防御式编程 Defensive Programming
可用、正确和优秀的代码
- 编写大多数情况下都能用(可用)的代码很容易:但是提供意外输入会崩溃。
- 正确的代码绝不会崩溃
- 但所有可能输入集合很大,难以测试
- 并非所有正确的代码都是优秀的代码:可能逻辑难以理解,并且几乎无法维护。
- 优秀的代码是健壮的、高效的、当然也是正确的:即便面对不常见输入,产品级代码也不会崩溃和产生错误的结果。
编程中的常见设想
- 这个函数"绝不会"被那样调用:传递给我的参数总是有效的
- 这段代码肯定会"一直"正常运行:它绝对不会产生错误
- 如果我把这个变量标记为"仅限内部使用",就没有人会尝试访问这个变量
- 进行防御式编程时,不应该做任何设想!
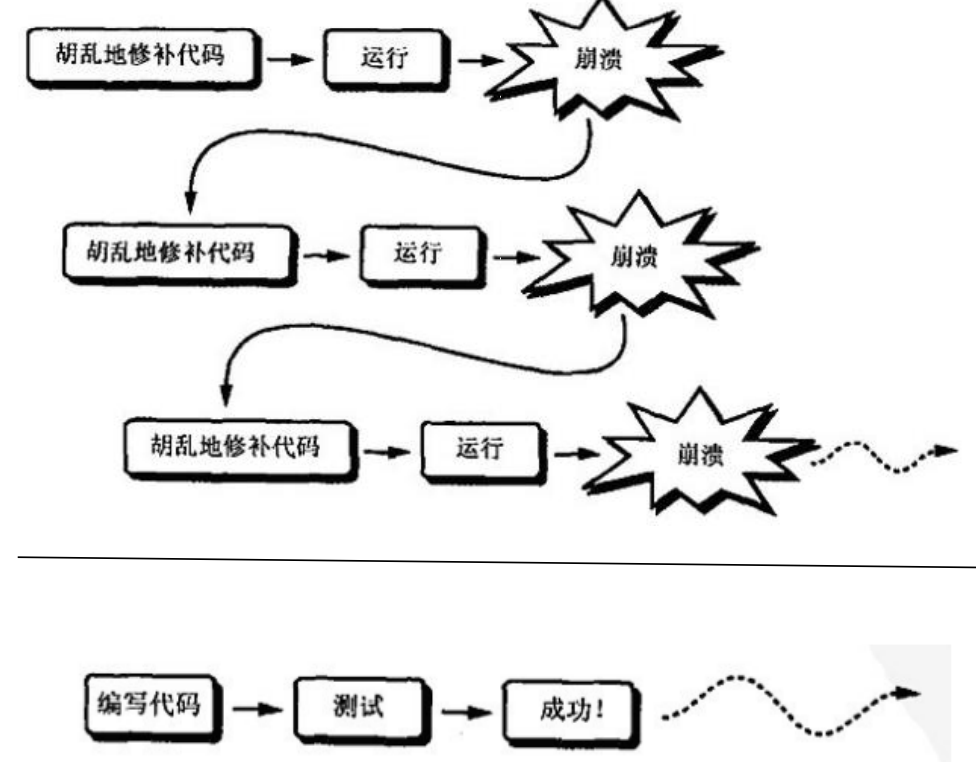
你的软件开发过程是怎样的?
什么是防御式编程
- 通过预见到(或至少预先推测到)问题所在,断定代码中每个阶段可能出现的错误,并做出相应的防范措施,来防止类似意外的发生。
- 防御式编程源自于防御式驾驶。
- 主要思想
- 子程序应该不因传入错误数据而被破坏,哪怕是由其他子程序产生的错误数据
- 换句话说,要承认程序都会有问题,都会被修改
关于防御式编程
- 区别于检查错误:防御性编程并不能排除所有的程序错误
- 区别于调试:防御式编程是一种防卫方式,而不是补救方式
- 区别于测试:测试不是防御式的,测试可以验证代码现在是正确的,但不保证在经历修改之后不会出错
防御式编程技巧
- 使用好的编码风格和合理的设计
- 不要仓促地编写代码
- 不要相信任何人
- 编写清晰而非简洁的代码
- 不让其他人做不该做的修补工作
- 编译时打开所有警告开关
- 检查所有的返回值
- 在声明位置初始化所有变量
- 尽可能推迟一些变量声明
- 使用安全的数据结构
1 | |
- 使用标准语言工具
- 审慎地进行强制转换
处理非法输入数据
- 好的程序应如何处理垃圾?
- 检查所有来源于外部的数据的值:
- 文件、用户、网络或其他外部接口
- 确保在允许范围内
- 检查子程序所有输入参数的值:因为数据来自于其他子程序
- 决定如何处理错误的输入数据:这很重要。
断言 Assertions
- 在开发期间使用的、让程序在运行时进行自检的代码,是对开发人员的警告,通常是一个子程序或宏
- 断言为真,表示程序运行正常
- 断言为假,表示代码中出现了意料之外的错误
- 构成(两个参数)
- 布尔表达式:描述假设为真的情况
- 显示的信息:断言为假时(不是必须的!)
- 举例
1 | |
断言的用途
- 输入参数或输出参数的取值处于预期的范围内
- 子程序开始(或结束)执行时,文件或流是处于打开(或关闭)的状态
- 子程序开始(或结束)执行时,文件或流的读写位置处于开头(或结尾)处
- 文件或流已用只读、只写或可读可写方式打开
- 仅用于输入的变量的值没有被子程序所修改
- 指针非空
- 传入子程序的数组或其他容器至少能容纳 X 个数据元素
- 表已初始化,存储着真实的数值
- 子程序开始(或结束)执行时,某个容器是空的(或满的)
- 一个经过高度优化的复杂子程序的运算结果和相对缓慢但代码清晰的子程序的运算结果相一致
什么时候使用断言
- 断言主要用于开发和维护阶段
- 帮助查清相互矛盾的假定、预料之外的情况、传递给子程序的错误数据等
- 生成产品代码时并不编译进去,不希望用户看到产品代码中的断言信息,同时避免降低系统性能
建立自己的断言机制
- 常见的高级语言都支持断言:如 C++、Java、C# 和 Microsoft Visual Basic 等
- 如果不直接支持断言也可以自己实现
- J2SE 1.3 及早期版本没有内建的断言机制
- C++ 中标准的 assert 宏并不支持文本信息
建立自己的断言机制:C++
1 | |
使用指导
- 用错误处理代码来处理预期会发生的非正常情况,用断言来检查永远不该发生的情况
- 错误处理:检查有害的输入数据
- 断言:检查代码中的 bug,可看作是可执行的注解
- 避免把需要执行的代码放到断言中:当关闭断言功能时,编译器会将其排除在外
1 | |
约束
- 用断言来注解并验证前/后置条件
- “契约式设计”的一种
- Preconditions: 子程序或类的调用方代码在调用子程序或实例化对象之前要确保为真的属性,是调用调用方代码对所调用代码要承担的义务。
- Postconditions: 子程序或类在执行结束后要确保为真的属性,是子程序或对调用方代码锁承担的责任。
- Invariants: 当程序执行到达特定点(如循环中、方法调用等)时都保持为真的条件,否则程序逻辑存在问题。
- 如果变量来源于系统外部,就应该用错误处理代码来检查和处理非法数据
1 | |
- 对于高健壮性的代码,应该先使用断言再处理错误
1 | |
前置条件
- 不要断言方法的规范
1 | |
- 可以断言非 public 方法的前置条件
1 | |
不变式 Invariants
- 永远都应该为真的条件
- 内部不变式
- 程序运行到特定时刻应该为真的事实
- 如:assert x > 0
- 控制流不变式
- 断言不会被运行到的代码,如 assert false: suit;
- 注意:将语句放置在编译器认为不会被运行到的地方会报错
- 类不变式
- 指类对象作为有效的类成员必须满足的条件
- 如:assert person.age >= 0 && person.age < 150;
- 在即将从 public 方法和构造函数中返回时断言类的不变式
注意
- 断言是提高软件质量技术的有益辅助手段
- 可看作是可执行的注解
- 相比注释,能更主动地对程序中的假定作出说明
- 不能依赖断言来让代码正常工作:最佳方式是在一开始不要在代码中引入错误
- 断言不能有任何副作用
1 | |
Question: 应该进行多少约束校验?
- 每一行都设置一个校验?过多的约束校验,可能使得代码的逻辑变得不明确
- 可读性是衡量程序质量的最佳标准
- 在主要函数中放置前置条件和后置条件,并且在关键的循环中放置不变条件,就已经足够了
- 在修正错误的地方加入一条断言也是一个良好的习惯
补充:断言举例
1 | |
- 冒泡排序的前置后置条件
- 前置条件不为空
- 后置条件为有序
- 另一种断言的用法是放在没有 default 处理的 switch 语句
1 | |
断言 vs. 错误处理
- 断言处理代码中不应发生的错误
- 错误处理处理那些预料中可能发生的错误
错误处理技术
- 错误可能而且必将发生
- 错误是预先就知道的,区别于程序中的 bug
- 如想打开的数据库文件已被删除,磁盘空间已满
- 用户错误:提供错误的输入,或试图进行荒谬的操作
- 程序员错误:是一种 Bug,由程序员引入的代码缺陷
- 意外情况:网络连接失败,打印机墨水用光等
- 错误处理技术用来处理那些预料中可能要发生的错误情况
- 返回中立值(如数值返回 0)
- 换用下一个正确的数据
- 返回与前次相同的数据
- 换用最接近的合法值 (如经度设置为 \((-180,180)\) 之间)
- 把警告信息记录到日志文件中
- 用语言内建的异常机制抛出一个异常
错误处理技术
- 返回中立值:继续执行操作并简单地返回一个没有危害的数值
- 数值计算可以返回 0
- 字符串操作可以返回空字符串
- 指针操作可以返回一个空指针
- 换用下一个正确的数据:在处理数据流的时候,返回下一个正确的数据即可
- 返回与上一次相同的数据
- "重用上一次正确的结果"
- 如 windows 系统崩溃后用上一次配置重启动
- 换用最接近的合法值
- 常出现在数值超出其正常设定的上下界的时候
- Velocity 的例子
- 把警告信息记录到日志文件中
- 在使用这种方法的时候需要对错误信息进行标示,或者将警告信息单独存放,以便快速查询定位
- 可以和其他技术结合使用
- 返回一个错误码:当只有系统的某些部分处理错误,而其他部分则不在本地(局部)处理错误时
- 设置一个状态变量的值
- 用状态值作为函数的返回值
- 用语言内建的异常机制抛出一个异常
- 调用错误处理子程序或对象
- 把错误处理集中在一个全局的错误处理子程序或对象
- 优点:能把错误处理的职责都集中到一起
- 代价:错误处理代码与整个程序紧密耦合
- 显示出错消息
- 当心:不要告诉系统的潜在攻击者太多东西
- "程序应该只在没有什么可做的情况下才向用户报告错误"
- 用最妥当的方法在局部处理错误
- 具体采用何种错误处理方法由具体程序员决定
- 灵活度高,但系统的整体性能将无法满足对其正确性或可靠性的需求
- 关闭程序:适用于人身安全攸关的应用程序
健壮性与正确性
- 处理错误最恰当的方式要根据出现错误的软件的类别而定
- 正确性(correctness):人身安全攸关的软件
- 指软件按照需求正确执行任务的能力
- 永不返回不准确的结果,哪怕不返回结果也比返回不准确的结果好
- 健壮性(robustness):消费类应用软件
- 指软件对于规范要求以外的输入情况的处理能力
- 要不断尝试采取某些措施,以保证软件可以持续地运转下去,哪怕有时做出一些不够准确的结果
错误处理代码示例
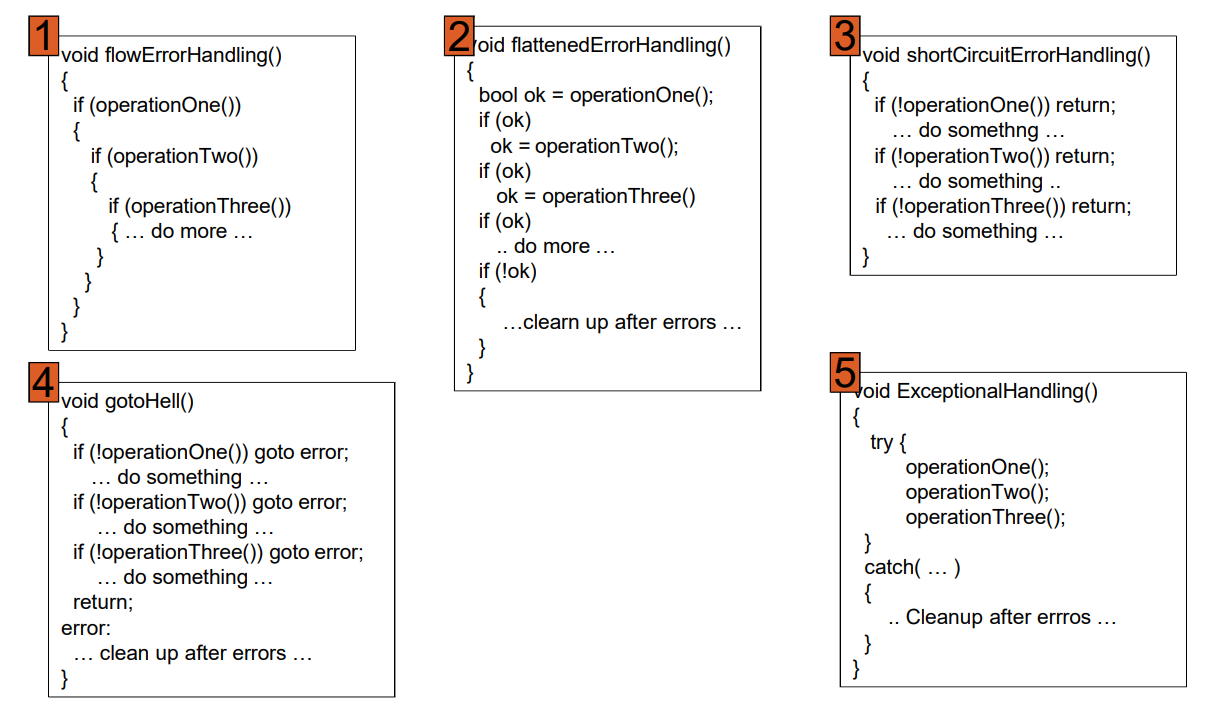
- 1 号:工作流:可读性差
- 2 号:扁平化,缺点是需要明显的控制变量
- 3 号:短路,需要做之后的处理
- 4 号:合适的
- 5 号:异常,异常的处理不明显
错误信息编写
- 当需要由用户清理错误时
- 以用户期望的方式呈现信息:“磁盘空间:0KB?”
- 确保用户能够理解错误信息
- 不要呈现毫无意义的错误代码:“Error code 707E"”
- 将后果严重的错误与仅仅是警告区分开来:可使用“Error:”或图标
- 提示用户每种选择可能的后果后再提出问题:“是否继续?”
异常
- 是把代码中的错误或异常事件传递给调用方代码的一种特殊手段
- 当遇到意料之外的情况,但不知道该如何处理时,可以抛出一个异常
- 同继承一样,谨慎使用可降低复杂度
- 基本结构
- 子程序使用
throw抛出一个异常对象 - 被调用链上层其他子程序的
try-catch语句捕获
- 子程序使用

- 为什么 C++ 没有
finally呢?因为 C++ 提供了资源获得和初始化 RAI,确保无论是否发生异常都可以完成清理工作。因为 C++ 可以自己进行析构。
Trace a Program Execution
1 | |
使用建议
- 用异常通知程序的其他部分,发生了不可忽略的错误
- 能提供一种无法被忽略的错误通知机制
- 消除了错误向外扩散的可能性
- 只有真正例外的情况下才抛出异常
- 仅在其他编码实践方法无法解决的情况下才使用异常(同断言类似,处理罕见且不该发生的情况)
- 会增加复杂度:调用子程序的代码需要了解被调用代码中可能会抛出的异常,弱化了封装性
- 不能用异常来推卸责任:可以在局部处理就在局部处理掉
- 避免在构造函数和析构函数中抛出异常,除非你在同一地方把它们捕获:C++中,构造函数中的异常会造成资源泄露
- 在恰当的抽象层次抛出异常:确保异常的抽象层次与子程序接口的抽象层次是一致的
举例
- 抛出的异常也是程序接口的一部分,和其他具体的数据类型一样
1 | |
- 子程序的调用方代码不是与 Employee 类的代码耦合,而是与比 Employee 类层次更低的抛出 EOFException 异常的代码耦合起来了
改进
GetTaxId()代码应抛回一个与其所在类的接口相一致的异常
1 | |
- 在设计上需要增加 EmployeeDataNotAvailable 异常类型, 并将更底层的 EOFException 异常映射为该异常类型 3
使用建议(补)
- 在异常消息中加入关于导致异常发生的全部信息:确保消息中含有为理解异常抛出原因所需的信息,如数组下标错误
- 避免使用空的 catch 语句:意味着 try 或 catch 里的代码不对
1 | |
使用建议(补)
- 了解所用函数库可能抛出的异常
- 未能捕获由函数库抛出的异常可导致程序崩溃
- 可通过编写原型代码来演练该函数库
- 把项目中对异常的使用标准化
- 当抛出多种类型的异常,如对象、数据及指针的话,则考虑建立一个标准
- 创建项目的特定异常类:构造自己的异常类继承体系
- 规定哪些异常在局部处理,哪些不在局部处理
- 规定是否可以在构造或析构函数处理异常
- 确定是否要使用集中的异常报告机制
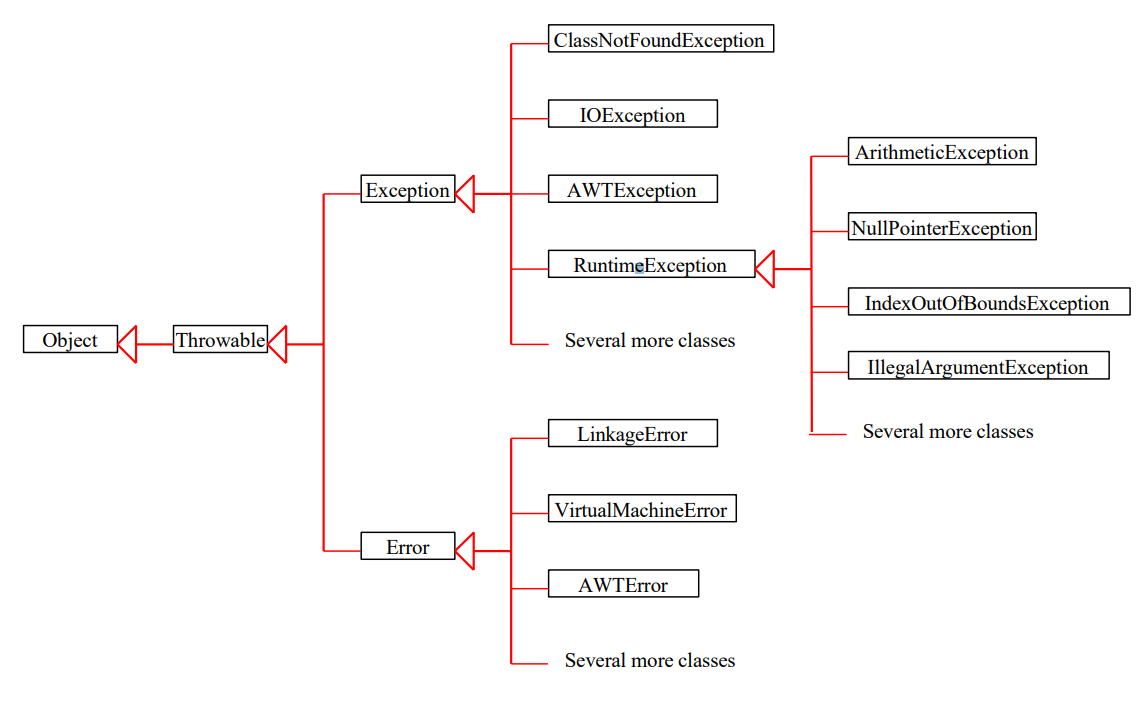
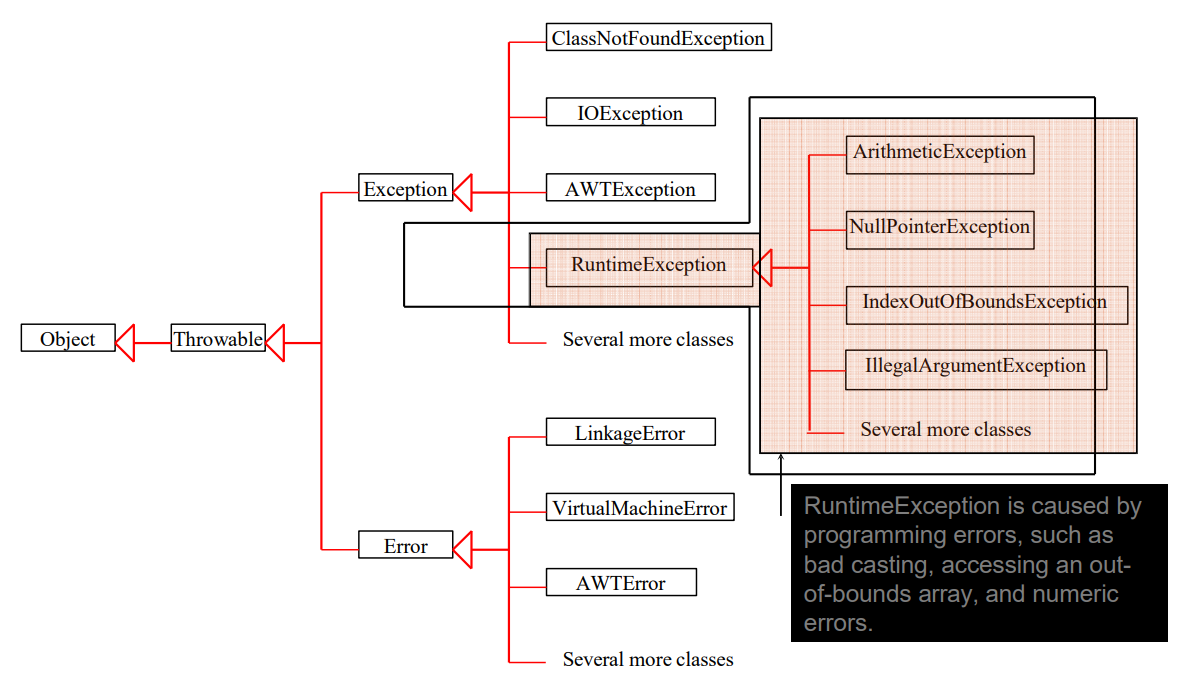
Exception Classes
System Errors
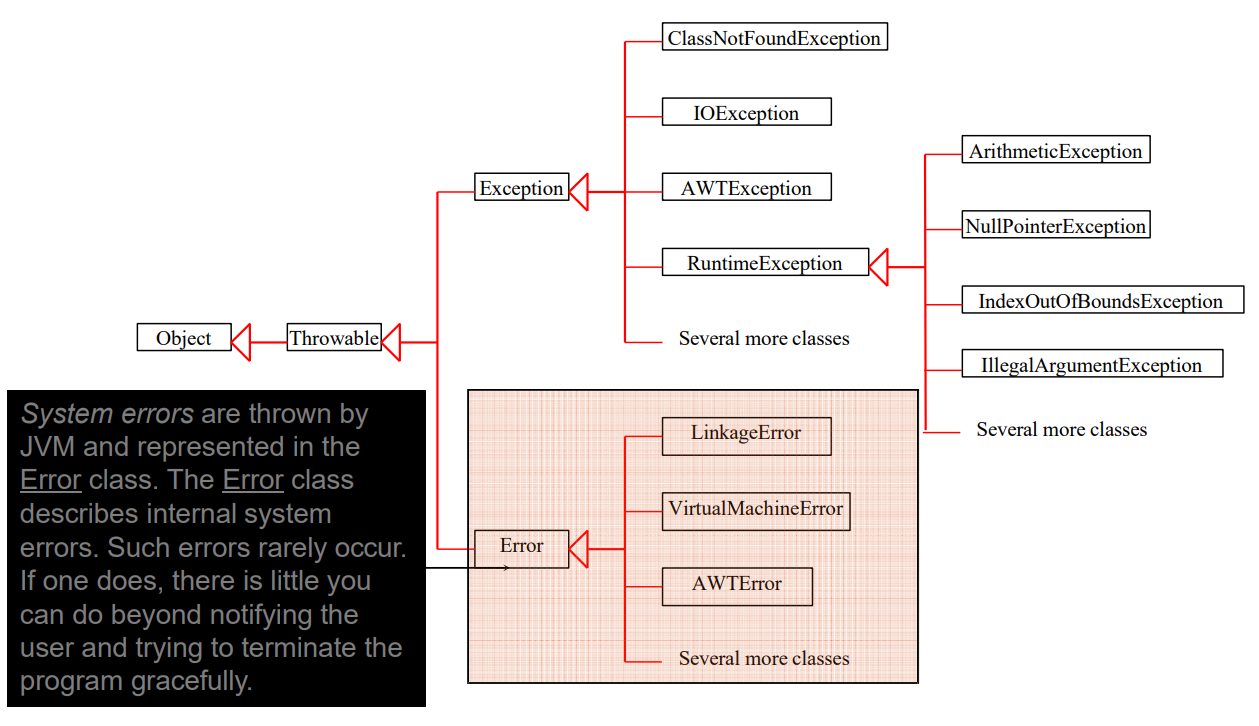
Exceptions
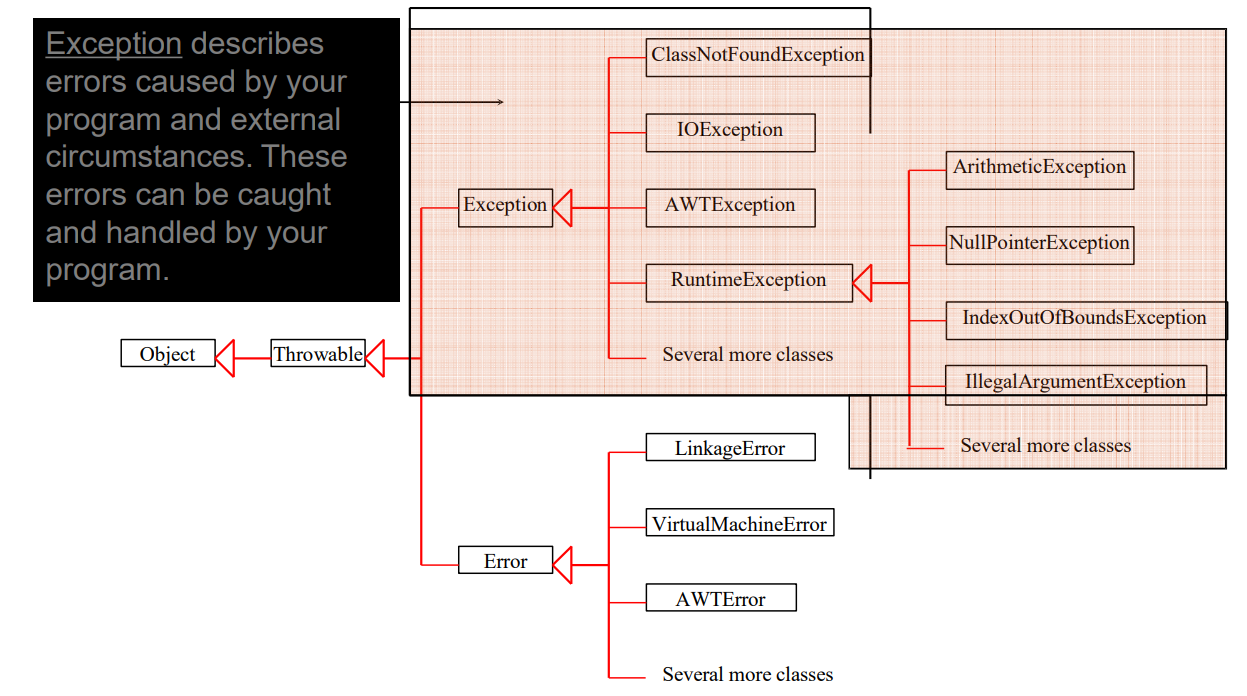
Runtime Exceptions
- 考虑创建一个集中的异常报告机制
1 | |
- 集中的异常报告机制
- Visual Basic 示例: 集中的异常报告机制(调用部分)
1 | |
- 此处的异常报告只是一个非常简单的情况,实际开发中可以根据异常处理的需要开发或简或繁的代码
使用建议(补)
- 考虑异常的替换方案
- 不要因为编程语言提供了异常而使用它:“深入一种语言去编程”
- 应自始至终考虑各种各样的错误处理机制
- 思考,是否真的需要处理异常
1 | |
通过隔栏包容错误
- 隔栏 Barricade
- 以防御式编程为目的而进行隔离的一种方法
- 把某些接口选定为"安全"区域的边界,对穿越安全区域边界的数据进行合法性校验
- 隔栏可以将检验工作集中在特定的模块中,从而降低其它部分采用防御式编程的成本
- 隐喻:
- 船体外壳上装备的隔离舱
- 手术室的消毒处理
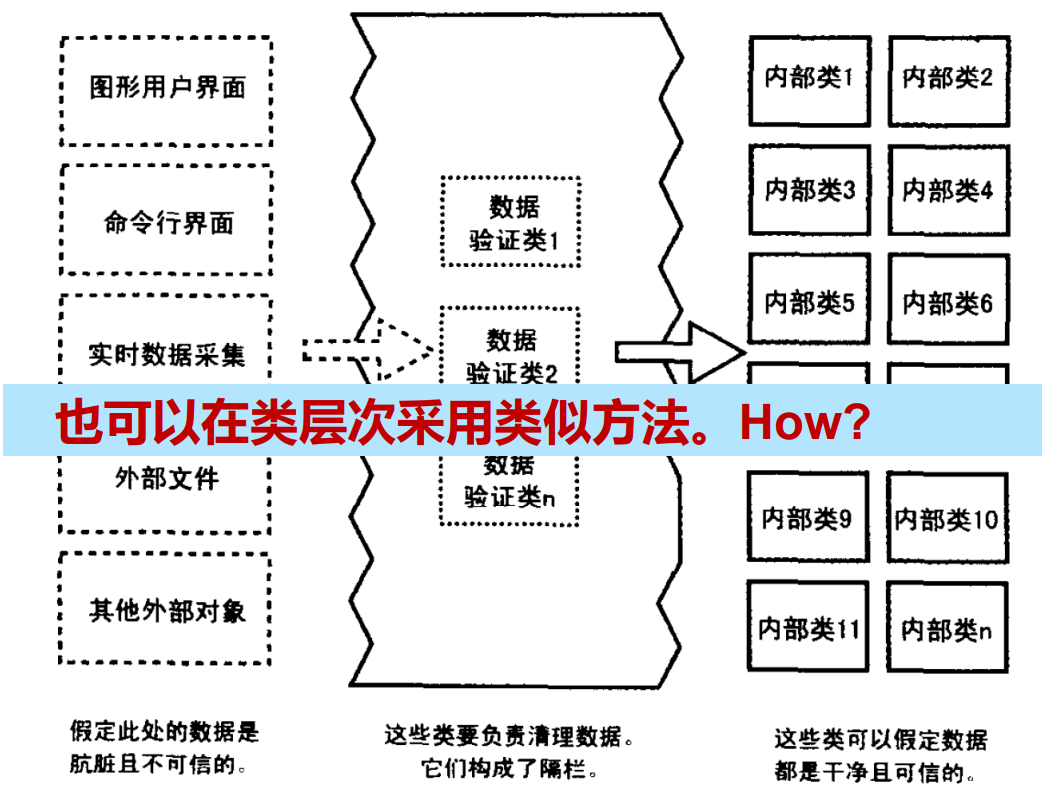
- 在输入数据时将其转换为恰当的类型
- 输入数据通常是字符串或数字
- 有时映射为"是""否"等布尔变量,有时是枚举变量
- 程序中长时间传递类型不明的数据,会增加程序的复杂度和崩溃的可能性
- 应该在输入数据后立即将其转换到恰当的类型
隔栏 vs.断言
- 隔栏的使用使断言和错误处理有了清晰的区分
- 隔栏部分包含了"脏数据":隔栏外部的程序应该使用错误处理技术,在那里对数据做任何的假定都是不安全的。
- 通过隔离部分之后的是"干净数据"
- 隔栏内部的程序就应使用断言技术,因为传进来的数据应该己在通过隔栏时被清理过了
- 隔栏内子程序出现错误数据,就是程序里的问题
辅助调试的代码
- 防御式编程的另一重要方面是使用调试助手(辅助调试的代码),从而帮助快速检测错误
- 误区: 产品级软件的种种限制也适用于开发中的软件,如性能、资源
- 正确的认识:应该在开发期间牺牲一些速度和资源,从而换取可以让开发更顺畅的内置工具
- 应该尽早地引入辅助调试的代码
进攻式编程 Offensive Programming
- 进攻式编程是主动暴露可能出现错误的态度:在开发阶段让它显现出来,而在产品代码运行时让它能够自我恢复
- 常用的进攻式编程方法
- 确保断言语句使程序终止运行
- 完全填充分配到的所有内存
- 完全填充己分配到的所有文件或流
- 确保每一个 case 语句中的 default 分支或 else 分支都能产生严重错误(如终止程序)
- 在删除一个对象之前把它填满垃圾数据
- 让程序把错误日志文件用电子邮件发给你
移除辅助调试代码的方法
- 辅助调试的代码会使软件的体积变得庞大且速度变慢
- 使用类似 ant 和 make 这样的版本控制工具和 make 工具
- 在开发模式下,你可以让 make 工具把所有的调试代码都包含进来一起编译
- 在产品模式下,又可以让 make 工具把那些你不希望包含在商用版本中的调试代码排除在外
- 使用内置的预处理器:以用编译器开关来包含或排除调试用的代码
- C++示例:直接使用预处理器来控制调试用的代码,所有使用辅助调试代码的地方都通过预处理器判断
1 | |
使用内置的预处理器
- 另一种更简约的形式
- 写一个能与预处理器指令同时使用的宏
1 | |
移除辅助调试代码的方法(补)
- 使用调试存根 debugging stubs:开发代码中调用某子程序进行调试检查,产品代码中使用桩子程序替换它
- C++示例: 一段使用调试 stub 的子程序
- 在开发阶段,
CheckPointer()子程序会对传入的指针进行全面检查
1 | |
使用调试存根
- C++ 示例:在开发阶段检查指针的子程序
1 | |
- C++ 示例:在产品代码中检查指针的子程序
1 | |
产品代码中应该保留多少防御式代码
- 开发阶段:显示出的错误越多越好,引入很多防御代码
- 发布阶段:希望错误尽可能偃旗息鼓,不要影响代码执行
- 保留那些检查重要错误的代码
- 去掉检查细微错误的代码
- 去掉可以导致程序硬性崩溃的代码:用户无法保存必要数据
- 保留可以让程序稳妥地崩溃的代码:用于诊断潜在的严重错误
- 为你的技术支持人员记录错误信息
- 确认留在代码中的错误消息是友好的:"发生了内部错误",可联系 XX
如何对待防御式编程
- 过度的防御式编程也会引起问题
- 程序会变得臃肿而缓慢
- 增加了软件的复杂度
- 防御式代码同样会有缺陷
- 正确的态度
- 采用防御的姿态
- 考虑好什么地方进行防御
- 因地制宜地调整防御式编程的优先级
练习
- 修改以下代码,使之变得更“好”
1 | |

