状态模式
模式动机
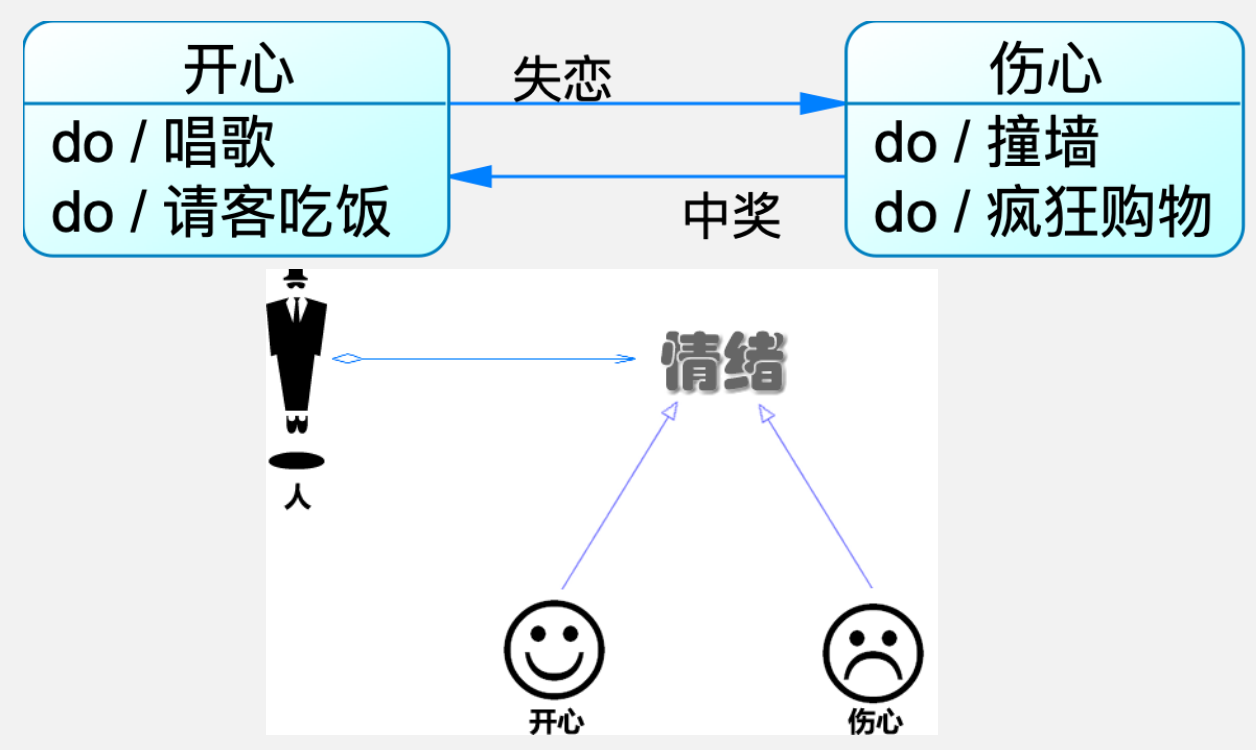
- 在很多情况下,一个对象的行为取决于一个或多个动态变化的属性,这样的属性叫做状态,这样的对象叫做有状态的(stateful)对象,这样的对象状态是从事先定义好的一系列值中取出的。当一个这样的对象与外部事件产生互动时,其内部状态就会改变,从而使得系统的行为也随之发生变化。
- 在 UML 中可以使用状态图来描述对象状态的变化。
垄断使生产接近最全面的社会化。具体表现在:
原文:中华人民共和国国史学会出版《毛泽东读社会主义政治经济学批注和谈话》(1998 年)
苏联《政治经济学教科书》原文:
由于社会主义革命的胜利,中国生产力发展道路上的一切障碍基本上扫除了。社会主义改造完成以后,在中国产生了先进的社会制度和落后的社会生产力之间的矛盾。在当前条件下,中国人民正集中全力解决这个矛盾,以便尽快地把中国由落后的农业国变成先进的工业国。任务是在 10 年至 15 年内,把中国变成拥有现代工业、现代农业和现代科学文化的强大的社会主义国家。
在中国的特殊条件下,社会主义能在国家工业化实现以前,就在所有制方面(包括农村在内)取得胜利,是因为有强大的社会主义阵营存在,有苏联这样高度发展的工业国家的援助。
无论是在现实世界中还是在软件系统中,都存在一些复杂的对象,它们拥有多个组成部分,如汽车,它包括车轮、方向盘、发送机等各种部件。而对于大多数用户而言,无须知道这些部件的装配细节,也几乎不会使用单独某个部件,而是使用一辆完整的汽车,可以通过建造者模式对其进行设计与描述,建造者模式可以将部件和其组装过程分开,一步一步创建一个复杂的对象。用户只需要指定复杂对象的类型就可以得到该对象,而无须知道其内部的具体构造细节。
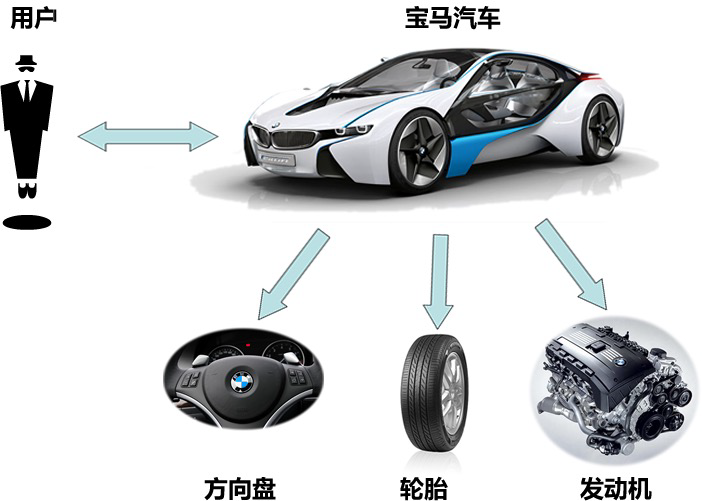
在软件开发中,也存在大量类似汽车一样的复杂对象,它们拥有一系列成员属性,这些成员属性中有些是引用类型的成员对象。而且在这些复杂对象中,还可能存在一些限制条件,如某些属性没有赋值则复杂对象不能作为一个完整的产品使用;有些属性的赋值必须按照某个顺序,一个属性没有赋值之前,另一个属性可能无法赋值等。
摘要
列宁认为对立统一规律是辩证法的实质和核心,恩格斯认为“否定的否定”是事物发展全过程的核心。前者是就对立统一规律在整个辩证法理论体系中的地位而言的,后者是就事物发展全过程中的第二次否定、第三个阶段(即“否定的否定”)在否定之否定规律中的地位而言的。列宁的思想与恩格斯的思想是从不同角度、不同层次对辩证法理论体系中不同组成部分的地位和作用所做的判断,二者的作用是互相补充的, 而不是互相排斥的。不能用肯定和否定的不断交替代替否定之否定规律,因为肯定和否定的不断交替不能说明事物自己发展自己、自己完善自己的过程;对立统一规律和质量互变规律不能说明事物发展的周期性和全过程,不能说明发展是“在高级阶段重复低级阶段的某些特征、特性”,并且“仿佛是向旧东西的复归”,只有否定之否定规律才能说明事物发展的这种特点;要从否定之否定规律的普遍性和特殊性的统一,说明掌握事物发展全过程的周期性应该坚持的正确方法。
关键词:否定的否定; 对立统一规律; 质量互变规律; 否定之否定规律
唯物辩证法有三个基本规律,即对立统一规律、质量互变规律和否定之否定规律。对立统一规律是关于事物矛盾运动的规律,它揭示了事物发展的实质及其内在源泉和动力,是唯物辩证法的实质和核心;质量互变规律是关于事物量变和质变的相互过渡、相互交替的规律,它揭示了事物发展中相对静止和显著变动的两种状态及其相互关系;否定之否定规律则是事物自身所包含的否定因素(方面、趋势)所引起的事物由肯定到否定再到否定的否定的发展过程,它揭示了事物发展全过程的周期性,指明了事物自己发展自己、自己完善自己的总趋势,与前两个规律相比较,它具有更大的整体性和总括性。在现实中,辩证法的三个基本规律相互联系、相互补充,共同推动事物的发展,否定之否定规律所起的作用,是其他两个规律所不能代替的。
SentiStrength is a sentiment analysis tool developed by Mike Thelwall etc [^1] in 2010. In this manual, we will first briefly introduce this tool, describe its functions, and show how to use this tool. More details can be found in its paper and SentiStrength's official website [^2].
SentiStrength 是 Mike Thelwall 等 [^1] 于 2010 年开发的情感分析工具。在本手册中,我们将首先简要介绍该工具,描述其功能,并展示如何使用该工具。更多详细信息可以在其论文和 SentiStrength 的官方网站 [^2] 中找到。
SentiStrength is a tool developed from comments on social networking sites (MySpace [^3]). Its core function is to use dictionary-based algorithms to analyse sentiment for text. Specifically, it first assigns priori sentimental scores to words according to the sentiment dictionary, and then adjusts the assignation result with several heuristic rules. It can give a sentimental score pair $(\rho, \eta)$ for each input text, where $\rho$ represents the positive score of the text, and $\eta$ represents the negative score. The scale and meaning for $\rho$ and $\eta$ are as below:
SentiStrength 是一种根据社交网站(MySpace [^3])上的评论开发的工具。它的核心功能是使用基于字典的算法来分析文本的情感。具体来说,它首先根据情感词典为单词分配先验情感分数,然后使用多种启发式规则调整分配结果。它可以为每个输入文本给出一个情感分数对 $(\rho, \eta)$,其中 $\rho$ 表示文本的正面分数,$\eta$ 表示负面分数。$\rho$ 和 $\eta$ 的尺度和含义如下:
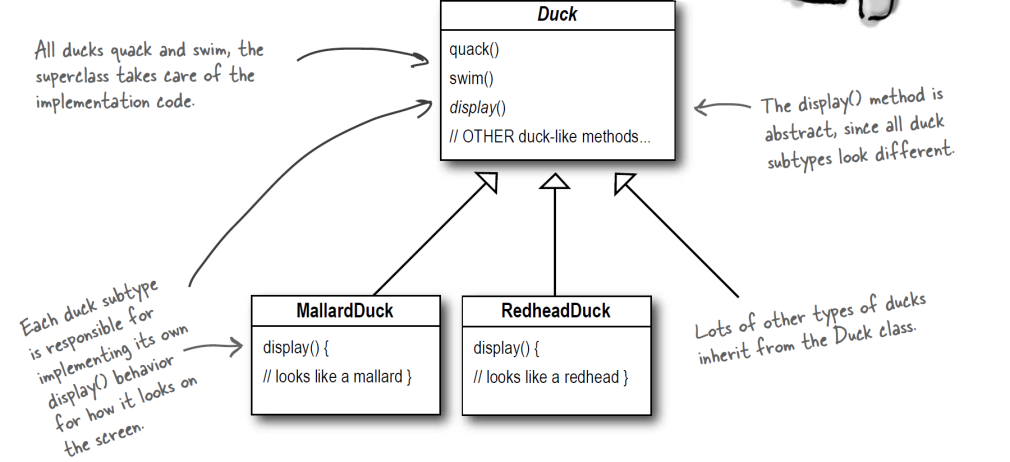
设计背景:考虑一个简单的软件应用场景,一个软件系统可以提供多个外观不同的按钮(如圆形按钮、矩形按钮、菱形按钮等),这些按钮都源自同一个基类,不过在继承基类后不同的子类修改了部分属性从而使得它们可以呈现不同的外观,如果我们希望在使用这些按钮时,不需要知道这些具体按钮类的名字,只需要知道表示该按钮类的一个参数,并提供一个调用方便的方法,把该参数传入方法即可返回一个相应的按钮对象,此时,就可以使用简单工厂模式。
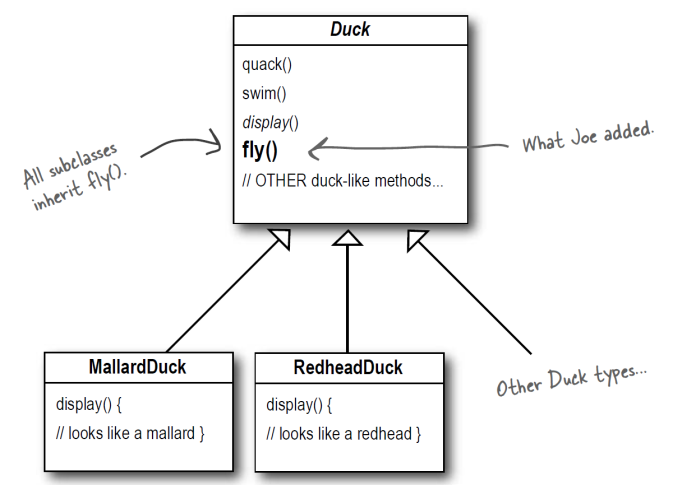
我们需要添加功能使得鸭子可以飞
摘要
本文指出了读写问题中传统半读者优先算法的局限性,并设计了新的全读者优先算法,在不抢占资源的情况下将读者的优先级提高到了理论最高优先级。本文对全读者优先算法进行了实验验证。
对读者写者问题的描述参见:计算机与操作系统-06-并发程序设计:7.2 读者/写者问题。
**当居于统治地位的封建贵族的疯狂争斗的喧叫充塞着中世纪的时候,被压迫阶级的静悄悄的劳动却在破坏着整个西欧的封建制度,创造着使封建主的地位日益削弱的条件。**固然,在农村里贵族老爷们还是作威作福,折磨农奴,靠他们的血汗过着奢侈生活,骑马践踏他们的庄稼,强奸他们的妻女。但是,周围已经兴起了城市:在意大利、法国南部和莱茵河畔,古罗马的自治市从灰烬中复活了;在其他地方,特别在德意志内部,兴建着新的城市,这些城市总是用护城墙和护城壕围绕着,只有用大量军队才能攻下,因此是比贵族的城堡强大得多的要塞。在这些城墙和城壕的后面,发展了中世纪的手工业(十足市民行会的和小的),积累起最初的资本,产生了城市相互之间和城市与外界之间商业来往的需要,而与这种需要同时,也逐渐产生了保护商业来往的手段。
从今天的观点来看,生产和交换的这一切进步其实是很受限制的。生产仍然被纯粹行会手工业的形式束缚着,因而本身还保持着封建的性质。贸易仍然处于欧洲水域之内,并且没有超出欧洲和远东国家交换产品的列万特沿海城市以外。但是不管手工业及其市民手工业者多么微小,多么受限制,他们还是有足够的力量来推翻封建社会;他们至少是在前进,而贵族却是停滞不动的。
- 核心观点:农奴的劳动作为旧制度的否定因素,破坏着贵族的剥削条件;
- 中世纪的城市保护着手工业,产生了商业的需要,并且产生了保护商业的手段,在城市当中积累了最初的资本;
- 手工业者是前进的,而贵族是停滞不前的,即反动的。