指针
- 继续执行调用者的功能
思考
如果所有数据都放置在内存中的数据区: - 好处:方便管理 - 坏处:占用空间大,没有利用程序的局部性。
函数原型
- 遵守先定义后使用原则
- 自由安排函数定义位置
- 语句:只需参数类型,无需参数名称
- 编译器检查
- 函数原型:只需要看到函数名和参数读取到即可:
int func(int,int)- 在调用点一定要能看到接口
- 仅仅需要函数名和参数类型即可
- 函数原型应当放置在头文件中
内外部函数划分使用
内部函数
- static 修饰
外部函数
- 默认状态的 extern
内联函数 inline
- 目的:
- 提高可读性
- 提高效率
- 解决了两个 cost 的问题
- 对象:使用频率高、简单、小段代码
- 实现方法:编译系统将为 inline 函数创建一段代码,在每次调用时,用相应的代码替换
- 限制:
- 必须是非递归函数,因为已经加入主体部分了
- 由编译系统控制,和编译器是完全相关的
- inline 关键字仅仅是请求
- 有可能是递归,无法加入
- 也有可能是很复杂的函数,导致无法理解(上下文比较复杂)
- 提请 inline 但是被拒绝可能是有代价的
- 如果对象的初始化-构造函数为明确给出,计算机会给出 inline 的构造函数
- 宏:
max(a,b) (a) > (b) ? (a) : (b):不同于 inline 函数,一定要有括号,因为运算数据中的优先级不同
例子
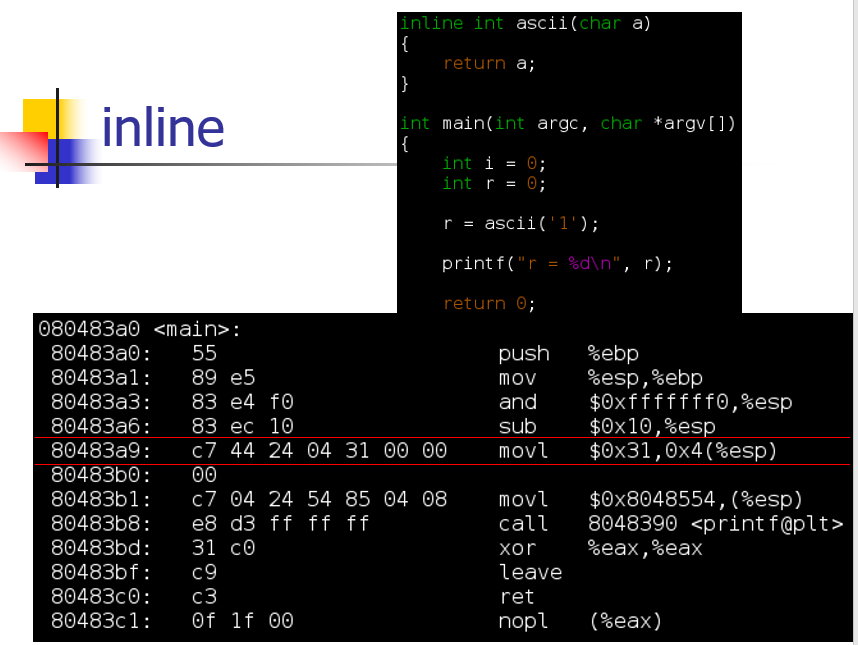
- 没有进行替换,只是将 ascii 函数体内操作直接进行替换。
- 内联必须和函数体放在一起,而不是和原型放在一起,并且函数体必须出现在调用之前,否则函数可以编译,但是不出现内联。
使用 inline 的优点和缺点
- 只有对编译系统的提示
- 过大、复杂、循环选择和函数体过大的会导致被拒绝
- 函数指针
- 编译器:静态函数
- 缺点:
- 增大目标代码
- 病态的换页:如果有过长的代码,被替换进入代码的段中,代码页在内存和磁盘中反复换页抖动(每调用一次内联函数就会将那段代码复制到主文件中,内存增加,内存调用时原本一页的内容可能出现在第一页+第二页的一部分,造成操作系统的“抖动”)
- 降低指令快取装置的命中率(instruction cache hit rate)
问题
- 是所有的编译器都能做到 inline 吗?不是都能做到
- 如果我向编译器要求 inline,是否一定能做到吗?如果做不到按照正常函数进行处理
- 函数放在头文件中被多次包含的重定义问题
ROP
- 在返回地址的时候,攻击我们的程序,调整 Bad_addr 导致调用到坏的代码(将错误的代码注入 stack 中去,在传入参数的过程中传入错误的代码)
- 防止这种攻击:禁止在执行过程中写入 stack
- 新的攻击方式:修改 return 前面的短序列(rop 链攻击)
- 使用正确代码的错误组合进行攻击
- 如果太长,需要依赖寄存器,导致攻击困难
- 防止这种攻击:禁止读系统中的代码
- 因为这种攻击需要先读出来所有的操作,然后进行组合,如果不能读出也就没有了
什么是 ROP
- 所谓 ROP:就是面向返回语句的编程方式,它就用 libc 代码段里面的多个 retq 前的一段指令的一段指令拼凑出一段有效的逻辑,从而达到攻击目的。
- 什么是 retq:retq 指定决定程序返回值在哪里执行,由栈上的内容决定,这是攻击者很容易控制的地址。
- 控制参数:在 retq 前面执行的 pop reg 指令,将栈上的内容弹到指令的寄存器上,以达到预期。(重复上述操作指导达成目的)
- 我们利用 glibc 进行逆向工程来查看返回前的 pop 指令
参考
函数副作用
函数副作用可以实现 call by reference,参考 scanf,而并不是通过 return 多参数而实现。

