摘要
事务通过启用对共享数据的计算来简化并发编程,这些共享数据与其他并发计算隔离并且对故障具有弹性。现代数据库为事务提供了不同的一致性模型,对应于一致性和可用性之间的不同权衡。在这项工作中,我们研究了检查事务数据库的给定执行是否遵循某种一致性模型的问题。我们证明了诸如读提交、读原子和因果一致性之类的一致性模型是多项式时间可检查的,而前缀一致性和快照隔离通常是 NP 完全的。这些结果补充了先前有关可串行性的 NP 完整性结果。此外,在 NP 完全一致性模型的背景下,我们设计了多项式时间的算法,假设输入执行中的某些参数(例如会话数)是固定的。我们在几个生产数据库的背景下评估这些算法的可扩展性。
笔者修改了 DBCop 的部分代码:https://git.nju.edu.cn/EagleBear/dbcop-verifier
作者:
- RANADEEP BISWAS, Universite de Paris, IRIF, CNRS, France
- CONSTANTIN ENEA, Universite de Paris, IRIF, CNRS, France
INTRODUCTION
事务通过启用对共享数据的计算来简化并发编程,这些共享数据与其他并发计算隔离并且能够适应故障。现代数据库提供各种形式的事务,对应于一致性和可用性之间的不同权衡。最强级别的一致性是通过可序列化事务实现的[Papadimitriou 1979],其并发执行的结果与按某种顺序原子执行事务相同。不幸的是,串行化对系统的可用性带来了严重的损失,例如,假设数据库是通过可能遭受分区或故障的网络访问的。因此,现代数据库通常对事务提供较弱的保证,通过弱一致性模型形式化,例如因果一致性[Lamport 1978]和快照隔离[Berenson et al 1995]。
提供事务的大型数据库的实现很难构建和测试。例如,分布式(复制)数据库必须考虑部分故障,其中某些组件或网络可能会发生故障并产生不完整的结果。确保容错依赖于难以设计和推理的复杂协议。黑盒测试框架 Jepsen [Kingsbury 2019] 在许多生产分布式数据库中发现了大量微妙的问题。
测试事务数据库提出了两个问题:(1)导出一组合适的测试场景,例如注入系统的故障和要执行的事务集,以及(2)导出有效的算法来检查给定的执行是否满足所考虑的一致性模型。 Jepsen 框架旨在通过使用随机化来解决第一个问题,例如随机引入故障并随机选择事务中的操作。这种方法的有效性已在最近的工作中得到正式证明 [Ozkan et al 2018]。然而,第二个问题基本上尚未得到探讨。 Jepsen 以一种相当特别的方式检查一致性,重点关注给定一致性模型的特定类别的违规,例如脏读(从中止的事务中读取值)。这个问题具有挑战性,因为一致性规范非常重要,并且无法使用例如添加到客户端代码中的标准本地断言来检查它们。
除了可串行化之外,检查执行正确性的复杂性也很复杂。某些一致性模型是未知的。检查可串行性已被证明是 NP 完全的 [Papadimitriou 1979],并且在非事务上下文中检查因果一致性已知需要多项式时间 [Bouajjani et al 2017]。在这项工作中,我们试图通过调查这个问题的复杂性来填补这一空白。几个一致性模型,并且在 NP 完整性的情况下,设计多项式时间的算法,假设输入执行的某些参数(例如会话数)有固定界限。
我们考虑了实践中最流行的几种一致性模型。其中最弱的是提交读(RC)[Berenson et al 1995],要求事务中读取的每个值都由提交的事务写入。读取原子(RA)[Cerone et al 2015] 要求在事务中连续读取同一变量返回相同的值(也称为可重复读取 [Berenson et al 1995]),并且事务“看到”前一个写入的值同一会话中的事务。一般来说,我们假设事务是在会话中组织的[Terry et al 1994],会话是应用程序执行期间执行的事务序列的抽象。因果一致性(CC)[Lamport 1978] 要求如果事务
我们在本文中探讨的算法问题为这些一致性模型带来了一个新的规范框架,该框架依赖于执行中的写入-读取关系(也称为读取)这一事实,将读取与写入其数据的事务相关联。值,可以有效地定义。可以从每个值最多写入一次(变量可以写入任意次数)的执行中轻松提取写-读关系。这可以通过使用唯一标识符标记值来轻松实现(例如,随着每次新写入而递增的本地计数器与客户端/会话标识符相结合)1。由于实际的数据库实现是数据无关的[Wolper 1986],即它们的行为不依赖于事务中读取或写入的具体值,因此任何潜在的错误行为都可能在每个值最多写入一次的执行中暴露出来。因此,这个假设不失一般性。
之前的工作 [Bouajjani et al 2017; Burckhardt et al 2014; Cerone et al 2015] 使用两种辅助关系形式化了这种一致性模型:为每个事务定义其观察到的事务集的可见性关系,以及定义事务提交到“全局”内存的顺序的提交顺序。满足某些一致性模型的执行被定义为存在可见性关系和遵守某些公理的提交顺序。在我们的例子中,从执行中导出的写-读关系扮演了可见性关系的角色。这种简化使我们能够陈述一系列定义这些一致性模型的公理,这些模型具有共同的形状。直观上,它们定义了事务
我们确定检查执行是否满足 RC、RA 或 CC 是多项式时间,而同样的问题对于 PC 和 SI 来说是 NP 完全的。此外,在 NP 完全一致性模型(PC、SI、SER)的情况下,我们表明,只要输入执行中的会话数被认为是固定的(即, 不计入输入大小)。更详细地说,我们确定,当会话数量固定时,检查 SER 可以简化为具有多项式大小的空间中的搜索问题。 (该算法适用于任意执行,但其复杂性一般来说会以会话数量呈指数级增长)然后,我们表明,使用执行转换,可以在多项式时间内将检查 PC 或 SI 减少为检查 SER,粗略地说, ,将每个事务分为两部分:一部分包含所有读取,一部分包含所有写入(SI 还需要添加一些额外的变量,以便处理在公共变量上写入的事务)。我们通过依赖称为通信图的执行抽象来进一步扩展这些结果 [Chalupa et al 2018]。粗略地说,通信图的顶点对应于会话,边表示两个会话访问(读或写)同一个变量。我们证明,只要通信图的双连通分量具有固定大小,所有这些标准都是多项式时间可检查的。
我们对我们的算法在 CockroachDB [Cockroach 2019a] 的执行上进行了实验评估,该数据库声称实现了可串行性 [Cockroach 2019b],但承认存在异常的可能性;Galera [Galera 2019a] 的文档包含关于是否实现快照隔离的相互矛盾的声明[Galera 2019b,c] 和 AntidoteDB [Antidote 2019a],声称实现因果一致性 [Antidote 2019b]。我们的实施报告在所有情况下都违反了这些标准。我们发现 AntidoteDB 的一致性违规是新颖的,并且已得到其开发人员的证实。我们证明了我们的算法是高效且可扩展的。特别是,我们表明,尽管我们算法的渐近复杂度一般是指数级的(相对于会话数),但在实践中并没有执行最坏情况的行为。
总而言之,这项工作的贡献有四个方面:
- 我们开发了一个新的规范框架来描述常见的事务一致性标准(§2);
- 我们证明检查 RC、RA 和 CC 是多项式时间,而检查 PC 和 SI 是 NP 完全的(§3);
- 我们证明 PC、SI 和 SER 是多项式时间可检验的,假设输入执行的通信图具有固定大小的双连通分量(§4 和§5);
- 我们对生产数据库生成的执行算法进行实证评估(§6);
这些贡献结合起来形成了一个用于验证事务一致性模型的有效算法框架。据我们所知,我们是第一个研究大多数一致性模型的渐近复杂性的人,尽管它们在实践中很普遍。
其他材料可在 [Biswas 和 Enea 2019] 中找到。
CONSISTENCY CRITERIA
Histories
我们考虑一个存储一组变量
是读取值
定义 2.1。事务
是一组有限的操作 以及 上的严格全序 ,称为程序顺序,program order。
我们使用 $t, t_1, t_2 \dots $ 来排列事务。事务
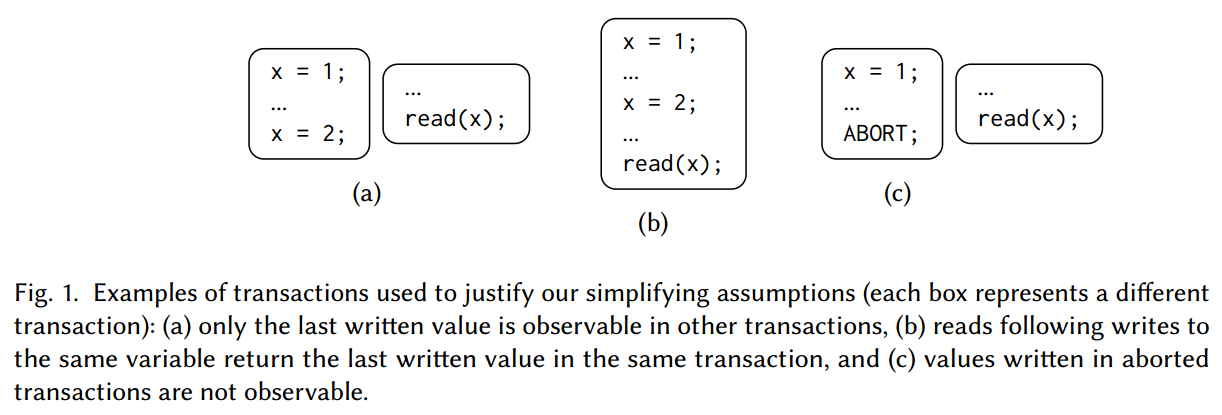
为了简化说明,我们假设每个事务
一致性标准在称为历史(history)的执行的抽象视图上形式化。历史记录仅包含成功或已提交的事务。在数据库上下文中,始终假设中止事务的影响对其他事务不可见,因此可以忽略它们。例如,图 1c 中的
定义 2.2。历史
是一组事务 以及严格的偏序(称为会话顺序),以及关系 称为写-读关系,当且仅当
的反函数是一个全函数(total function),如果 ,则 ,并且 - $ \so \cup \wr$ 是无环的。
全函数意味着每一个读操作读到的值都对应着对该变量的更早的一个写操作。
为了简化技术说明,我们假设每个历史记录都包含写入所有变量初始值的不同事务。此事务先于
当
Axiomatic Framework
我们描述了一个公理框架来描述满足特定一致性标准的历史集。总体原则是,如果历史记录的事务存在严格的总顺序(称为提交顺序,用
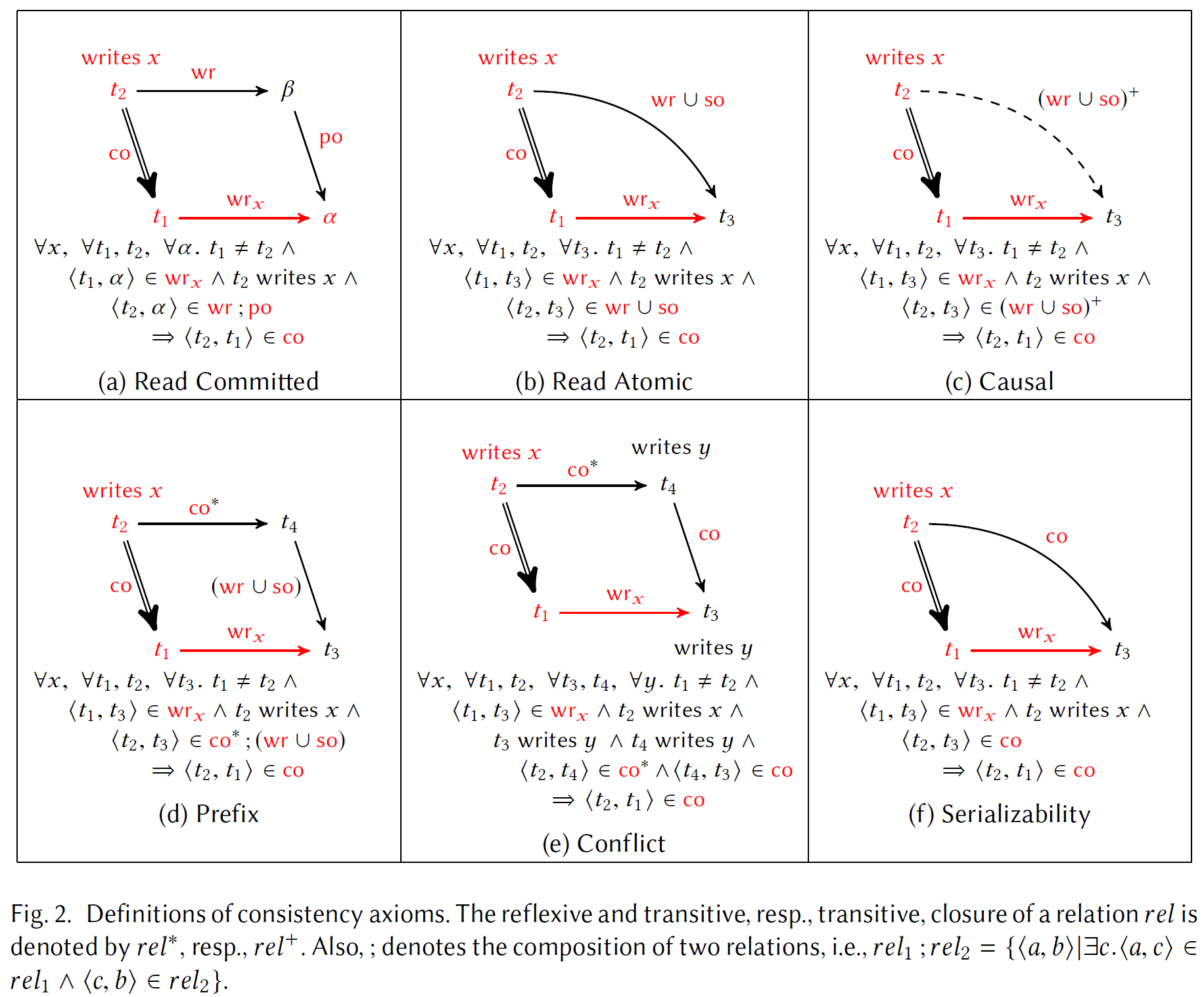
我们使用的公理具有统一的形式:它们定义了在历史记录中读取的事务
更准确地说,这些公理是以下形式的一阶公式(像往常一样,这些公式在历史记录
其中
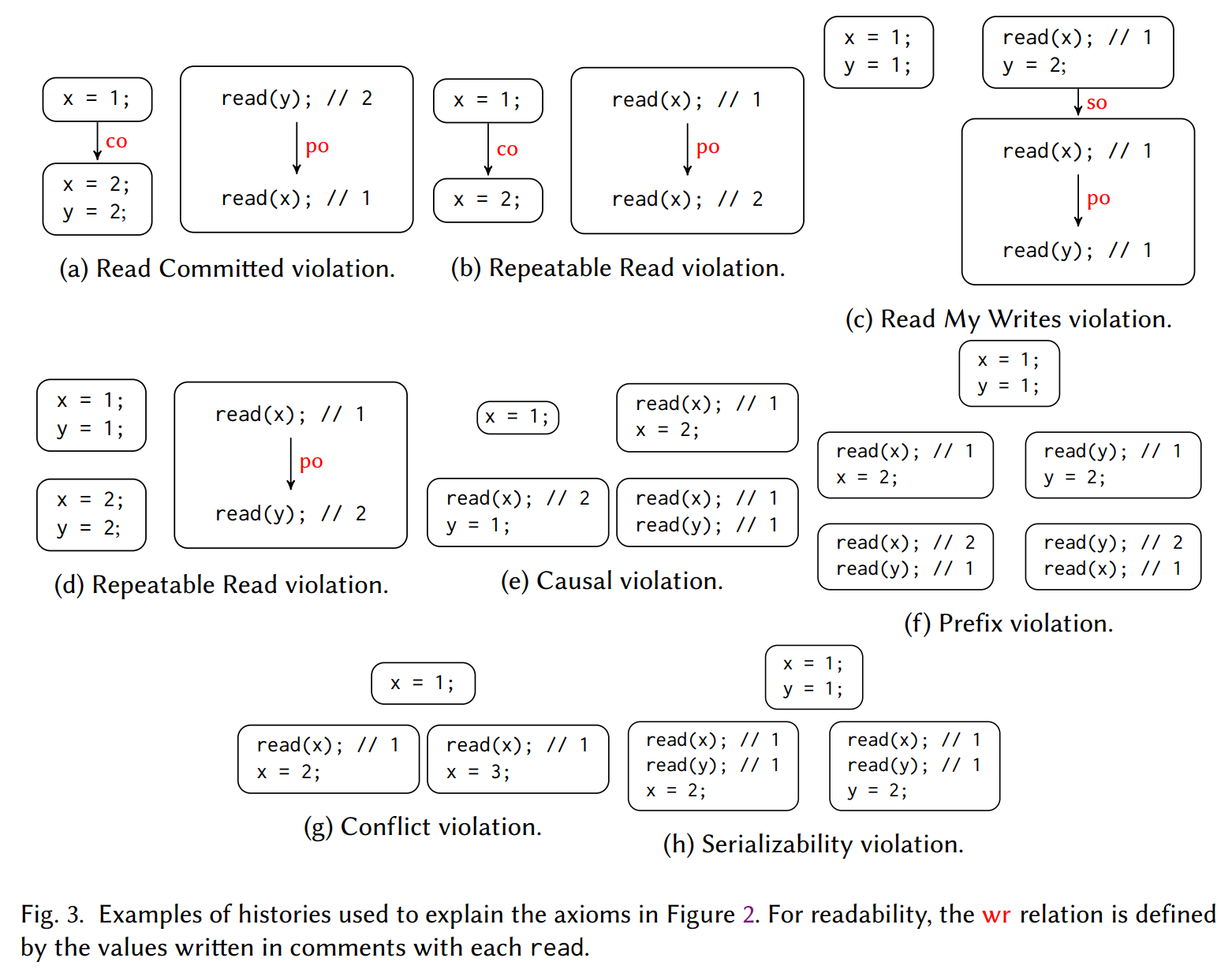
图 2 给出了整篇论文中使用的公理。属性
下面,我们解释我们考虑的其余一致性标准以及定义它们的公理。读原子(RA)[Cerone 等人 2015] 是由读原子公理定义的读提交的强化,它规定对于任何事务
下面的引理表明,对于满足 Read Atomic 的历史,
引理 2.3
设
是历史。如果 满足 Read Atomic,则对于每个事务 和两次读取 且 。
因果一致性(CC)[Lamport 1978] 由因果公理定义,该公理指出,对于任何事务
前缀一致性(PC)[Burckhardt et al. 2015]是 CC 的加强,它要求每个事务遵守所有事务之间提交顺序的前缀。直觉上观察到的事务是
快照隔离(SI)[Berenson et al. 1995] 是对 PC 的强化,如果两个事务发生冲突,即不允许两个事务观察到相同的提交顺序前缀,即写入公共变量。它是由前缀公理和另一个称为冲突公理的规则结合定义的。冲突公理要求对于任何事务
最后,可串行性(SER)[Papadimitriou 1979] 由同名公理定义,它要求对于任何写入事务
下一个引理说明了这些公理之间的关系(参见附录 A 的证明)。
引理 2.4 以下蕴涵成立:
CHECKING CONSISTENCY CRITERIA
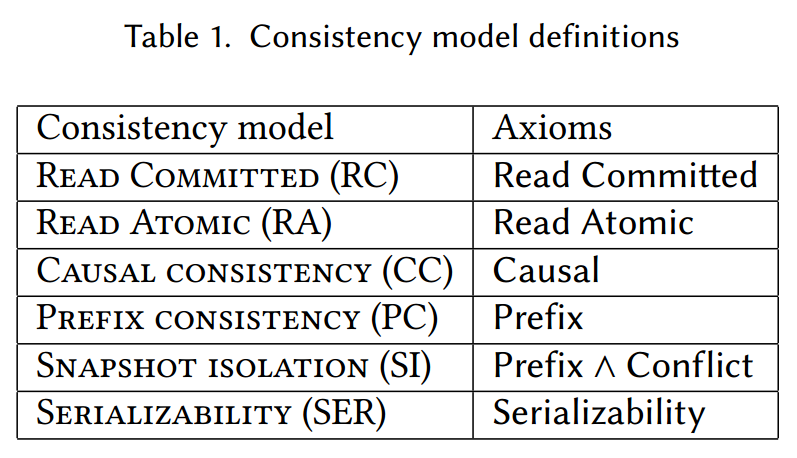
本节确定了针对给定历史记录检查表 1 中不同一致性标准的复杂性。更准确地说,我们表明可以在多项式时间内检查已提交读、原子读和因果一致性,而检查其余标准的问题是 NP 完全的。
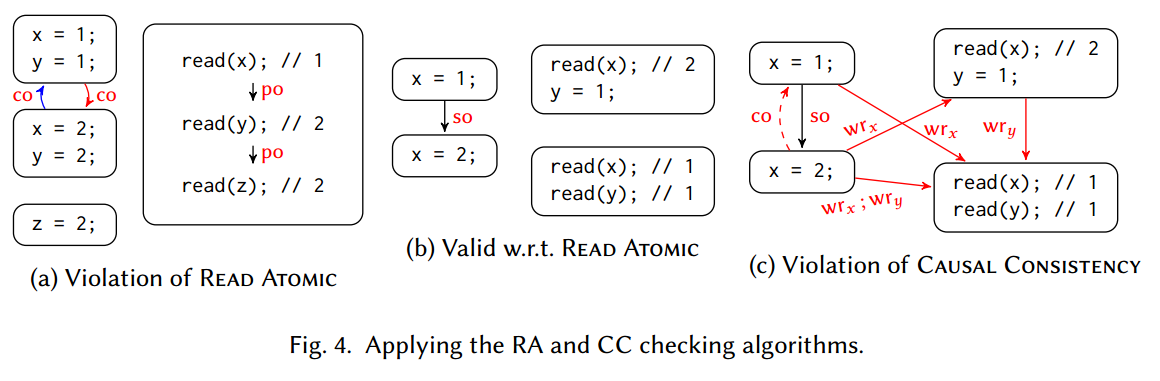
直观上,多项式时间结果基于以下事实:定义这些一致性标准的公理不包含蕴涵左侧的提交顺序 (

算法 1 列出了我们检查 CC 的过程。如上所述,
TODO
来表示因果公理。以下是这些算法在多项式时间内运行的结果(或者等效地,可以在包含给定历史中的
定理 3.1. 对于任何标准
,检查给定历史是否满足 C 的问题是多项式时间。
另一方面,检查 PC、SI 和 SER 通常是 NP 完全的。我们使用布尔可满足性(SAT)的减少来展示这一点,该减少统一覆盖了所有三种情况。就 SER 而言,Papadimitriou [1979] 提供了 的 NP 完整性结果的新证明,该证明使用了所谓的非循环 SAT 的约简,并且不能扩展到 PC 和 SI。
定理 3.2. 对于任何准则
,检查给定历史是否满足 C 的问题是 NP 完全的。
证明:TODO
CHECKING CONSISTENCY OF BOUNDED-WIDTH HISTORIES
在本节中,我们将展示在给定历史记录的宽度(即相互无序事务的最大数量)的假设下,检查前缀一致性、快照隔离和可串行性变成了多项式时间。会话顺序受固定常数限制。如果我们考虑会话顺序是事务序列的并集(以写入初始值的虚构事务为模)的标准情况,即一组会话,那么历史的宽度就是会话的数量。我们首先提出一种用于检查可串行性的算法,该算法是当宽度受固定常数限制时的多项式时间。一般来说,该算法的渐近复杂度在历史宽度上是指数级的,但这种最坏情况的行为在实践中并没有被执行,如第 6 节所示。然后,我们证明可以减少检查前缀一致性和快照隔离检查可串行性问题的多项式时间。
Checking Serializability
我们提出了一种用于检查给定历史记录的可序列化性的算法,该算法通过按照与会话顺序一致的顺序逐一“线性化”事务来构造有效的提交顺序(满足序列化)(如果有)。在任何时候,已经线性化的事务集都由会话顺序的反链唯一确定(即,一组相互无序的事务 w.r.t.
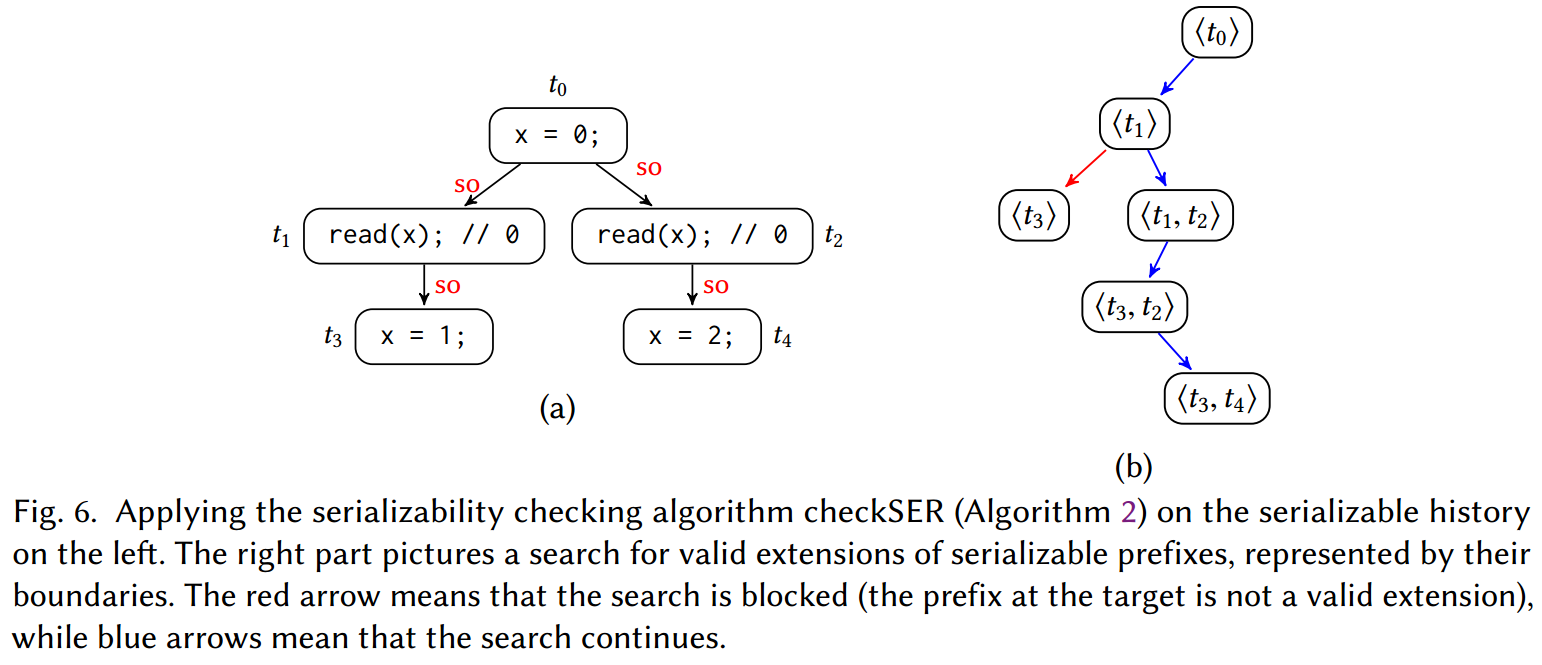
历史
历史
与 中的会话顺序和写-读关系不矛盾,即 是无环的; 是 中事务的全序; 将 中的事务排序在 中的事务之前,即对于每个 , ; 不会对任何两个事务 进行排序; - 历史记录
以及提交顺序 满足定义可串行性的公理,即 。
对于图 6a 中的历史记录,前缀
不从 之外的事务读取,即对于每个 , 。 - 对于
写入的每个变量 ,在 之外不存在事务 读取由 写入的 值,即对于每个 和每个 , , 。(原文如此,笔者认为此处应该改为 )
对于图 6a 中的历史记录,我们有
令
以下引理对于证明初始空前缀的迭代有效扩展可用于表明给定历史是可序列化的至关重要。
引理 4.1 对于历史
的可序列化前缀 ,如果前缀 是 的有效扩展,则扩展后的前缀是可序列化的。
证明 令
TODO

算法 2 列出了我们用于检查可串行性的算法。它被定义为一个递归过程,搜索给定前缀的有效扩展序列(最初,该前缀为空),直到覆盖整个历史记录。图 6b 描绘了图 6a 中历史记录的搜索情况。右侧分支(包含蓝色边缘)仅包含有效扩展,并且它到达包含历史记录中所有事务的前缀。
定理 4.2 历史
是可序列化的当且仅当 返回 true。
证明 TODO
算法 2 枚举给定历史
推论 4.3 对于任意但固定的常数
,检查宽度至多为 k 的历史的可串行性的问题是多项式时间。
Reducing Prefix Consistency to Serializability
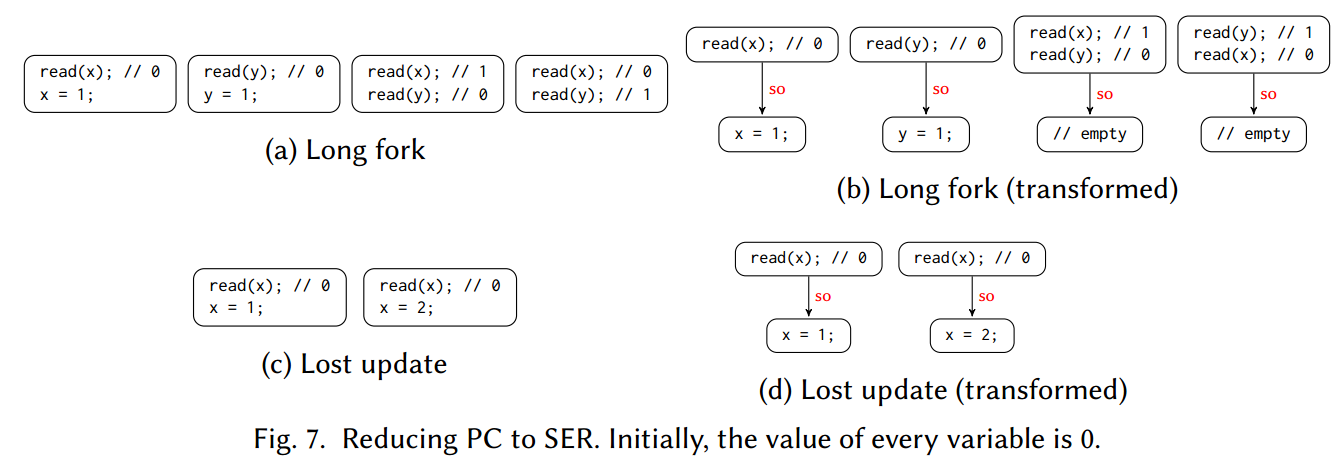

定理 4.8 历史
满足前缀一致性当且仅当 是可序列化的
推论 4.9 对于任意但固定的常数
,检查宽度至多为 k 的历史的前缀一致性的问题是多项式时间。
Reducing Snapshot Isolation to Serializability

定理 4.10 历史
满足 SI 当且仅当 是可序列化的

COMMUNICATION GRAPHS
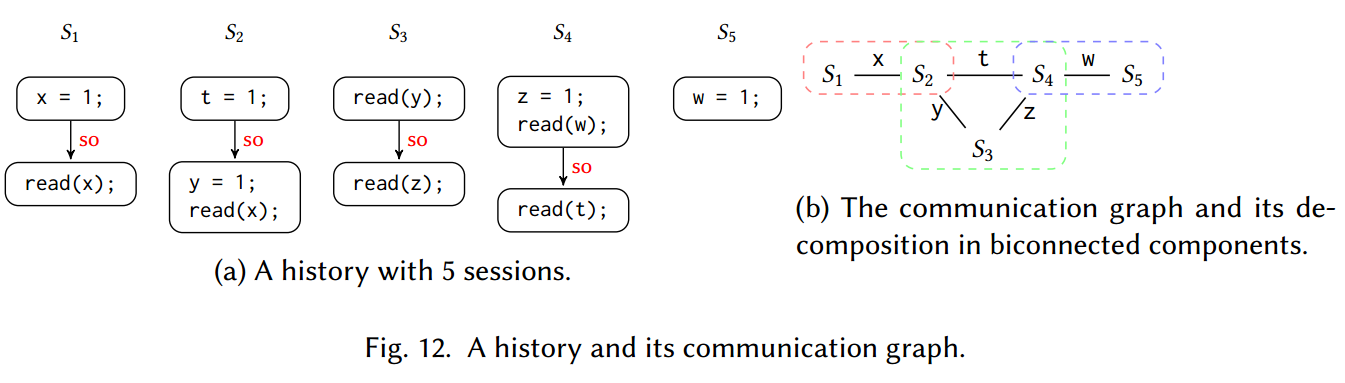
在本节中,我们提出了 PC、SI 和 SER 多项式时间结果的扩展,它允许处理不同会话之间共享变量稀疏的历史。对于本节的结果,我们采取简化的假设,即会话顺序是事务序列的并集(以写入初始值的虚构事务为模),即每个事务序列对应于会话的标准概念。我们使用称为通信图的无向图来表示不同会话之间的变量共享。例如,图 12a 中的历史通信图在图 12b 中给出。为了便于阅读,在边上标记了两个会话访问的变量。
我们证明,当通信图的每个双连通分量的大小受固定常数限制时,检查 PC、SI 或 SER 的问题是多项式时间。这比第 4 节中的结果更强,因为双连通分量的数量可以任意大,这意味着会话总数是无限的。一般来说,我们证明这些一致性标准的时间复杂度仅在此类双连通分量的最大大小中呈指数增长,而不是在会话总数中呈指数增长。
一个无向图是双连通的,意味着它是连通的,并且如果要删除任何一个顶点,该图将保持连通状态,并且图
形式上,历史
我们从一个技术引理开始,表明图中表示历史
给定图
TODO
EXPERIMENTAL EVALUATION
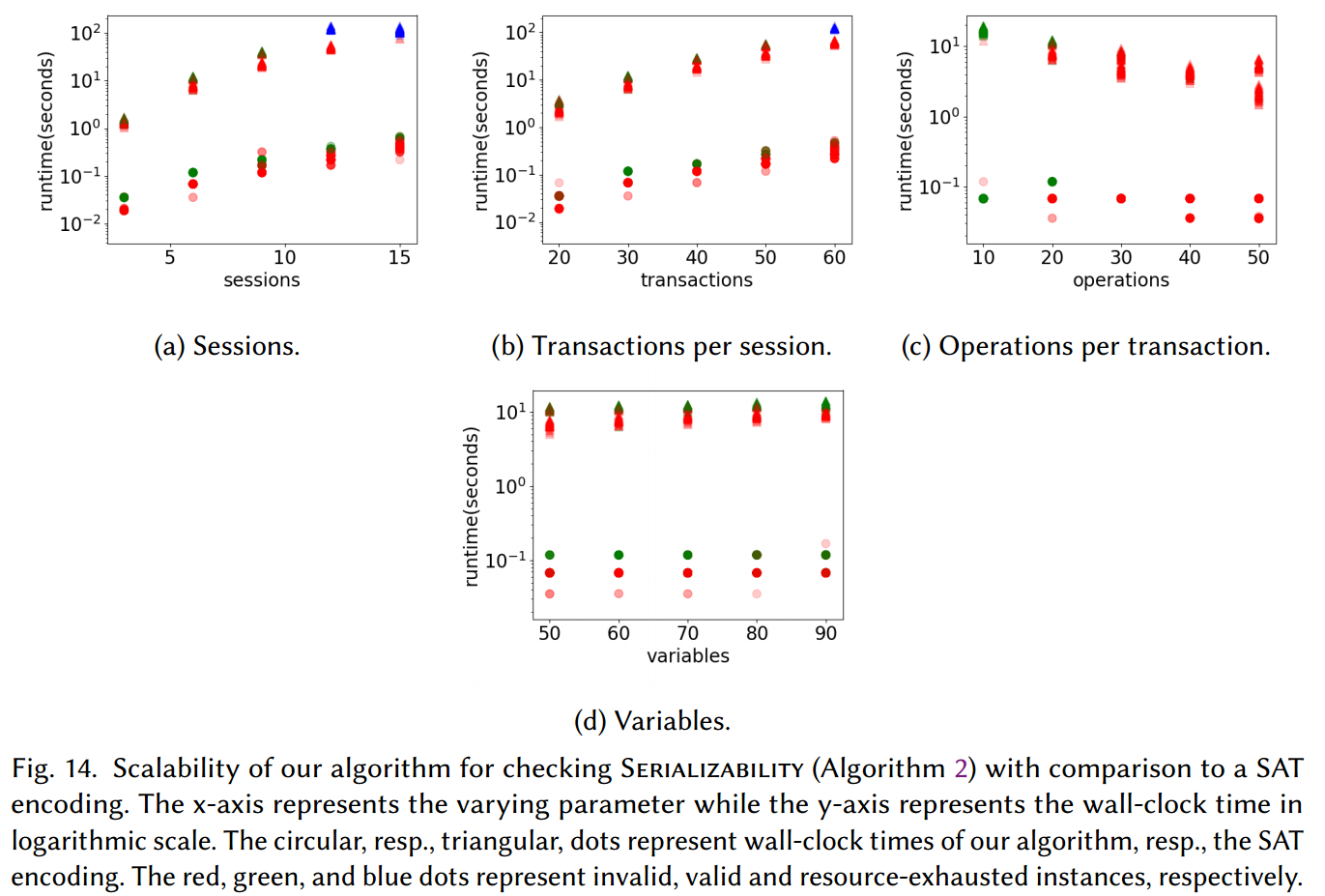
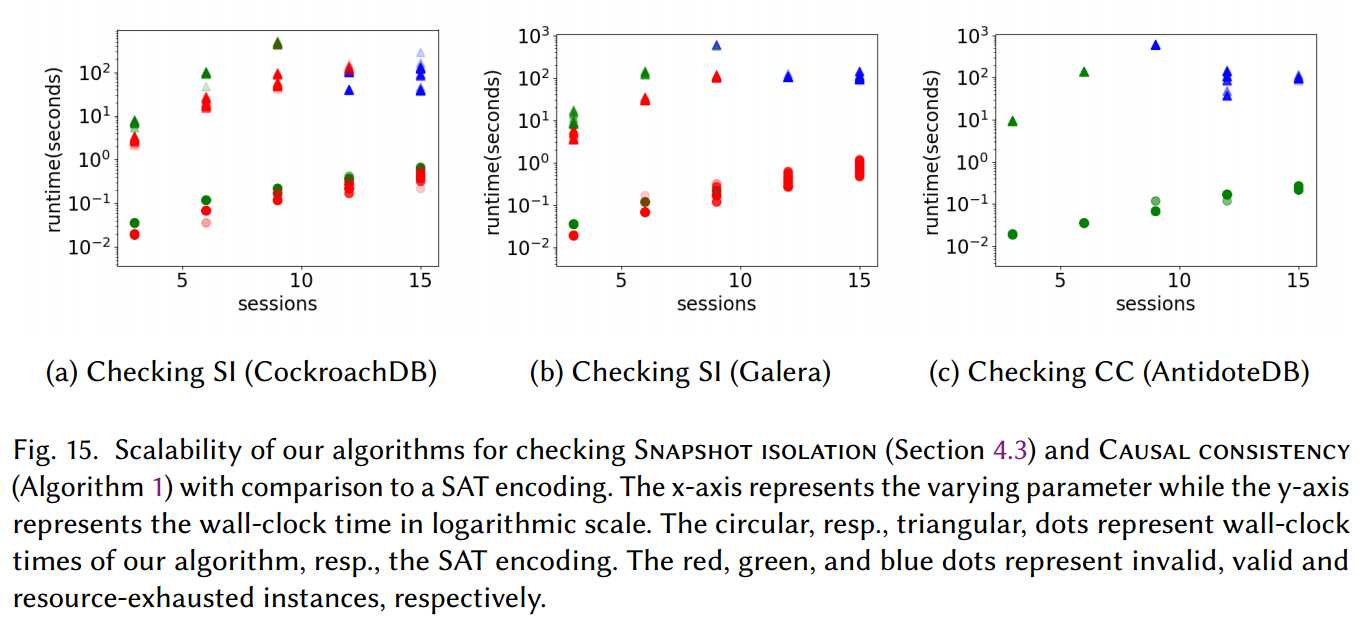
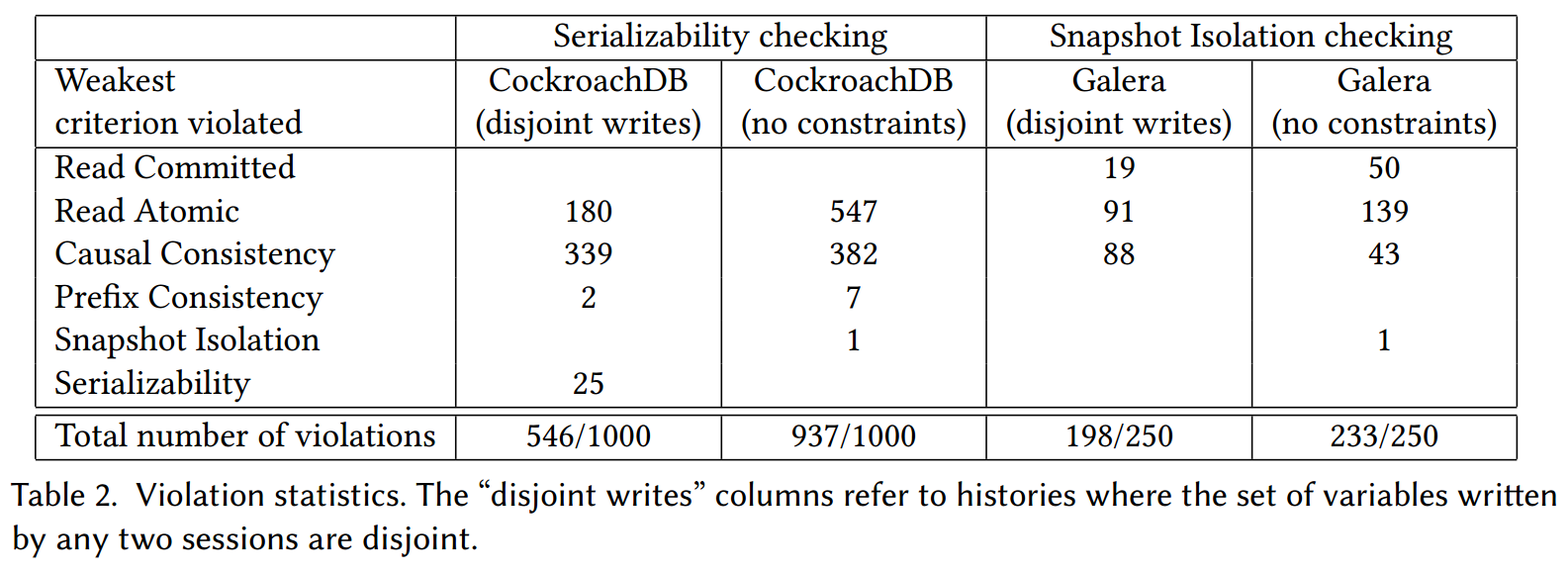
RELATED WORK
Cerone 等人 [2015] 使用 Burckhardt 等人 [2014] 的规范方法,对我们在本文中考虑的标准进行了首次形式化。这种形式化使用两个辅助关系,一个是可见性关系,它表示一个事务“观察”另一个事务的影响,另一个是提交顺序,也称为仲裁顺序,就像我们的例子一样。使用仅包括会话顺序的历史概念来抽象执行,并且对某些一致性标准的遵守被定义为存在可见性关系和满足某些公理的提交顺序。在实际目标的推动下,我们的历史包括写入-读取关系,这使得能够更统一且在我们看来更直观的公理来描述一致性标准。然而,我们的形式化与 Cerone 等人 [2015] 的形式化是等效的(本文的扩展版本中提出了这种等效性的形式证明 [Biswas 和 Enea 2019])。此外,Cerone 等人 [2015] 并没有像我们的论文那样研究算法问题。
Papadimitriou [1979] 表明检查执行的可串行性是 NP 完全的。此外,它还确定了一个更强的标准,称为冲突可串行性,它是多项式时间可检查的。冲突可串行性假设历史作为操作序列给出,并要求提交顺序与基于该序列定义的事务之间的冲突顺序一致(粗略地说,如果事务
Bouajjani 等人[2017] 表明,检查非事务性分布式数据库执行中因果一致性的几种变化需要多项式时间(他们还假设每个值最多写入一次)。假设单例事务,我们的 CC 概念对应于 Bouajjani 等人 [2017] 中的因果收敛标准。因此,我们关于 CC 的结果可以看作是关于因果收敛到事务的结果的延伸。
有一些工作研究了检查共享内存系统中的一致性标准(例如顺序一致性和线性化)的问题。 Gibbons 和 Korach [1997] 表明,检查单值寄存器类型的线性化能力一般来说是 NP 完全的,但执行时需要多项式时间,其中每个值最多写入一次。通过减少可串行性,他们表明即使每个值最多写入一次,检查顺序一致性也是 NP 完全的。 Emmi 和 Enea [2018] 将有关线性化的结果扩展到一系列称为集合的抽象数据类型,其中包括堆栈、队列、键值映射等。顺序一致性简化为具有单例事务的历史的可串行性(即,由单个读或写操作)。因此,我们用于检查有界宽度历史的可串行性的多项式时间结果(推论 4.3)意味着用有界数量的线程检查历史的顺序一致性是多项式时间。后一个结果是由 Abdulla 等人独立建立的[2019]。
通信图的概念受到 Chalupa 等人 [2018] 的工作的启发,该工作研究了多线程程序的偏序约简(POR)技术。一般来说,偏序约简的目标 [Flanagan and Godefroid 2005] 是避免探索对于一些合适的等价概念等价的执行,例如 Mazurkiewicz 迹等价 [Mazurkiewicz 1986]。他们使用通信图的非循环性来定义其 POR 技术最适合的一类程序。他们探索的算法问题与我们的不同,并且他们不像我们的结果那样研究该图的双连通分量。
CONCLUSIONS
我们的结果提供了一种有效的方法,以有效的方式检查事务数据库在广泛的一致性标准方面的正确性。我们为这些标准设计了一个新的规范框架,除了启用有效的验证算法之外,还提供了对它们之间在执行期间读取的事务之前必须提交的事务集方面的差异的新颖理解。这些算法被证明是可扩展的,并且比这些标准的标准 SAT 编码(如我们的框架中定义的)效率高几个数量级。虽然这些算法非常容易理解和实现,但其正确性的证明并非易事,并且可以从新的规范框架中受益匪浅。
未来工作的一个重要场所是确定特定违规行为的根本原因。事实上,我们能够处理广泛的标准,这已经有助于识别给定执行中违反的最弱标准。然后,在 RC、RA 和 CC 的情况下,不一致对应于提交顺序中的周期,根本原因可以归因于这种关系中的最小周期。我们在与 Antidote 开发人员的沟通中这样做是为了简化我们发现的包含 42 笔事务的违规行为。在 PC、SI 和 SER 的情况下,可以在 SAT 求解器中实现类似于 CDCL 的搜索过程,以便计算根本原因,因为 SAT 求解器将计算不可满足性核心。

