基于广告的免费商业模式总结
好的产品和服务以及高流量会吸引广告商,进而补贴产品和服务
- 要考虑广告费能否支撑起产品服务质量
- 吞噬广告费的产品太多,流量红利已见底
成本:平台的开发和维护,以及可能的获客与维系成本
好的产品和服务以及高流量会吸引广告商,进而补贴产品和服务
成本:平台的开发和维护,以及可能的获客与维系成本
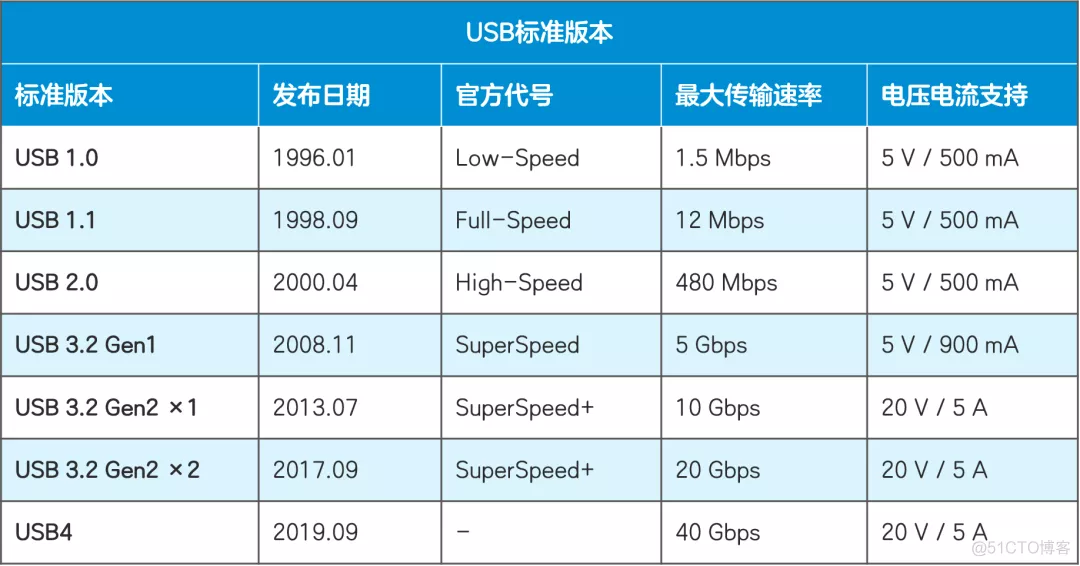
通用串行总线(英语:Universal Serial Bus,缩写:USB)是连接计算机系统与外部设备的一种串口总线标准,也是一种输入输出接口的技术规范,被广泛地应用于个人电脑和移动设备等信息通讯产品,并扩展至摄影器材、数字电视(机顶盒)、游戏机等其它相关领域。


看到《雨把烟打湿了》这个题目,便油然联想到范仲庵的名句“波上寒烟翠”。那是一首写乡思别愁的《苏幕遮》,所以我一开始就不由得把这篇小说往“别愁”方面理解。我想,恐怕没有人会从侦探小说或法制文学的角度来看待该作品。大概右派的评论家会从心理学角度批判主人公不懂自由的真谛,以致严重地漠视了人权;而左派的评论家则很可能一针见血地指出,这就是阶级斗争,这是一个被资产阶级征服过的贫苦农民,最终又走向反杭、走向毁灭的悲剧。我不想预先重复左派右派的高论,我只是一个未名湖畔吟风弄月的封建士大夫,所以我只想从真实的审美感受出发,随便说说我被这篇小说打湿了的心情。
小说的主人公蔡水清,令人过目难忘。这个形象使我想起许多自己的同学、学弟和学生。他们出身于贫困的农村,依靠悬梁刺股的寒窗苦读进入了大学,也就是获得了“文明世界”的入场券。在和平年代,高考几乎是我们中国穷人翻身的唯一的独木桥。然而,20 世纪 90 年代教育日益产业化以来,穷人过桥的困难大幅度增加了,工农子弟在大学里遭受的歧视也大幅度增长了,“文明”的压力,迫使他们要向城市投降,向大款和小资投降,向抽水马捅、按摩浴缸和“清断爽洁不紧绷”的卫生巾投降。“文革”后期的著名电影《决裂》中有个情节,母亲从农村来到大学里看儿子,儿子说母亲为他做的鞋“太土气了”,母亲则伤心地说:“孩子,你变啦!又干又瘦,还戴上了眼镜!”而今天的大多数农村父母,已经没有经济能力到大学里看儿子,也根本不敢再为儿子做那丢人现眼的土鞋。他们卖屋卖牛卖鲜血,供养儿子在大学里过着城市子弟的生活,也不敢希求儿子毕业后每年寄回个三百两百的,他们只是跟乡邻们说一声:“我儿子在城里上大学,”就心满意足了。那些来自农村的子弟毕业后,有的吃水不忘挖井人,一直与生养自己的乡土保持着血肉联系,有的对家乡父老采取“哀其不幸,怒其不争”的启蒙姿态,有的则根本断绝了与那野蛮愚昧之地的音讯。
然而,小说写道:“他不知道为什么经常有一种惆怅的感觉劈头盖脸地打来。它甚至不是非物质性的,他能清晰地感觉到这种东西的性状,包括气味、颜色、质地,可是,他表达不出它任何一种的物质特性。”蔡水清同学,你知道吗?这就是范仲淹那首《苏幕遮》里说的“黯乡魂,追旅思,夜夜除非,好梦留人睡。”蔡水清以为自己是城里人了,他出于对自己老家的自卑,骗妻子说老家的屋子“闹鬼”,实际上是他自己的灵魂在“闹鬼”。他真的喜欢这个“城里人”的自己吗?他真的爱妻子钱红吗?“钱红是个安静和顺的女人,一种脱俗的气质,使她普通的身材和容貌有一种干净的魅力。”蔡水清爱的实际是钱红所代表的一种所谓“干净的魅力”,而所谓“干净”,在当今世界的语境中,说穿了就是“远离土地”的同义语。当蔡水清终于选择放弃这个世界时,他“无论在上庭、还是被法警带下法庭,都没怎么看妻子,更别提他的舅子、姨子们。他什么人都不看。整个案件审理过程中,他只是时不时看着窗外,目光模糊。”蔡水清对钱家人根本就无所谓爱不爱,钱家人在他的眼中,还不如窗外的那缕寒烟。
而当“母亲去世的时候,赶回家乡的蔡水清嚎啕大哭,不断以头撞墙。以至哥嫂们姐妹们认为他在演戏。”读到这里,我眼前叠印出鲁迅《孤独者》中魏连殳的形象。魏连殳到底孝顺不孝顺,乡里人是不理解的。蔡水清的表现虽然跟魏连殳不同,但同样不被家乡人理解。“后来看到蔡水清一下掏出 5000 元,兄弟姐妹才放弃评论。可是,有一个厉害的嫂嫂还是觉得他这人没意思:人活着不孝敬,死了做给谁看。是啊,蔡水清自从上了大学,就好像背叛了家乡。甚至很少寄钱,过年总不回家,寄个两百三百的就完事了,可是,他母亲一直非常为他骄傲。”蔡水清跟魏连殳一样,其实是“孤独者”。他们“像一匹受伤的狼,当深夜在旷野中嗥叫,惨伤里夹杂看愤怒和悲哀。”被城里人认作“粗鄙”、认作“丑恶”的蔡水清,如何在城里生存下去,又如何能够成为享受政府特殊津贴的人才呢?他只有像魏连殳那般,“躬行我先前所僧恶,所反对的一切,拒斥我先前所崇仰,所主张的一切了。我已经真的失败——然而我胜利了。”蔡水清大学时代,曾经:“恃才自傲得很,一年级后,不知受哪些艺术家影响,他就把他那头非洲雄狮一样的头发,留长,强硬梳成兔尾巴头,有时扮酷,不扎,蓬乱如炸方便面的长发,更是粗鄙得像在工地挖沟的民工,笨重的脑袋下,你根本找不到脖子。”
然而,大雨之夜,被文明折磨得奄奄一息的城里人蔡水清,忽然在粗俗的出租车司机脸上认出了自己。两个自己,只能活着一个,于是,他拿出了最文明的凶器——德国出产的价位六百多元的刀。多美的刀啊,美得简直是“波上寒烟翠”。小说结尾,蔡水清粉碎了一切要为他开脱罪责的图谋,理性无比地选择了死刑。他委婉地留下两个破解他生命之迷的符码,“一个是骊歌,一个是丁忧。我不懂它们的意思。很久了。”**骊歌是离恨别愁之歌,丁忧是父母丧亡之痛。**蔡水清终于明白,“乡下人蔡水清”是杀不死的。他一直对家乡满怀着乡愁,他一直对母亲满怀着敬爱。那次母亲因做饭油烟太大而引发钱红母子的不快后,蔡水清一面委婉地责备了母亲,一面却“一直接着母亲肩膀”。谁能知道蔡水清的内心究竟是被什么打湿的呢?
从第二审判庭偏高的窗口,望出去是林德叉车厂的办公楼外长走廊的一角。透过长走廊钢筋护栏,就可以看到更远的、不知哪家的红砖烟囱在冒烟。青烟不大不小地冒出来,雨不大不小地打在它们上面,但烟还是轻轻地腾起。看是看不清楚,但烟肯定都湿了。
审判长说,被告人,请做最后陈述。
被告人在看着第二审判庭偏高的窗口。法庭上很安静。检察官在偷偷嚼口香糖。辩护席上,律师和助理都看着他们的委托人。助理忍不住对被告人轻轻“喂!”了一声,他们的委托人收回了看窗外的眼光。最后陈述!助理抻着脖子低声提醒。
被告人声音很轻:雨把烟打湿了。
审判长说,大声点!不是嘴巴说给鼻子听!
互联网与万维网有何不同?
全栈式:
性能优化:
“(讨论)建筑风格的意义在于捕获建筑设计的理念,将其作为典型的、可重复使用的描述”
本课程关注的五类商业模式
本文主要内容来自 SpriCoder的博客,更换了更清晰的图片并对原文的疏漏做了补充和修正。
本文提供了 pdf 版,以供打印:商务智能-01-商务智能.pdf。
本文主要内容来自 SpriCoder的博客,更换了更清晰的图片并对原文的疏漏做了补充和修正。
本文提供了 pdf 版,以供打印:商务智能-02-数据仓库.pdf。
 |
 |
|---|
Donald E. Knuth (1938~), the "father of the analysis of algorithm", Turing Award, 1974
For his major contributions to the analysis of algorithms and the design of programming languages, and in particular for his contributions to the "Art of Computer Programming" through his well-known books in a continuous series by this title.