本文主要内容来自 SpriCoder 的博客,更换了更清晰的图片并根据新的课程设计做了补充和修正。
- 边看边说复习
- 四个评估范型
- 快速评估
- 可用性测试
- 实地研究
- 启发式评估
DECIDE 评估框架
六个步骤:
- 确定评估需要完成的总体目标(Determine)
- 发掘需要回答的具体问题(Explorer)
- 选择用于回答具体问题的评估范型和技术(Choose)
- 标识必须解决的实际问题,如测试用户的选择(ldentity)
- 决定如何处理有关道德的问题(Decide)
- 评估解释并表示数据(Evaluate)
确定目标
评估目标决定了评估过程,影响评估范型的选择
为什么要评估?
- 产品设计是否理解了用户需要?
- 为概念设计选择最佳隐喻?
- 界面是否满足一致性需要?
- 探讨新产品应做的改进?
举例:
- 设计界面时,需量化评价界面质量:适合进行可用性测试
- 为儿童设计新产品时,要使产品吸引人:适合采用实地研究技术,观察儿童交谈
发掘问题
根据目标确定问题
- 目标:找出为什么客户愿意通过柜台购买纸质机票,而非通过互联网购买电子机票
- 问题:
- 用户对新票据的态度如何:是否担心电子机票不能登机
- 用户是否能够通过互联网订票
- 是否担心交易的安全性
- 订票系统的界面是否友好:是否便于完成购票过程
问题可逐层分解
选择评估范型和技术
范型决定了技术类型。
必须权衡实际问题和道德问题:
- 最适合的技术可能成本过高
- 或所需时间过长
- 或不具备必要设备和技能
可结合使用多种技术:
- 不同技术有助于了解设计的不同方面
- 不同类型数据可从不同角度看待问题
- 组合有助于全面了解设计的情况
明确实际问题
用户:
- 应选择恰当的用户参与评
- 能代表产品的目标用户群体
- 可以先做测试,确定用户技能所属的用户群
- 任务时间多长:20 分钟休息一次
- 可在任务执行前,安排用户熟悉系统
设施及设备:如需多少台摄像机录像,具体摆放在何位置
期限及预算是否允许
是否需要专门技能:没有可用性专家
处理道德问题
应保护个人隐私:
- 除非获得批准,否则书面报告不应提及个人姓名,或把姓名与搜集到的数据相联系
- 受保护的个人资料包括健康状况、雇佣情况、教育、居所和财务状况等
- 可在评估前签署一份协议书(IRB)
指导原则:
- 说明研究的目的及要求参与者做的工作
- 明保密事项,对用户&对项目
- 测试对象是软件,而非个人
- 对测试过程的特殊要求,是否边做边说等
- 用户可自由表达对产品的意见
- 说明是否对过程进行录像:不能拍摄用户的面部
- 欢迎用户提问
- 用户有随时终止测试的权利
- 对用户话语的使用应征得同意,并选择匿名方式
评估、解释并表示数据
- 搜集什么类型的数据,如何分析,如何表示:通常由评估技术决定
- 可靠性:
- 给定相同时间,不同时间应用同一技术能否得到相同结果
- 非正式访谈的可靠性较低
- 有效性:能否得到想要的测量数据
- 偏见:评估人员可能有选择地搜集自己认为重要的数据
- 范围:研究发现是否具有普遍性
- 环境影响:霍桑效应
- 很多的用户如何处理?
- 有一个问卷,用户给系统打分,5 分制,一般认为中间值是?
小规模试验
对评估计划进行小范围测试:
- 以确保评估计划的可行性
- 如检查设备及使用说明
- 练习访谈技巧
- 检查问卷中的问题是否明确
小规模试验可进行多次:
- 类似迭代设计
- 测试——反馈——修改——再测试
- 快速、成本低
可用性问题分级
评估结果总是可用性问题清单,以及改进建议
- 方法一:基于量化数据的分级,如多少人遇到该问题,耗费多少时间等
- 方法二:问题严重性的主观打分,取平均值
- 0:不是一个可用性问题
- 1:一个表面的可用性问题:如果项目时间不允许,可不予纠正
- 2:轻微的可用性问题:优先级较低
- 3:重要可用性问题:需要重视,给以高优先级
- 4:可用性灾难:产品发布之前必须纠正
- 方法三:可用性分级的两个因素
- 多少用户会遇到这个问题
- 用户受该问题影响的程度

- 方法四:该问题只在第一次使用时出现,还是会永远出现。举例:菜单条中的下拉菜单
- 用户从不尝试下拉用图标表示的菜单
- 有人告诉他们后,可马上知道如何克服该不一致性问题
- 因此该问题不属于永久性的可用性问题
小结
- 常用评估范型和技术:范型和技术的区别
- 技术的选择:哪些影响因素
- DECIDE 评估框架:6 个步骤
- 可用性问题分级
- 为避免偏差,建议综合多个评价者的意见
- 研究发现,一位可用性专家作出的严重性评价与真实结果之间的误差在 0.5 以内(5 分制)的概率只有 55%
- 4 名专家所做评价的平均值,其概率为 95%
- 为避免偏差,建议综合多个评价者的意见
用户测试
背景
- 在受控环境中(类似于实验室环境)测量典型用户执行典型任务的情况
- 目的是获得客观的性能数据,从而评价产品或系统的可用性,如易用性、易学性等
- 最适合对原型和能够运行的系统进行测试
- 可对设计提供重要的反馈
- 在可用性研究中,往往把用户测试和其他技术相结合
测试设计
用户测试须考虑实际限制并做出适当的折衷:
- 应确保不同参与者的测试条件相同
- 应确保评估目标特征具有代表性
- 实验可重复,但通常不能得到完全相同的结果
- 以 DECIDE 框架为基础
测试设计步骤
- 定义目标和问题:
- 目标描述了开展一个测试的原因,定义了测试在整个项目中的价值
- 目标是对关注点的说明和解答
- 举例:对菜单结构的关注
- 用户在第一次尝试使用时将能选择正确的菜单
- 用户在少于 5 秒的时间内,能够导航到正确的 3 级菜单
- 选择参与者:
- 参与者的选择对于任何实验的成功至关重要
- 了解用户的特性有助于选择典型用户:要尽可能接近实际用户
- 通常也需要平衡性别比例
- 至少 4~5 位,5~12 位用户就足够了
- 设计测试任务
- 测试任务应当与定义的目标相关
- 测试任务通常是简单任务:如查找信息
- 有时采用较为复杂的任务:如加入在线社团等
- 任务不能仅限于所要测试的功能,应使用户全面的使用设计的各个区域
- 如关注搜索功能的可用性,可请求参与者搜索找出产品 X
- 更好的方法就是请求参与者找出产品 X 并同产品 Y 进行比较
- 每项任务的时间应介于 5~20 分钟
- 应当以某些合乎逻辑的方法安排任务:开始时,先提出简单问题有助于增强用户的自信心
- 明确测试步骤
- 在测试之前,准备好测试进度表和说明,设置好各种设备
- 正式测试前应进行小规模测试
- 在必要时,评估人员应询问参与者遇到了什么问题
- 若用户确实无法完成某些任务,应让他们继续下一项任务
- 测试过程应控制在 1 小时之内
- 必须分析所有搜集到的数据
- 数据搜集
- 确定如何度量观测的结果
- 使用的度量类型依赖于所选择的任务
- 定量度量和定性度量
常用的定量度量
- 完成任务的时间
- 停止使用产品一段时间后,完成任务的时间
- 执行每项任务时的出错次数和错误类型
- 单位时间内的出错次数
- 求助在线帮助或手册的次数
- 用户犯某个特定错误的次数
- 成功完成任务的用户数
参与者安排
- 各种实验情形的参与者不同
- 各种情形的参与者相同
- 参与者配对
参与者不同
- 随机指派某个参与者组执行某个实验情形
- 缺点:
- 要求有足够多的参与者
- 实验结果可能会受到个别参与者的影响。解决方法:随机分配 or 预测试
- 优点:
- 不存在“顺序效应“
- 即参与者在执行前一组任务时获得的经验将影响后面的测试任务
参与者相同
- 相同的参与者执行所有实验情形
- 与前一种方法相比,它只需一半的参与者
- 优点
- 能够消除个别差异带来的影响
- 便于比较参与者执行不同实验情形的差异
- 缺点
- 可能产生“顺序效应”
- 解决方法:均衡处理:如果有两项任务 A 和 B,那么,应让一半的参与者先执行 A,再执行 B,另一半则先执行 B,再执行 A
参与者配对
- 根据用户特性(如技能和性别等),把两位参与者组成一组,再随机地安排他们执行某一种实验情形
- 适用于参与者无法执行两个实验情形
- 缺点
- 实验结果可能会受一些未考虑到的重要变量的影响
- 如在评估网站的导航性能时,参与者使用互联网的经验将影响实验结果
- 因此,“使用互联网的经验”即可作为一个配对标准
几种安排方法的比较

测试准备(2023Fall 不涉及)
- 建造一个测试计划时间表:协调参与者的日程计划、小组成员的日程计划及实验室的可使用性
- 在测试过程中编写对应的脚本
- 脚本应当包括协调者和参与者交互的每一个方面,也应当包括一些意外事件
- 如参与者感觉有点灰心丧气,原型出现错误等
- 安排示范性测试(Pilot test)
- 测试可以在特定实验室里完成,也可以借助简陋的测试设备完成
- 应当使用一个客观的参与者
数据分析(2023Fall 不涉及)
变量
- 实验的目的是回答某个问题或测试某个假设,从而揭示两个或更多事件之间的关系
- 这些“事件”称之为“变量”
自变量
- 为回答假设问题,需被操作的一个或多个变量:即开始实验之前,已经设置好的变量
- 复杂的实验可能包含不止一个自变量:如假设用户的反应速度不仅取决于菜单选项的数目,也取决于菜单中应用的命令选择
因变量
- 能在实验中测量的变量
- 其值依赖于自变量的变
- 如:完成任务所花费的时间、出错的数目、用户偏爱和用户执行的质量
- 举例:
- 实验目标:若不用 12 点阵的仿宋体,而改用 12 点阵的楷体,那么阅读一屏文本的时间是否相同?
- 自变量:上例中的“字体”
- 因变量:上例中“阅读文本的时间”
分析方法
定量数据
- 最常用的描述性统计方法是次数统计:举例:是否认为该技术对改进命令的访问效率有帮助?
- 定量数据的次数统计、平均数统计


定性数据
- 通常按主题分类
- Eg.找出获得某信息的最快途径
总结报告
将测试的结果以书面形式反馈给产品的设计人员,以便于他们对设计进一步的分析和改进

图标设计评估实例-略
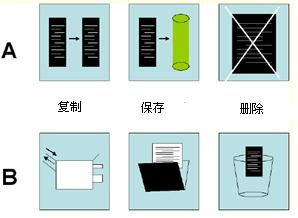
背景
为一个文件处理软件包设计一个新的界面,需要用图标提供展示
考虑应用两种图标设计形式
- 自然的图像(基于纸质文档象征)
- 抽象图像
目标:想知道哪一个设计使用户更容易记忆
假设:自然图标更容易记忆
自变量
- 图标的形式
- 自然的和抽象的
因变量
- 关心用户记忆精确性方面的性能,还是记忆速度方面的性能,还是用户偏爱等主观度量?
- 假设选择一个图标的速度是记忆容易程度的一个指标
- 在选择中错误的数目
- 选择一个图标所花费的时间
实验控制
- 使观察到的任何差别清晰地归结于自变量
- 使得对于因变量的度量是可比较的
- 提供一个界面,除图标设计外,其他内容确定
- 设计对每一个条件都能重复的选择任务:要选择适当的图标提示
实验细节
- 界面设计
- 向用户提交一项任务(如“删除一个文件”),要求用户选择适当的图标
- 为避免图标位置对学习的影响,在每次表示中每组图标位置的排列是随机变化的
- 为避免学习的转移,将用户分成两组,每组采用不同的开始条件
- 对于每个用户,测量完成任务的时间和所犯错误的数目……
讨论:从下表中可以得出什么结论?

网站评估实例
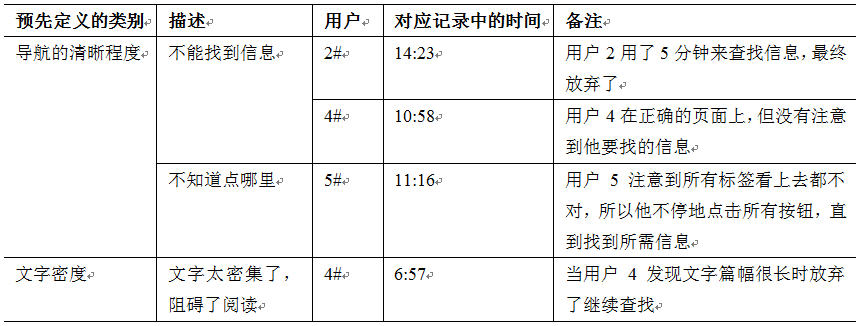
在对 MEDLINEplus 网站进行启发式评价后
- 发现了可用性问题,对网站做了修改
- 现计划对网站进行用户测试
评估步骤:
定义目标和问题
- 信息分类方法是否有效
- 用户能否进退自如并且找到需要的信息
选择参与者
- 通过问卷了解年龄、使用互联网的经验、查找医药信息的频度:挑选每个月使用互联网超过两次的人员
- 9 位来自测试中心所在地的医护人员/ 7 名是女性:符合可用性专家所建议的 5-12 位
- 预先声明要测试 NLM 的一个产品
设计测试任务
- 问题选自网站用户最经常提出的一些问题
- 设计了 5 项任务
- 任务 1:查找信息,了解肩膀上的黑痣有没有可能是皮肤癌
- 任务 3:查找信息,了解是否有丙肝疫苗
- 进行了小规模试验以确定任务的有效性
明确测试步骤
- 准备统一的说明稿,分为五个部分:以保证每一位参与者都得到相同的信息和相同的对待
- 测试在实验室环境中进行
部分一
- 参与者抵达后使用
- 签署协议

部分二
就坐后,解释测试目的和步骤

部分三
执行任务前说明

部分四
若参与者忘记说出想法或不知所措时提示用

部分五
- 任务完成之后填写调查问卷
- 询问参与者对某些问题的看法

数据搜集
- 评估小组事先设定了成功完成每项任务的标准:如必须找到并访问 3-9 个相关网页
- 记录用户执行任务的全过程:以下为参与者 A 在执行第一项任务时访问的资源

数据来源:
- 根据录像和交互记录计算用户执行任务的时间
- 问卷调查和询问阶段搜集到的数据
数据列表:
- 开始时间及完成时间
- 搜索时访问的网页及数量
- 搜索时访问的医药文献
- 用户的搜索路径
- 用户的负面评论和特殊的操作习惯
- 用户满意度问卷调查数据
数据分析
网站的结构,如专栏的安排、菜单的深度和链接的组织等
浏览的有效性,如菜单的使用、文字密度等。
搜索特征,如搜索界面、提示、术语的使用是否满足一致性要求
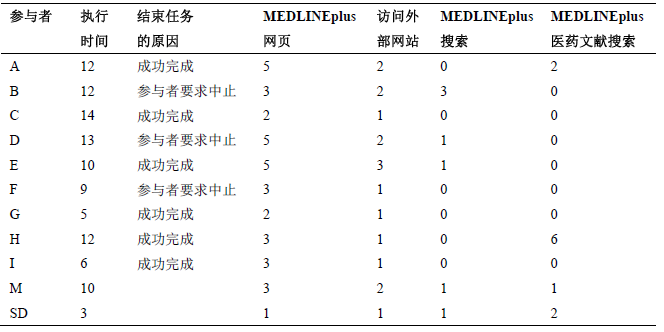
几个问题:
- 为什么使用字母代表用户?不应透露参与者的姓名
- “执行时间”与“结束任务的原因”有何关系?
- 对于成功完成的任务,执行时间介于 5~14 分钟
- 对于半途中止的任务,执行时间介于 9~13 分钟
- 其余数据说明了什么?
- 用户可以采取多种方式成功地完成任务
- 如参与者 A 和 C 使用了不同在线资源
总结、报告测试结果
主要问题是访问外部网站较为困难
分析搜索过程:有几位参与者在“健康话题”中查找不同类型的癌症时遇到了困难
问卷调查结果
- 参与者对 MEDLINEplus 的评价是中性的
- 非常易学,但不易于使用
- 在返回前一个屏幕时会遇到问题
小结
- DECIDE 评估框架:6 个步骤
- 可用性问题分级
- 用户测试的适用范围
- 用户测试步骤:各步骤文档的包含内容
- 能进行简单的数据分析
- 能设计和组织一个用户测试

